 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEDIC-AD: Towards Medical Vision-Language Model's Clinical Intelligence
Mar 28, 2026Lesion detection, symptom tracking, and visual explainability are central to real-world medical image analysis, yet current medical Vision-Language Models (VLMs) still lack mechanisms that translate their broad knowledge into clinically actionable outputs. To bridge this gap, we present MEDIC-AD, a clinically oriented VLM that strengthens these three capabilities through a stage-wise framework. First, learnable anomaly-aware tokens (<Ano>) encourage the model to focus on abnormal regions and build more discriminative lesion centered representations. Second, inter image difference tokens (<Diff>) explicitly encode temporal changes between studies, allowing the model to distinguish worsening, improvement, and stability in disease burden. Finally, a dedicated explainability stage trains the model to generate heatmaps that highlight lesion-related regions, offering clear visual evidence that is consistent with the model's reasoning. Through our staged design, MEDIC-AD steadily boosts performance across anomaly detection, symptom tracking, and anomaly segmentation, achieving state-of-the-art results compared with both closed source and medical-specialized baselines. Evaluations on real longitudinal clinical data collected from real hospital workflows further show that MEDIC-AD delivers stable predictions and clinically faithful explanations in practical patient-monitoring and decision-support workflows
Align 3D Representation and Text Embedding for 3D Content Personalization
Aug 23, 2025Recent advances in NeRF and 3DGS have significantly enhanced the efficiency and quality of 3D content synthesis. However, efficient personalization of generated 3D content remains a critical challenge. Current 3D personalization approaches predominantly rely on knowledge distillation-based methods, which require computationally expensive retraining procedures. To address this challenge, we propose \textbf{Invert3D}, a novel framework for convenient 3D content personalization. Nowadays, vision-language models such as CLIP enable direct image personalization through aligned vision-text embedding spaces. However, the inherent structural differences between 3D content and 2D images preclude direct application of these techniques to 3D personalization. Our approach bridges this gap by establishing alignment between 3D representations and text embedding spaces. Specifically, we develop a camera-conditioned 3D-to-text inverse mechanism that projects 3D contents into a 3D embedding aligned with text embeddings. This alignment enables efficient manipulation and personalization of 3D content through natural language prompts, eliminating the need for computationally retraining procedures. Extensive experiments demonstrate that Invert3D achieves effective personalization of 3D content. Our work is available at: https://github.com/qsong2001/Invert3D.
One-Minute Video Generation with Test-Time Training
Apr 07, 2025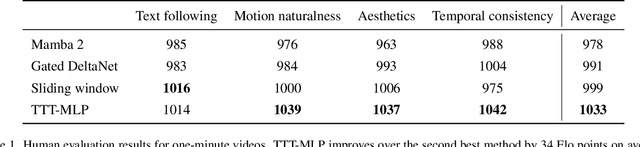
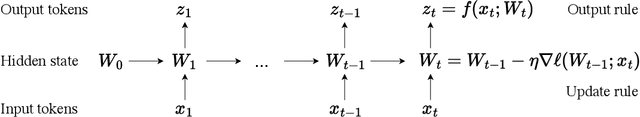
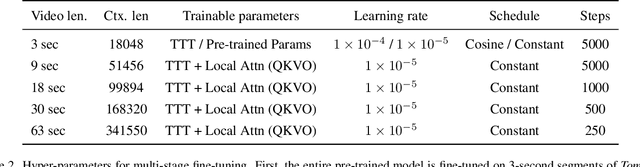
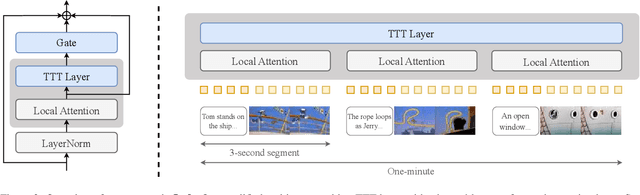
Transformers today still struggle to generate one-minute videos because self-attention layers are inefficient for long context. Alternatives such as Mamba layers struggle with complex multi-scene stories because their hidden states are less expressive. We experiment with Test-Time Training (TTT) layers, whose hidden states themselves can be neural networks, therefore more expressive. Adding TTT layers into a pre-trained Transformer enables it to generate one-minute videos from text storyboards. For proof of concept, we curate a dataset based on Tom and Jerry cartoons. Compared to baselines such as Mamba~2, Gated DeltaNet, and sliding-window attention layers, TTT layers generate much more coherent videos that tell complex stories, leading by 34 Elo points in a human evaluation of 100 videos per method. Although promising, results still contain artifacts, likely due to the limited capability of the pre-trained 5B model. The efficiency of our implementation can also be improved. We have only experimented with one-minute videos due to resource constraints, but the approach can be extended to longer videos and more complex stories. Sample videos, code and annotations are available at: https://test-time-training.github.io/video-dit
Parallel Sequence Modeling via Generalized Spatial Propagation Network
Jan 21, 2025



We present the Generalized Spatial Propagation Network (GSPN), a new attention mechanism optimized for vision tasks that inherently captures 2D spatial structures. Existing attention models, including transformers, linear attention, and state-space models like Mamba, process multi-dimensional data as 1D sequences, compromising spatial coherence and efficiency. GSPN overcomes these limitations by directly operating on spatially coherent image data and forming dense pairwise connections through a line-scan approach. Central to GSPN is the Stability-Context Condition, which ensures stable, context-aware propagation across 2D sequences and reduces the effective sequence length to $\sqrt{N}$ for a square map with N elements, significantly enhancing computational efficiency. With learnable, input-dependent weights and no reliance on positional embeddings, GSPN achieves superior spatial fidelity and state-of-the-art performance in vision tasks, including ImageNet classification, class-guided image generation, and text-to-image generation. Notably, GSPN accelerates SD-XL with softmax-attention by over $84\times$ when generating 16K images.
GaussianMarker: Uncertainty-Aware Copyright Protection of 3D Gaussian Splatting
Oct 31, 2024



3D Gaussian Splatting (3DGS) has become a crucial method for acquiring 3D assets. To protect the copyright of these assets, digital watermarking techniques can be applied to embed ownership information discreetly within 3DGS models. However, existing watermarking methods for meshes, point clouds, and implicit radiance fields cannot be directly applied to 3DGS models, as 3DGS models use explicit 3D Gaussians with distinct structures and do not rely on neural networks. Naively embedding the watermark on a pre-trained 3DGS can cause obvious distortion in rendered images. In our work, we propose an uncertainty-based method that constrains the perturbation of model parameters to achieve invisible watermarking for 3DGS. At the message decoding stage, the copyright messages can be reliably extracted from both 3D Gaussians and 2D rendered images even under various forms of 3D and 2D distortions. We conduct extensive experiments on the Blender, LLFF and MipNeRF-360 datasets to validate the effectiveness of our proposed method, demonstrating state-of-the-art performance on both message decoding accuracy and view synthesis quality.
Geometry Cloak: Preventing TGS-based 3D Reconstruction from Copyrighted Images
Oct 30, 2024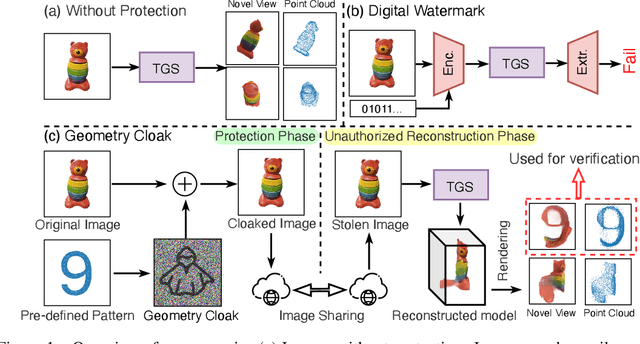
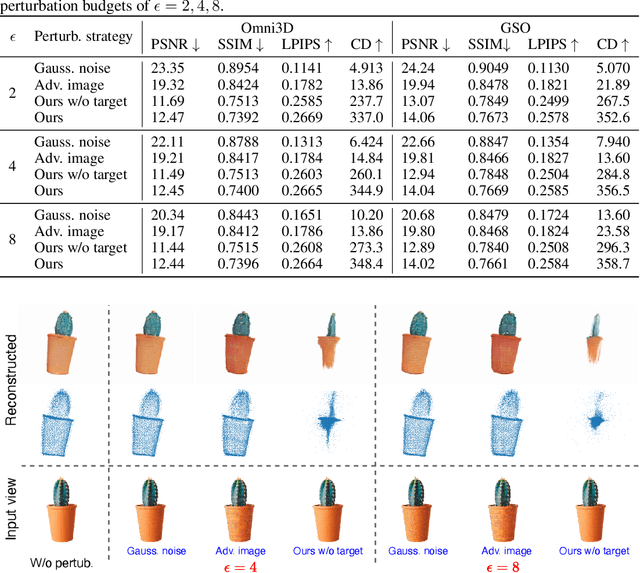
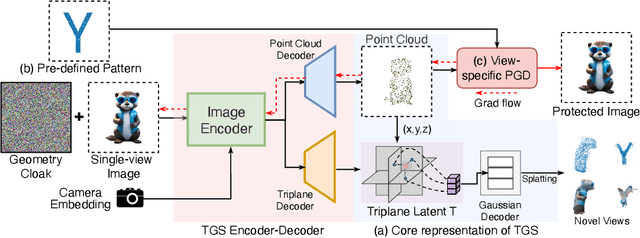

Single-view 3D reconstruction methods like Triplane Gaussian Splatting (TGS) have enabled high-quality 3D model generation from just a single image input within seconds. However, this capability raises concerns about potential misuse, where malicious users could exploit TGS to create unauthorized 3D models from copyrighted images. To prevent such infringement, we propose a novel image protection approach that embeds invisible geometry perturbations, termed "geometry cloaks", into images before supplying them to TGS. These carefully crafted perturbations encode a customized message that is revealed when TGS attempts 3D reconstructions of the cloaked image. Unlike conventional adversarial attacks that simply degrade output quality, our method forces TGS to fail the 3D reconstruction in a specific way - by generating an identifiable customized pattern that acts as a watermark. This watermark allows copyright holders to assert ownership over any attempted 3D reconstructions made from their protected images. Extensive experiments have verified the effectiveness of our geometry cloak. Our project is available at https://qsong2001.github.io/geometry_cloak.
GeometrySticker: Enabling Ownership Claim of Recolorized Neural Radiance Fields
Jul 18, 2024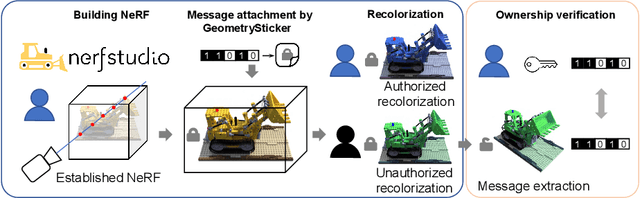

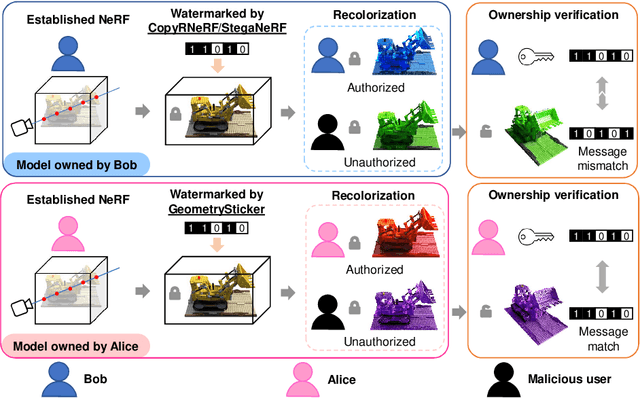

Remarkable advancements in the recolorization of Neural Radiance Fields (NeRF) have simplified the process of modifying NeRF's color attributes. Yet, with the potential of NeRF to serve as shareable digital assets, there's a concern that malicious users might alter the color of NeRF models and falsely claim the recolorized version as their own. To safeguard against such breaches of ownership, enabling original NeRF creators to establish rights over recolorized NeRF is crucial. While approaches like CopyRNeRF have been introduced to embed binary messages into NeRF models as digital signatures for copyright protection, the process of recolorization can remove these binary messages. In our paper, we present GeometrySticker, a method for seamlessly integrating binary messages into the geometry components of radiance fields, akin to applying a sticker. GeometrySticker can embed binary messages into NeRF models while preserving the effectiveness of these messages against recolorization. Our comprehensive studies demonstrate that GeometrySticker is adaptable to prevalent NeRF architectures and maintains a commendable level of robustness against various distortions. Project page: https://kevinhuangxf.github.io/GeometrySticker/.
TCM-FTP: Fine-Tuning Large Language Models for Herbal Prescription Prediction
Jul 15, 2024



Traditional Chinese medicine (TCM) relies on specific combinations of herbs in prescriptions to treat symptoms and signs, a practice that spans thousands of years. Predicting TCM prescriptions presents a fascinating technical challenge with practical implications. However, this task faces limitations due to the scarcity of high-quality clinical datasets and the intricate relationship between symptoms and herbs. To address these issues, we introduce DigestDS, a new dataset containing practical medical records from experienced experts in digestive system diseases. We also propose a method, TCM-FTP (TCM Fine-Tuning Pre-trained), to leverage pre-trained large language models (LLMs) through supervised fine-tuning on DigestDS. Additionally, we enhance computational efficiency using a low-rank adaptation technique. TCM-FTP also incorporates data augmentation by permuting herbs within prescriptions, capitalizing on their order-agnostic properties. Impressively, TCM-FTP achieves an F1-score of 0.8031, surpassing previous methods significantly. Furthermore, it demonstrates remarkable accuracy in dosage prediction, achieving a normalized mean square error of 0.0604. In contrast, LLMs without fine-tuning perform poorly. Although LLMs have shown capabilities on a wide range of tasks, this work illustrates the importance of fine-tuning for TCM prescription prediction, and we have proposed an effective way to do that.
Protecting NeRFs' Copyright via Plug-And-Play Watermarking Base Model
Jul 10, 2024



Neural Radiance Fields (NeRFs) have become a key method for 3D scene representation. With the rising prominence and influence of NeRF, safeguarding its intellectual property has become increasingly important. In this paper, we propose \textbf{NeRFProtector}, which adopts a plug-and-play strategy to protect NeRF's copyright during its creation. NeRFProtector utilizes a pre-trained watermarking base model, enabling NeRF creators to embed binary messages directly while creating their NeRF. Our plug-and-play property ensures NeRF creators can flexibly choose NeRF variants without excessive modifications. Leveraging our newly designed progressive distillation, we demonstrate performance on par with several leading-edge neural rendering methods. Our project is available at: \url{https://qsong2001.github.io/NeRFProtector}.
Unlocking Continual Learning Abilities in Language Models
Jun 25, 2024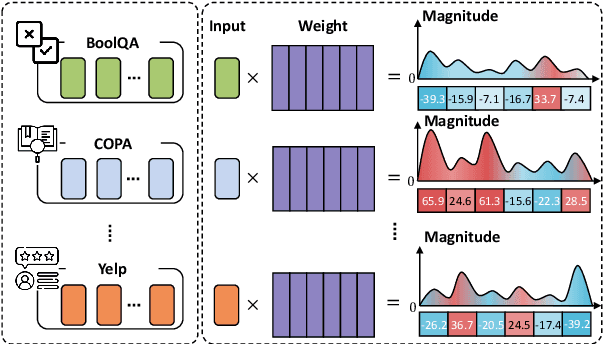
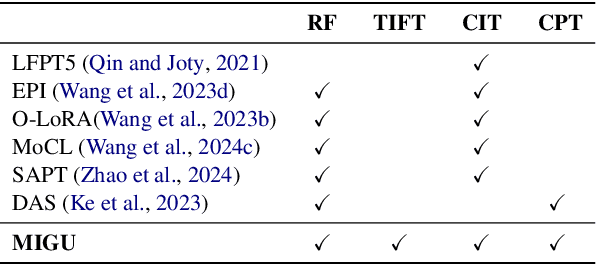
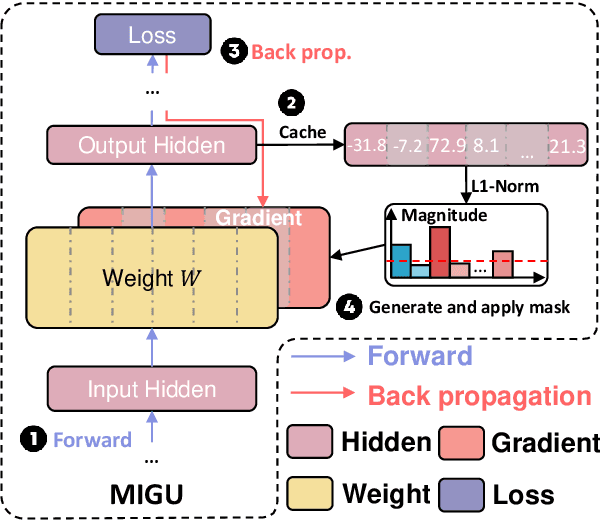
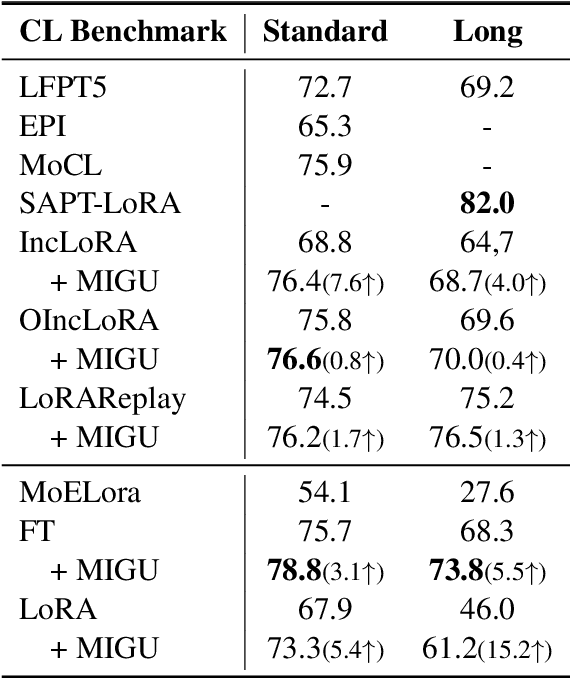
Language models (LMs) exhibit impressive performance and generalization capabilities. However, LMs struggle with the persistent challenge of catastrophic forgetting, which undermines their long-term sustainability in continual learning (CL). Existing approaches usually address the issue by incorporating old task data or task-wise inductive bias into LMs. However, old data and accurate task information are often unavailable or costly to collect, hindering the availability of current CL approaches for LMs. To address this limitation, we introduce $\textbf{MIGU}$ ($\textbf{M}$agn$\textbf{I}$tude-based $\textbf{G}$radient $\textbf{U}$pdating for continual learning), a rehearsal-free and task-label-free method that only updates the model parameters with large magnitudes of output in LMs' linear layers. MIGU is based on our observation that the L1-normalized magnitude distribution of the output in LMs' linear layers is different when the LM models deal with different task data. By imposing this simple constraint on the gradient update process, we can leverage the inherent behaviors of LMs, thereby unlocking their innate CL abilities. Our experiments demonstrate that MIGU is universally applicable to all three LM architectures (T5, RoBERTa, and Llama2), delivering state-of-the-art or on-par performance across continual finetuning and continual pre-training settings on four CL benchmarks. For example, MIGU brings a 15.2% average accuracy improvement over conventional parameter-efficient finetuning baselines in a 15-task CL benchmark. MIGU can also seamlessly integrate with all three existing CL types to further enhance performance. Code is available at \href{https://github.com/wenyudu/MIGU}{this https URL}.