 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception Tokens Enhance Visual Reasoning in Multimodal Language Models
Dec 04, 2024Multimodal language models (MLMs) still face challenges in fundamental visual perception tasks where specialized models excel. Tasks requiring reasoning about 3D structures benefit from depth estimation, and reasoning about 2D object instances benefits from object detection. Yet, MLMs can not produce intermediate depth or boxes to reason over. Finetuning MLMs on relevant data doesn't generalize well and outsourcing computation to specialized vision tools is too compute-intensive and memory-inefficient. To address this, we introduce Perception Tokens, intrinsic image representations designed to assist reasoning tasks where language is insufficient. Perception tokens act as auxiliary reasoning tokens, akin to chain-of-thought prompts in language models. For example, in a depth-related task, an MLM augmented with perception tokens can reason by generating a depth map as tokens, enabling it to solve the problem effectively. We propose AURORA, a training method that augments MLMs with perception tokens for improved reasoning over visual inputs. AURORA leverages a VQVAE to transform intermediate image representations, such as depth maps into a tokenized format and bounding box tokens, which is then used in a multi-task training framework. AURORA achieves notable improvements across counting benchmarks: +10.8% on BLINK, +11.3% on CVBench, and +8.3% on SEED-Bench, outperforming finetuning approaches in generalization across datasets. It also improves on relative depth: over +6% on BLINK. With perception tokens, AURORA expands the scope of MLMs beyond language-based reasoning, paving the way for more effective visual reasoning capabilities.
OCTCube: A 3D foundation model for optical coherence tomography that improves cross-dataset, cross-disease, cross-device and cross-modality analysis
Aug 20, 2024Optical coherence tomography (OCT) has become critical for diagnosing retinal diseases as it enables 3D images of the retina and optic nerve. OCT acquisition is fast, non-invasive, affordable, and scalable. Due to its broad applicability, massive numbers of OCT images have been accumulated in routine exams, making it possible to train large-scale foundation models that can generalize to various diagnostic tasks using OCT images. Nevertheless, existing foundation models for OCT only consider 2D image slices, overlooking the rich 3D structure. Here, we present OCTCube, a 3D foundation model pre-trained on 26,605 3D OCT volumes encompassing 1.62 million 2D OCT images. OCTCube is developed based on 3D masked autoencoders and exploits FlashAttention to reduce the larger GPU memory usage caused by modeling 3D volumes. OCTCube outperforms 2D models when predicting 8 retinal diseases in both inductive and cross-dataset settings, indicating that utilizing the 3D structure in the model instead of 2D data results in significant improvement. OCTCube further shows superior performance on cross-device prediction and when predicting systemic diseases, such as diabetes and hypertension, further demonstrating its strong generalizability. Finally, we propose a contrastive-self-supervised-learning-based OCT-IR pre-training framework (COIP) for cross-modality analysis on OCT and infrared retinal (IR) images, where the OCT volumes are embedded using OCTCube. We demonstrate that COIP enables accurate alignment between OCT and IR en face images. Collectively, OCTCube, a 3D OCT foundation model, demonstrates significantly better performance against 2D models on 27 out of 29 tasks and comparable performance on the other two tasks, paving the way for AI-based retinal disease diagnosis.
Semantics-Aware Attention Guidance for Diagnosing Whole Slide Images
Apr 16, 2024
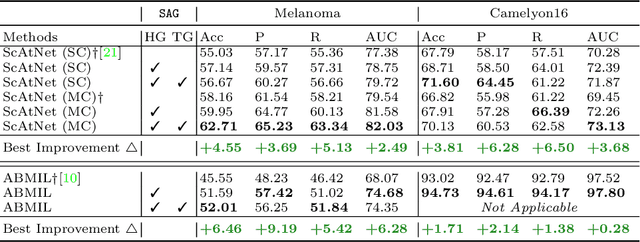


Accurate cancer diagnosis remains a critical challenge in digital pathology, largely due to the gigapixel size and complex spatial relationships present in whole slide images. Traditional multiple instance learning (MIL) methods often struggle with these intricacies, especially in preserving the necessary context for accurate diagnosis. In response, we introduce a novel framework named Semantics-Aware Attention Guidance (SAG), which includes 1) a technique for converting diagnostically relevant entities into attention signals, and 2) a flexible attention loss that efficiently integrates various semantically significant information, such as tissue anatomy and cancerous regions. Our experiments on two distinct cancer datasets demonstrate consistent improvements in accuracy, precision, and recall with two state-of-the-art baseline models. Qualitative analysis further reveals that the incorporation of heuristic guidance enables the model to focus on regions critical for diagnosis. SAG is not only effective for the models discussed here, but its adaptability extends to any attention-based diagnostic model. This opens up exciting possibilities for further improving the accuracy and efficiency of cancer diagnostics.
MIMIC: Masked Image Modeling with Image Correspondences
Jun 28, 2023Many pixelwise dense prediction tasks-depth estimation and semantic segmentation in computer vision today rely on pretrained image representations. Therefore, curating effective pretraining datasets is vital. Unfortunately, the effective pretraining datasets are those with multi-view scenes and have only been curated using annotated 3D meshes, point clouds, and camera parameters from simulated environments. We propose a dataset-curation mechanism that does not require any annotations. We mine two datasets: MIMIC-1M with 1.3M and MIMIC-3M with 3.1M multi-view image pairs from open-sourced video datasets and from synthetic 3D environments. We train multiple self-supervised models with different masked image modeling objectives to showcase the following findings: Representations trained on MIMIC-3M outperform those mined using annotations on multiple downstream tasks, including depth estimation, semantic segmentation, surface normals, and pose estimation. They also outperform representations that are frozen and when downstream training data is limited to few-shot. Larger dataset (MIMIC-3M) significantly improves performance, which is promising since our curation method can arbitrarily scale to produce even larger datasets. MIMIC code, dataset, and pretrained models are open-sourced at https://github.com/RAIVNLab/MIMIC.
Classifying Breast Histopathology Images with a Ductal Instance-Oriented Pipeline
Dec 11, 2020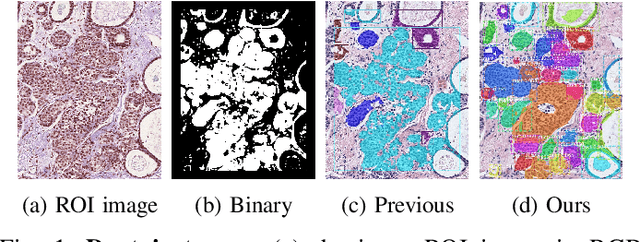
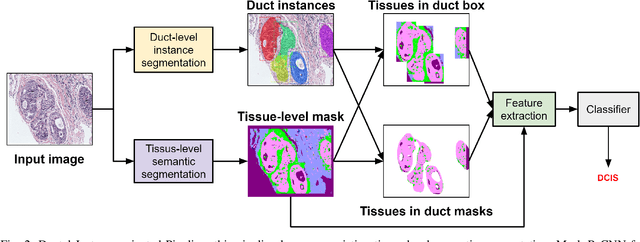
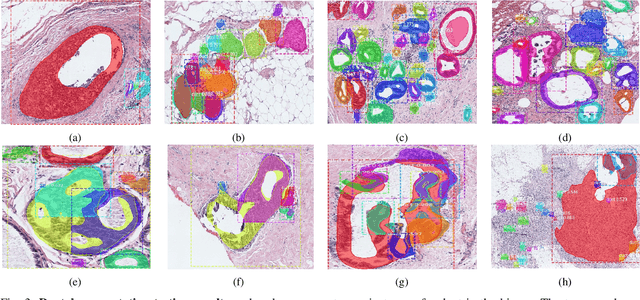
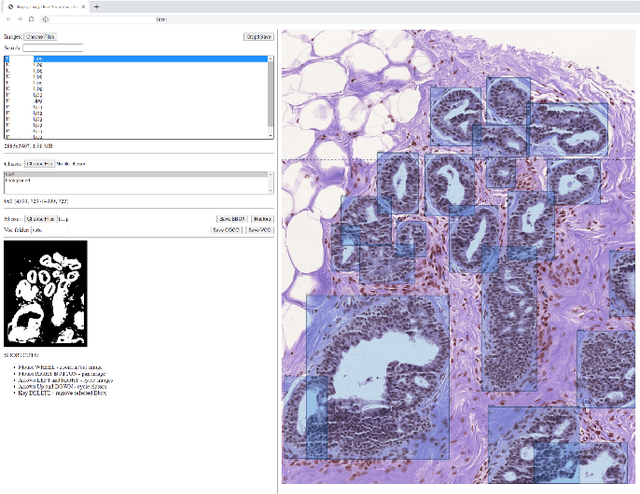
In this study, we propose the Ductal Instance-Oriented Pipeline (DIOP) that contains a duct-level instance segmentation model, a tissue-level semantic segmentation model, and three-levels of features for diagnostic classification. Based on recent advancements in instance segmentation and the Mask R-CNN model, our duct-level segmenter tries to identify each ductal individual inside a microscopic image; then, it extracts tissue-level information from the identified ductal instances. Leveraging three levels of information obtained from these ductal instances and also the histopathology image, the proposed DIOP outperforms previous approaches (both feature-based and CNN-based) in all diagnostic tasks; for the four-way classification task, the DIOP achieves comparable performance to general pathologists in this unique dataset. The proposed DIOP only takes a few seconds to run in the inference time, which could be used interactively on most modern computers. More clinical explorations are needed to study the robustness and generalizability of this system in the future.
Video to Fully Automatic 3D Hair Model
Sep 13, 2018
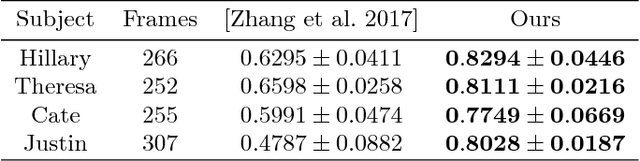

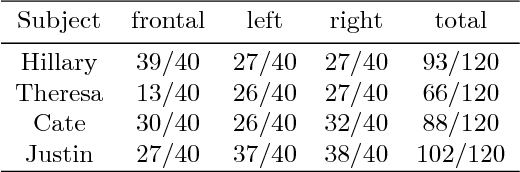
Imagine taking a selfie video with your mobile phone and getting as output a 3D model of your head (face and 3D hair strands) that can be later used in VR, AR, and any other domain. State of the art hair reconstruction methods allow either a single photo (thus compromising 3D quality) or multiple views, but they require manual user interaction (manual hair segmentation and capture of fixed camera views that span full 360 degree). In this paper, we describe a system that can completely automatically create a reconstruction from any video (even a selfie video), and we don't require specific views, since taking your -90 degree, 90 degree, and full back views is not feasible in a selfie capture. In the core of our system, in addition to the automatization components, hair strands are estimated and deformed in 3D (rather than 2D as in state of the art) thus enabling superior results. We provide qualitative, quantitative, and Mechanical Turk human studies that support the proposed system, and show results on a diverse variety of videos (8 different celebrity videos, 9 selfie mobile videos, spanning age, gender, hair length, type, and styling).
3D Face Hallucination from a Single Depth Frame
Sep 13, 2018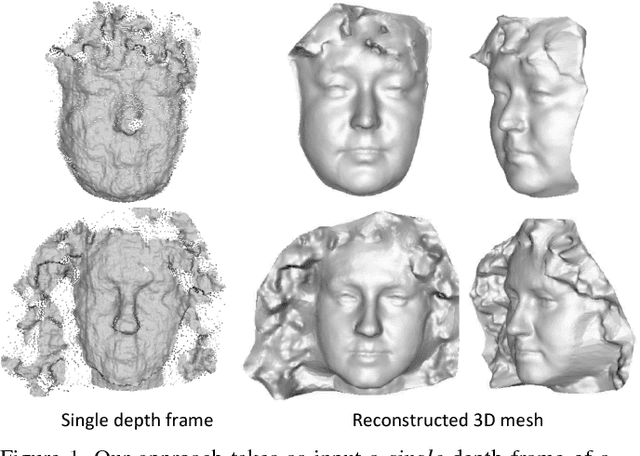
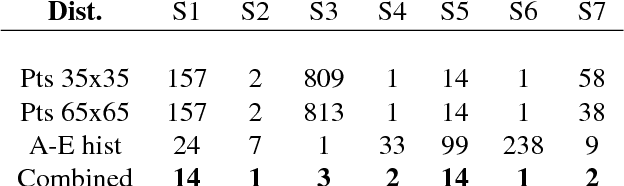

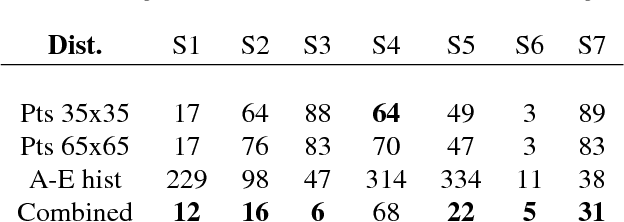
We present an algorithm that takes a single frame of a person's face from a depth camera, e.g., Kinect, and produces a high-resolution 3D mesh of the input face. We leverage a dataset of 3D face meshes of 1204 distinct individuals ranging from age 3 to 40, captured in a neutral expression. We divide the input depth frame into semantically significant regions (eyes, nose, mouth, cheeks) and search the database for the best matching shape per region. We further combine the input depth frame with the matched database shapes into a single mesh that results in a high-resolution shape of the input person. Our system is fully automatic and uses only depth data for matching, making it invariant to imaging conditions. We evaluate our results using ground truth shapes, as well as compare to state-of-the-art shape estimation methods. We demonstrate the robustness of our local matching approach with high-quality reconstruction of faces that fall outside of the dataset span, e.g., faces older than 40 years old, facial expressions, and different ethnicities.
Head Reconstruction from Internet Photos
Sep 13, 2018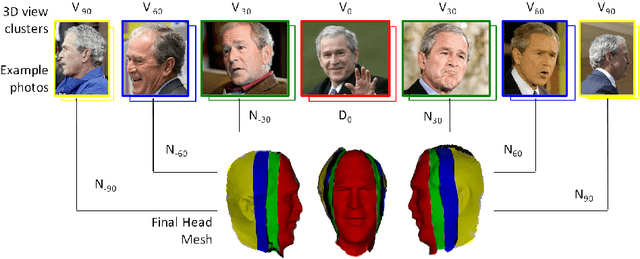
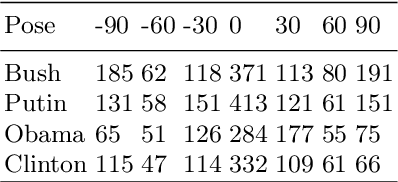


3D face reconstruction from Internet photos has recently produced exciting results. A person's face, e.g., Tom Hanks, can be modeled and animated in 3D from a completely uncalibrated photo collection. Most methods, however, focus solely on face area and mask out the rest of the head. This paper proposes that head modeling from the Internet is a problem we can solve. We target reconstruction of the rough shape of the head. Our method is to gradually "grow" the head mesh starting from the frontal face and extending to the rest of views using photometric stereo constraints. We call our method boundary-value growing algorithm. Results on photos of celebrities downloaded from the Internet are presented.