 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuFeng-XGuard: A Reasoning-Centric, Interpretable, and Flexible Guardrail Model for Large Language Models
Jan 22, 2026As large language models (LLMs) are increasingly deployed in real-world applications, safety guardrails are required to go beyond coarse-grained filtering and support fine-grained, interpretable, and adaptable risk assessment. However, existing solutions often rely on rapid classification schemes or post-hoc rules, resulting in limited transparency, inflexible policies, or prohibitive inference costs. To this end, we present YuFeng-XGuard, a reasoning-centric guardrail model family designed to perform multi-dimensional risk perception for LLM interactions. Instead of producing opaque binary judgments, YuFeng-XGuard generates structured risk predictions, including explicit risk categories and configurable confidence scores, accompanied by natural language explanations that expose the underlying reasoning process. This formulation enables safety decisions that are both actionable and interpretable. To balance decision latency and explanatory depth, we adopt a tiered inference paradigm that performs an initial risk decision based on the first decoded token, while preserving ondemand explanatory reasoning when required. In addition, we introduce a dynamic policy mechanism that decouples risk perception from policy enforcement, allowing safety policies to be adjusted without model retraining. Extensive experiments on a diverse set of public safety benchmarks demonstrate that YuFeng-XGuard achieves stateof-the-art performance while maintaining strong efficiency-efficacy trade-offs. We release YuFeng-XGuard as an open model family, including both a full-capacity variant and a lightweight version, to support a wide range of deployment scenarios.
GaussianMarker: Uncertainty-Aware Copyright Protection of 3D Gaussian Splatting
Oct 31, 2024



3D Gaussian Splatting (3DGS) has become a crucial method for acquiring 3D assets. To protect the copyright of these assets, digital watermarking techniques can be applied to embed ownership information discreetly within 3DGS models. However, existing watermarking methods for meshes, point clouds, and implicit radiance fields cannot be directly applied to 3DGS models, as 3DGS models use explicit 3D Gaussians with distinct structures and do not rely on neural networks. Naively embedding the watermark on a pre-trained 3DGS can cause obvious distortion in rendered images. In our work, we propose an uncertainty-based method that constrains the perturbation of model parameters to achieve invisible watermarking for 3DGS. At the message decoding stage, the copyright messages can be reliably extracted from both 3D Gaussians and 2D rendered images even under various forms of 3D and 2D distortions. We conduct extensive experiments on the Blender, LLFF and MipNeRF-360 datasets to validate the effectiveness of our proposed method, demonstrating state-of-the-art performance on both message decoding accuracy and view synthesis quality.
GeometrySticker: Enabling Ownership Claim of Recolorized Neural Radiance Fields
Jul 18, 2024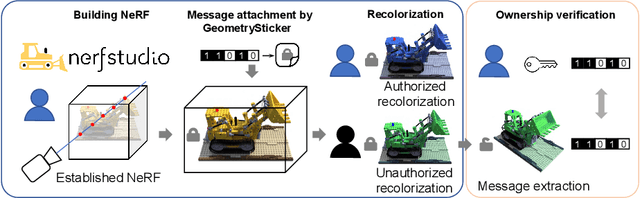

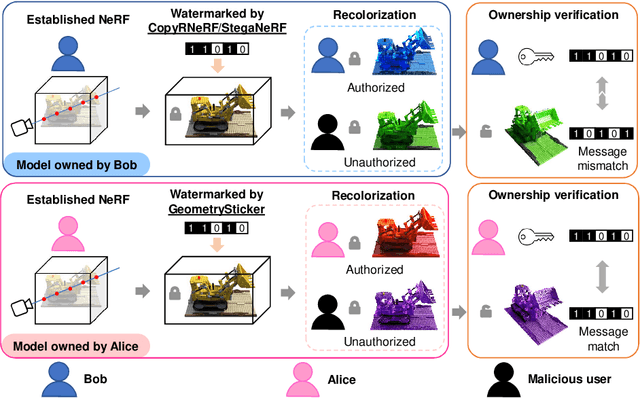

Remarkable advancements in the recolorization of Neural Radiance Fields (NeRF) have simplified the process of modifying NeRF's color attributes. Yet, with the potential of NeRF to serve as shareable digital assets, there's a concern that malicious users might alter the color of NeRF models and falsely claim the recolorized version as their own. To safeguard against such breaches of ownership, enabling original NeRF creators to establish rights over recolorized NeRF is crucial. While approaches like CopyRNeRF have been introduced to embed binary messages into NeRF models as digital signatures for copyright protection, the process of recolorization can remove these binary messages. In our paper, we present GeometrySticker, a method for seamlessly integrating binary messages into the geometry components of radiance fields, akin to applying a sticker. GeometrySticker can embed binary messages into NeRF models while preserving the effectiveness of these messages against recolorization. Our comprehensive studies demonstrate that GeometrySticker is adaptable to prevalent NeRF architectures and maintains a commendable level of robustness against various distortions. Project page: https://kevinhuangxf.github.io/GeometrySticker/.
QMNet: Importance-Aware Message Exchange for Decentralized Multi-Agent Reinforcement Learning
Jul 18, 2023



To improve the performance of multi-agent reinforcement learning under the constraint of wireless resources, we propose a message importance metric and design an importance-aware scheduling policy to effectively exchange messages. The key insight is spending the precious communication resources on important messages. The message importance depends not only on the messages themselves, but also on the needs of agents who receive them. Accordingly, we propose a query-message-based architecture, called QMNet. Agents generate queries and messages with the environment observation. Sharing queries can help calculate message importance. Exchanging messages can help agents cooperate better. Besides, we exploit the message importance to deal with random access collisions in decentralized systems. Furthermore, a message prediction mechanism is proposed to compensate for messages that are not transmitted. Finally, we evaluate the proposed schemes in a traffic junction environment, where only a fraction of agents can send messages due to limited wireless resources. Results show that QMNet can extract valuable information to guarantee the system performance even when only $30\%$ of agents can share messages. By exploiting message prediction, the system can further save $40\%$ of wireless resources. The importance-aware decentralized multi-access mechanism can effectively avoid collisions, achieving almost the same performance as centralized scheduling.
Dynamic Compression Ratio Selection for Edge Inference Systems with Hard Deadlines
May 25, 2020

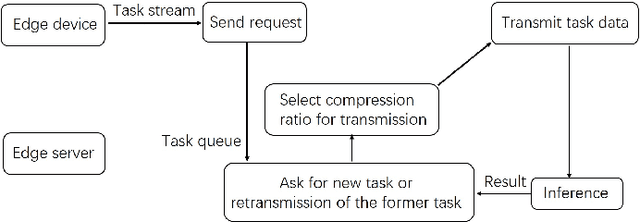

Implementing machine learning algorithms on Internet of things (IoT) devices has become essential for emerging applications, such as autonomous driving, environment monitoring. But the limitations of computation capability and energy consumption make it difficult to run complex machine learning algorithms on IoT devices, especially when latency deadline exists. One solution is to offload the computation intensive tasks to the edge server. However, the wireless uploading of the raw data is time consuming and may lead to deadline violation. To reduce the communication cost, lossy data compression can be exploited for inference tasks, but may bring more erroneous inference results. In this paper, we propose a dynamic compression ratio selection scheme for edge inference system with hard deadlines. The key idea is to balance the tradeoff between communication cost and inference accuracy. By dynamically selecting the optimal compression ratio with the remaining deadline budgets for queued tasks, more tasks can be timely completed with correct inference under limited communication resources. Furthermore, information augmentation that retransmits less compressed data of task with erroneous inference, is proposed to enhance the accuracy performance. While it is often hard to know the correctness of inference, we use uncertainty to estimate the confidence of the inference, and based on that, jointly optimize the information augmentation and compression ratio selection. Lastly, considering the wireless transmission errors, we further design a retransmission scheme to reduce performance degradation due to packet losses. Simulation results show the performance of the proposed schemes under different deadlines and task arrival rates.
Video to Fully Automatic 3D Hair Model
Sep 13, 2018
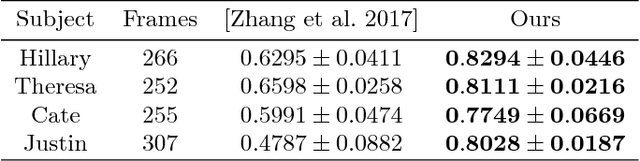

Imagine taking a selfie video with your mobile phone and getting as output a 3D model of your head (face and 3D hair strands) that can be later used in VR, AR, and any other domain. State of the art hair reconstruction methods allow either a single photo (thus compromising 3D quality) or multiple views, but they require manual user interaction (manual hair segmentation and capture of fixed camera views that span full 360 degree). In this paper, we describe a system that can completely automatically create a reconstruction from any video (even a selfie video), and we don't require specific views, since taking your -90 degree, 90 degree, and full back views is not feasible in a selfie capture. In the core of our system, in addition to the automatization components, hair strands are estimated and deformed in 3D (rather than 2D as in state of the art) thus enabling superior results. We provide qualitative, quantitative, and Mechanical Turk human studies that support the proposed system, and show results on a diverse variety of videos (8 different celebrity videos, 9 selfie mobile videos, spanning age, gender, hair length, type, and styling).