 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Aware Encoder Control for Deep Video Compression
Apr 07, 2024



Prior research on deep video compression (DVC) for machine tasks typically necessitates training a unique codec for each specific task, mandating a dedicated decoder per task. In contrast, traditional video codecs employ a flexible encoder controller, enabling the adaptation of a single codec to different tasks through mechanisms like mode prediction. Drawing inspiration from this, we introduce an innovative encoder controller for deep video compression for machines. This controller features a mode prediction and a Group of Pictures (GoP) selection module. Our approach centralizes control at the encoding stage, allowing for adaptable encoder adjustments across different tasks, such as detection and tracking, while maintaining compatibility with a standard pre-trained DVC decoder. Empirical evidence demonstrates that our method is applicable across multiple tasks with various existing pre-trained DVCs. Moreover, extensive experiments demonstrate that our method outperforms previous DVC by about 25% bitrate for different tasks, with only one pre-trained decoder.
Super-High-Fidelity Image Compression via Hierarchical-ROI and Adaptive Quantization
Mar 19, 2024



Learned Image Compression (LIC) has achieved dramatic progress regarding objective and subjective metrics. MSE-based models aim to improve objective metrics while generative models are leveraged to improve visual quality measured by subjective metrics. However, they all suffer from blurring or deformation at low bit rates, especially at below $0.2bpp$. Besides, deformation on human faces and text is unacceptable for visual quality assessment, and the problem becomes more prominent on small faces and text. To solve this problem, we combine the advantage of MSE-based models and generative models by utilizing region of interest (ROI). We propose Hierarchical-ROI (H-ROI), to split images into several foreground regions and one background region to improve the reconstruction of regions containing faces, text, and complex textures. Further, we propose adaptive quantization by non-linear mapping within the channel dimension to constrain the bit rate while maintaining the visual quality. Exhaustive experiments demonstrate that our methods achieve better visual quality on small faces and text with lower bit rates, e.g., $0.7X$ bits of HiFiC and $0.5X$ bits of BPG.
GaussianImage: 1000 FPS Image Representation and Compression by 2D Gaussian Splatting
Mar 14, 2024



Implicit neural representations (INRs) recently achieved great success in image representation and compression, offering high visual quality and fast rendering speeds with 10-1000 FPS, assuming sufficient GPU resources are available. However, this requirement often hinders their use on low-end devices with limited memory. In response, we propose a groundbreaking paradigm of image representation and compression by 2D Gaussian Splatting, named GaussianImage. We first introduce 2D Gaussian to represent the image, where each Gaussian has 8 parameters including position, covariance and color. Subsequently, we unveil a novel rendering algorithm based on accumulated summation. Remarkably, our method with a minimum of 3$\times$ lower GPU memory usage and 5$\times$ faster fitting time not only rivals INRs (e.g., WIRE, I-NGP) in representation performance, but also delivers a faster rendering speed of 1500-2000 FPS regardless of parameter size. Furthermore, we integrate existing vector quantization technique to build an image codec. Experimental results demonstrate that our codec attains rate-distortion performance comparable to compression-based INRs such as COIN and COIN++, while facilitating decoding speeds of approximately 1000 FPS. Additionally, preliminary proof of concept shows that our codec surpasses COIN and COIN++ in performance when using partial bits-back coding.
Boosting Neural Representations for Videos with a Conditional Decoder
Mar 08, 2024



Implicit neural representations (INRs) have emerged as a promising approach for video storage and processing, showing remarkable versatility across various video tasks. However, existing methods often fail to fully leverage their representation capabilities, primarily due to inadequate alignment of intermediate features during target frame decoding. This paper introduces a universal boosting framework for current implicit video representation approaches. Specifically, we utilize a conditional decoder with a temporal-aware affine transform module, which uses the frame index as a prior condition to effectively align intermediate features with target frames. Besides, we introduce a sinusoidal NeRV-like block to generate diverse intermediate features and achieve a more balanced parameter distribution, thereby enhancing the model's capacity. With a high-frequency information-preserving reconstruction loss, our approach successfully boosts multiple baseline INRs in the reconstruction quality and convergence speed for video regression, and exhibits superior inpainting and interpolation results. Further, we integrate a consistent entropy minimization technique and develop video codecs based on these boosted INRs. Experiments on the UVG dataset confirm that our enhanced codecs significantly outperform baseline INRs and offer competitive rate-distortion performance compared to traditional and learning-based codecs.
Motion-I2V: Consistent and Controllable Image-to-Video Generation with Explicit Motion Modeling
Jan 31, 2024



We introduce Motion-I2V, a novel framework for consistent and controllable image-to-video generation (I2V). In contrast to previous methods that directly learn the complicated image-to-video mapping, Motion-I2V factorizes I2V into two stages with explicit motion modeling. For the first stage, we propose a diffusion-based motion field predictor, which focuses on deducing the trajectories of the reference image's pixels. For the second stage, we propose motion-augmented temporal attention to enhance the limited 1-D temporal attention in video latent diffusion models. This module can effectively propagate reference image's feature to synthesized frames with the guidance of predicted trajectories from the first stage. Compared with existing methods, Motion-I2V can generate more consistent videos even at the presence of large motion and viewpoint variation. By training a sparse trajectory ControlNet for the first stage, Motion-I2V can support users to precisely control motion trajectories and motion regions with sparse trajectory and region annotations. This offers more controllability of the I2V process than solely relying on textual instructions. Additionally, Motion-I2V's second stage naturally supports zero-shot video-to-video translation. Both qualitative and quantitative comparisons demonstrate the advantages of Motion-I2V over prior approaches in consistent and controllable image-to-video generation. Please see our project page at https://xiaoyushi97.github.io/Motion-I2V/.
Idempotence and Perceptual Image Compression
Jan 17, 2024


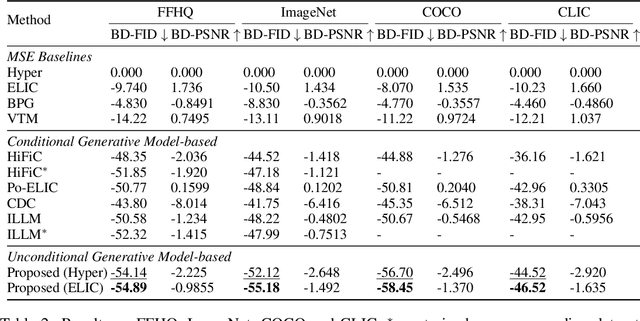
Idempotence is the stability of image codec to re-compression. At the first glance, it is unrelated to perceptual image compression. However, we find that theoretically: 1) Conditional generative model-based perceptual codec satisfies idempotence; 2) Unconditional generative model with idempotence constraint is equivalent to conditional generative codec. Based on this newfound equivalence, we propose a new paradigm of perceptual image codec by inverting unconditional generative model with idempotence constraints. Our codec is theoretically equivalent to conditional generative codec, and it does not require training new models. Instead, it only requires a pre-trained mean-square-error codec and unconditional generative model. Empirically, we show that our proposed approach outperforms state-of-the-art methods such as HiFiC and ILLM, in terms of Fr\'echet Inception Distance (FID). The source code is provided in https://github.com/tongdaxu/Idempotence-and-Perceptual-Image-Compression.
Unified learning-based lossy and lossless JPEG recompression
Dec 05, 2023
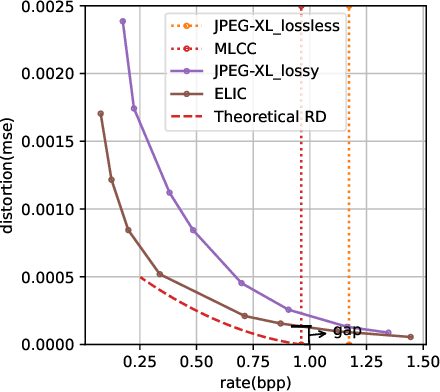
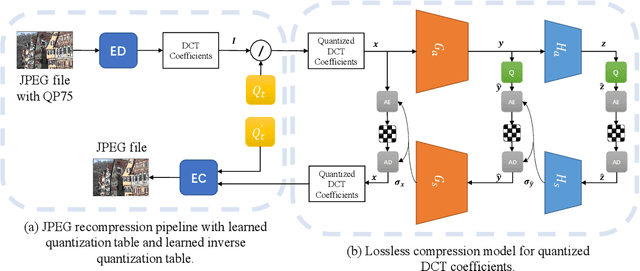
JPEG is still the most widely used image compression algorithm. Most image compression algorithms only consider uncompressed original image, while ignoring a large number of already existing JPEG images. Recently, JPEG recompression approaches have been proposed to further reduce the size of JPEG files. However, those methods only consider JPEG lossless recompression, which is just a special case of the rate-distortion theorem. In this paper, we propose a unified lossly and lossless JPEG recompression framework, which consists of learned quantization table and Markovian hierarchical variational autoencoders. Experiments show that our method can achieve arbitrarily low distortion when the bitrate is close to the upper bound, namely the bitrate of the lossless compression model. To the best of our knowledge, this is the first learned method that bridges the gap between lossy and lossless recompression of JPEG images.
Efficient Learned Lossless JPEG Recompression
Aug 25, 2023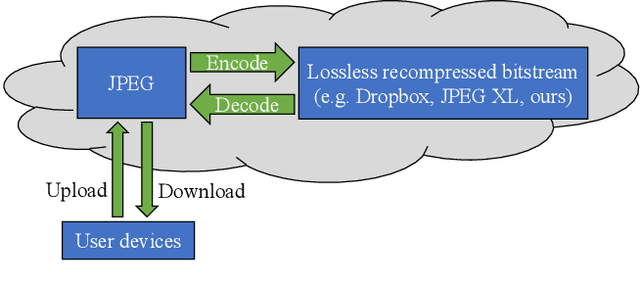
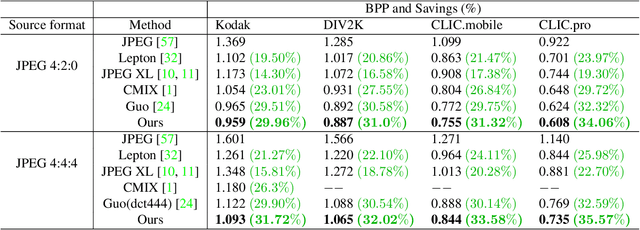
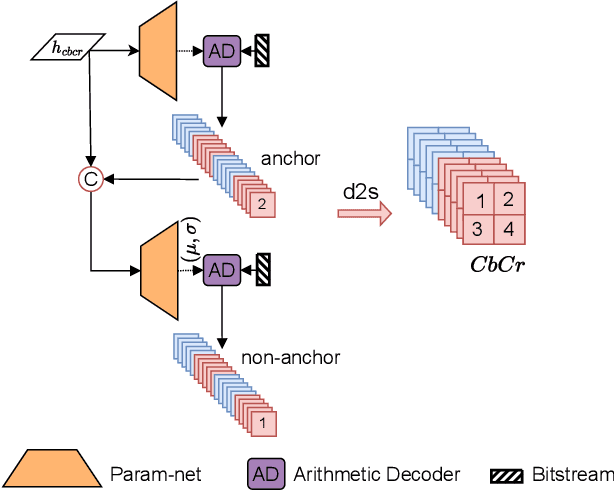

JPEG is one of the most popular image compression methods. It is beneficial to compress those existing JPEG files without introducing additional distortion. In this paper, we propose a deep learning based method to further compress JPEG images losslessly. Specifically, we propose a Multi-Level Parallel Conditional Modeling (ML-PCM) architecture, which enables parallel decoding in different granularities. First, luma and chroma are processed independently to allow parallel coding. Second, we propose pipeline parallel context model (PPCM) and compressed checkerboard context model (CCCM) for the effective conditional modeling and efficient decoding within luma and chroma components. Our method has much lower latency while achieves better compression ratio compared with previous SOTA. After proper software optimization, we can obtain a good throughput of 57 FPS for 1080P images on NVIDIA T4 GPU. Furthermore, combined with quantization, our approach can also act as a lossy JPEG codec which has obvious advantage over SOTA lossy compression methods in high bit rate (bpp$>0.9$).
Conditional Perceptual Quality Preserving Image Compression
Aug 16, 2023



We propose conditional perceptual quality, an extension of the perceptual quality defined in \citet{blau2018perception}, by conditioning it on user defined information. Specifically, we extend the original perceptual quality $d(p_{X},p_{\hat{X}})$ to the conditional perceptual quality $d(p_{X|Y},p_{\hat{X}|Y})$, where $X$ is the original image, $\hat{X}$ is the reconstructed, $Y$ is side information defined by user and $d(.,.)$ is divergence. We show that conditional perceptual quality has similar theoretical properties as rate-distortion-perception trade-off \citep{blau2019rethinking}. Based on these theoretical results, we propose an optimal framework for conditional perceptual quality preserving compression. Experimental results show that our codec successfully maintains high perceptual quality and semantic quality at all bitrate. Besides, by providing a lowerbound of common randomness required, we settle the previous arguments on whether randomness should be incorporated into generator for (conditional) perceptual quality compression. The source code is provided in supplementary material.
FlowFormer: A Transformer Architecture and Its Masked Cost Volume Autoencoding for Optical Flow
Jun 08, 2023This paper introduces a novel transformer-based network architecture, FlowFormer, along with the Masked Cost Volume AutoEncoding (MCVA) for pretraining it to tackle the problem of optical flow estimation. FlowFormer tokenizes the 4D cost-volume built from the source-target image pair and iteratively refines flow estimation with a cost-volume encoder-decoder architecture. The cost-volume encoder derives a cost memory with alternate-group transformer~(AGT) layers in a latent space and the decoder recurrently decodes flow from the cost memory with dynamic positional cost queries. On the Sintel benchmark, FlowFormer architecture achieves 1.16 and 2.09 average end-point-error~(AEPE) on the clean and final pass, a 16.5\% and 15.5\% error reduction from the GMA~(1.388 and 2.47). MCVA enhances FlowFormer by pretraining the cost-volume encoder with a masked autoencoding scheme, which further unleashes the capability of FlowFormer with unlabeled data. This is especially critical in optical flow estimation because ground truth flows are more expensive to acquire than labels in other vision tasks. MCVA improves FlowFormer all-sided and FlowFormer+MCVA ranks 1st among all published methods on both Sintel and KITTI-2015 benchmarks and achieves the best generalization performance. Specifically, FlowFormer+MCVA achieves 1.07 and 1.94 AEPE on the Sintel benchmark, leading to 7.76\% and 7.18\% error reductions from FlowFormer.