 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalt: Self-Consistent Distribution Matching with Cache-Aware Training for Fast Video Generation
Apr 03, 2026Distilling video generation models to extremely low inference budgets (e.g., 2--4 NFEs) is crucial for real-time deployment, yet remains challenging. Trajectory-style consistency distillation often becomes conservative under complex video dynamics, yielding an over-smoothed appearance and weak motion. Distribution matching distillation (DMD) can recover sharp, mode-seeking samples, but its local training signals do not explicitly regularize how denoising updates compose across timesteps, making composed rollouts prone to drift. To overcome this challenge, we propose Self-Consistent Distribution Matching Distillation (SC-DMD), which explicitly regularizes the endpoint-consistent composition of consecutive denoising updates. For real-time autoregressive video generation, we further treat the KV cache as a quality parameterized condition and propose Cache-Distribution-Aware training. This training scheme applies SC-DMD over multi-step rollouts and introduces a cache-conditioned feature alignment objective that steers low-quality outputs toward high-quality references. Across extensive experiments on both non-autoregressive backbones (e.g., Wan~2.1) and autoregressive real-time paradigms (e.g., Self Forcing), our method, dubbed \textbf{Salt}, consistently improves low-NFE video generation quality while remaining compatible with diverse KV-cache memory mechanisms. Source code will be released at \href{https://github.com/XingtongGe/Salt}{https://github.com/XingtongGe/Salt}.
Improving Joint Audio-Video Generation with Cross-Modal Context Learning
Mar 19, 2026The dual-stream transformer architecture-based joint audio-video generation method has become the dominant paradigm in current research. By incorporating pre-trained video diffusion models and audio diffusion models, along with a cross-modal interaction attention module, high-quality, temporally synchronized audio-video content can be generated with minimal training data. In this paper, we first revisit the dual-stream transformer paradigm and further analyze its limitations, including model manifold variations caused by the gating mechanism controlling cross-modal interactions, biases in multi-modal background regions introduced by cross-modal attention, and the inconsistencies in multi-modal classifier-free guidance (CFG) during training and inference, as well as conflicts between multiple conditions. To alleviate these issues, we propose Cross-Modal Context Learning (CCL), equipped with several carefully designed modules. Temporally Aligned RoPE and Partitioning (TARP) effectively enhances the temporal alignment between audio latent and video latent representations. The Learnable Context Tokens (LCT) and Dynamic Context Routing (DCR) in the Cross-Modal Context Attention (CCA) module provide stable unconditional anchors for cross-modal information, while dynamically routing based on different training tasks, further enhancing the model's convergence speed and generation quality. During inference, Unconditional Context Guidance (UCG) leverages the unconditional support provided by LCT to facilitate different forms of CFG, improving train-inference consistency and further alleviating conflicts. Through comprehensive evaluations, CCL achieves state-of-the-art performance compared with recent academic methods while requiring substantially fewer resources.
AR-CoPO: Align Autoregressive Video Generation with Contrastive Policy Optimization
Mar 18, 2026Streaming autoregressive (AR) video generators combined with few-step distillation achieve low-latency, high-quality synthesis, yet remain difficult to align via reinforcement learning from human feedback (RLHF). Existing SDE-based GRPO methods face challenges in this setting: few-step ODEs and consistency model samplers deviate from standard flow-matching ODEs, and their short, low-stochasticity trajectories are highly sensitive to initialization noise, rendering intermediate SDE exploration ineffective. We propose AR-CoPO (AutoRegressive Contrastive Policy Optimization), a framework that adapts the Neighbor GRPO contrastive perspective to streaming AR generation. AR-CoPO introduces chunk-level alignment via a forking mechanism that constructs neighborhood candidates at a randomly selected chunk, assigns sequence-level rewards, and performs localized GRPO updates. We further propose a semi-on-policy training strategy that complements on-policy exploration with exploitation over a replay buffer of reference rollouts, improving generation quality across domains. Experiments on Self-Forcing demonstrate that AR-CoPO improves both out-of-domain generalization and in-domain human preference alignment over the baseline, providing evidence of genuine alignment rather than reward hacking.
Flash-VAED: Plug-and-Play VAE Decoders for Efficient Video Generation
Feb 22, 2026Latent diffusion models have enabled high-quality video synthesis, yet their inference remains costly and time-consuming. As diffusion transformers become increasingly efficient, the latency bottleneck inevitably shifts to VAE decoders. To reduce their latency while maintaining quality, we propose a universal acceleration framework for VAE decoders that preserves full alignment with the original latent distribution. Specifically, we propose (1) an independence-aware channel pruning method to effectively mitigate severe channel redundancy, and (2) a stage-wise dominant operator optimization strategy to address the high inference cost of the widely used causal 3D convolutions in VAE decoders. Based on these innovations, we construct a Flash-VAED family. Moreover, we design a three-phase dynamic distillation framework that efficiently transfers the capabilities of the original VAE decoder to Flash-VAED. Extensive experiments on Wan and LTX-Video VAE decoders demonstrate that our method outperforms baselines in both quality and speed, achieving approximately a 6$\times$ speedup while maintaining the reconstruction performance up to 96.9%. Notably, Flash-VAED accelerates the end-to-end generation pipeline by up to 36% with negligible quality drops on VBench-2.0.
GaussianImage++: Boosted Image Representation and Compression with 2D Gaussian Splatting
Dec 22, 2025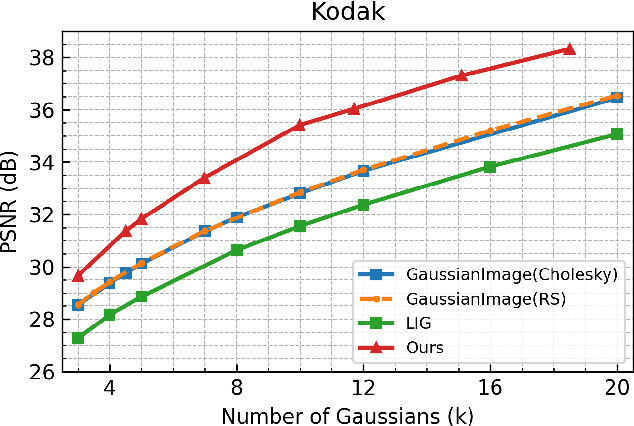
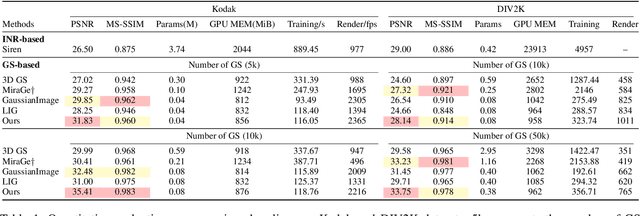
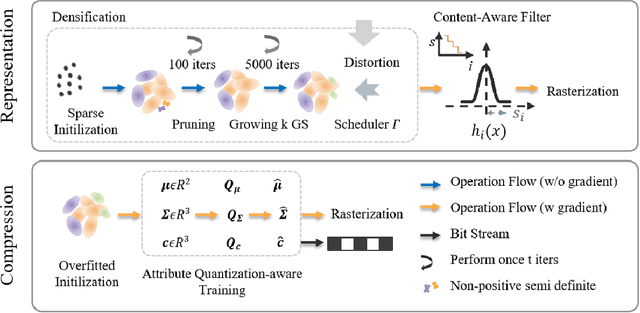

Implicit neural representations (INRs) have achieved remarkable success in image representation and compression, but they require substantial training time and memory. Meanwhile, recent 2D Gaussian Splatting (GS) methods (\textit{e.g.}, GaussianImage) offer promising alternatives through efficient primitive-based rendering. However, these methods require excessive Gaussian primitives to maintain high visual fidelity. To exploit the potential of GS-based approaches, we present GaussianImage++, which utilizes limited Gaussian primitives to achieve impressive representation and compression performance. Firstly, we introduce a distortion-driven densification mechanism. It progressively allocates Gaussian primitives according to signal intensity. Secondly, we employ context-aware Gaussian filters for each primitive, which assist in the densification to optimize Gaussian primitives based on varying image content. Thirdly, we integrate attribute-separated learnable scalar quantizers and quantization-aware training, enabling efficient compression of primitive attributes. Experimental results demonstrate the effectiveness of our method. In particular, GaussianImage++ outperforms GaussianImage and INRs-based COIN in representation and compression performance while maintaining real-time decoding and low memory usage.
Condition Weaving Meets Expert Modulation: Towards Universal and Controllable Image Generation
Aug 24, 2025The image-to-image generation task aims to produce controllable images by leveraging conditional inputs and prompt instructions. However, existing methods often train separate control branches for each type of condition, leading to redundant model structures and inefficient use of computational resources. To address this, we propose a Unified image-to-image Generation (UniGen) framework that supports diverse conditional inputs while enhancing generation efficiency and expressiveness. Specifically, to tackle the widely existing parameter redundancy and computational inefficiency in controllable conditional generation architectures, we propose the Condition Modulated Expert (CoMoE) module. This module aggregates semantically similar patch features and assigns them to dedicated expert modules for visual representation and conditional modeling. By enabling independent modeling of foreground features under different conditions, CoMoE effectively mitigates feature entanglement and redundant computation in multi-condition scenarios. Furthermore, to bridge the information gap between the backbone and control branches, we propose WeaveNet, a dynamic, snake-like connection mechanism that enables effective interaction between global text-level control from the backbone and fine-grained control from conditional branches. Extensive experiments on the Subjects-200K and MultiGen-20M datasets across various conditional image generation tasks demonstrate that our method consistently achieves state-of-the-art performance, validating its advantages in both versatility and effectiveness. The code has been uploaded to https://github.com/gavin-gqzhang/UniGen.
Rethinking Diffusion Posterior Sampling: From Conditional Score Estimator to Maximizing a Posterior
Jan 31, 2025Recent advancements in diffusion models have been leveraged to address inverse problems without additional training, and Diffusion Posterior Sampling (DPS) (Chung et al., 2022a) is among the most popular approaches. Previous analyses suggest that DPS accomplishes posterior sampling by approximating the conditional score. While in this paper, we demonstrate that the conditional score approximation employed by DPS is not as effective as previously assumed, but rather aligns more closely with the principle of maximizing a posterior (MAP). This assertion is substantiated through an examination of DPS on 512x512 ImageNet images, revealing that: 1) DPS's conditional score estimation significantly diverges from the score of a well-trained conditional diffusion model and is even inferior to the unconditional score; 2) The mean of DPS's conditional score estimation deviates significantly from zero, rendering it an invalid score estimation; 3) DPS generates high-quality samples with significantly lower diversity. In light of the above findings, we posit that DPS more closely resembles MAP than a conditional score estimator, and accordingly propose the following enhancements to DPS: 1) we explicitly maximize the posterior through multi-step gradient ascent and projection; 2) we utilize a light-weighted conditional score estimator trained with only 100 images and 8 GPU hours. Extensive experimental results indicate that these proposed improvements significantly enhance DPS's performance. The source code for these improvements is provided in https://github.com/tongdaxu/Rethinking-Diffusion-Posterior-Sampling-From-Conditional-Score-Estimator-to-Maximizing-a-Posterior.
MEGA: Memory-Efficient 4D Gaussian Splatting for Dynamic Scenes
Oct 17, 20244D Gaussian Splatting (4DGS) has recently emerged as a promising technique for capturing complex dynamic 3D scenes with high fidelity. It utilizes a 4D Gaussian representation and a GPU-friendly rasterizer, enabling rapid rendering speeds. Despite its advantages, 4DGS faces significant challenges, notably the requirement of millions of 4D Gaussians, each with extensive associated attributes, leading to substantial memory and storage cost. This paper introduces a memory-efficient framework for 4DGS. We streamline the color attribute by decomposing it into a per-Gaussian direct color component with only 3 parameters and a shared lightweight alternating current color predictor. This approach eliminates the need for spherical harmonics coefficients, which typically involve up to 144 parameters in classic 4DGS, thereby creating a memory-efficient 4D Gaussian representation. Furthermore, we introduce an entropy-constrained Gaussian deformation technique that uses a deformation field to expand the action range of each Gaussian and integrates an opacity-based entropy loss to limit the number of Gaussians, thus forcing our model to use as few Gaussians as possible to fit a dynamic scene well. With simple half-precision storage and zip compression, our framework achieves a storage reduction by approximately 190$\times$ and 125$\times$ on the Technicolor and Neural 3D Video datasets, respectively, compared to the original 4DGS. Meanwhile, it maintains comparable rendering speeds and scene representation quality, setting a new standard in the field.
Task-Aware Encoder Control for Deep Video Compression
Apr 07, 2024



Prior research on deep video compression (DVC) for machine tasks typically necessitates training a unique codec for each specific task, mandating a dedicated decoder per task. In contrast, traditional video codecs employ a flexible encoder controller, enabling the adaptation of a single codec to different tasks through mechanisms like mode prediction. Drawing inspiration from this, we introduce an innovative encoder controller for deep video compression for machines. This controller features a mode prediction and a Group of Pictures (GoP) selection module. Our approach centralizes control at the encoding stage, allowing for adaptable encoder adjustments across different tasks, such as detection and tracking, while maintaining compatibility with a standard pre-trained DVC decoder. Empirical evidence demonstrates that our method is applicable across multiple tasks with various existing pre-trained DVCs. Moreover, extensive experiments demonstrate that our method outperforms previous DVC by about 25% bitrate for different tasks, with only one pre-trained decoder.
Content-aware Masked Image Modeling Transformer for Stereo Image Compression
Mar 20, 2024Existing learning-based stereo image codec adopt sophisticated transformation with simple entropy models derived from single image codecs to encode latent representations. However, those entropy models struggle to effectively capture the spatial-disparity characteristics inherent in stereo images, which leads to suboptimal rate-distortion results. In this paper, we propose a stereo image compression framework, named CAMSIC. CAMSIC independently transforms each image to latent representation and employs a powerful decoder-free Transformer entropy model to capture both spatial and disparity dependencies, by introducing a novel content-aware masked image modeling (MIM) technique. Our content-aware MIM facilitates efficient bidirectional interaction between prior information and estimated tokens, which naturally obviates the need for an extra Transformer decoder. Experiments show that our stereo image codec achieves state-of-the-art rate-distortion performance on two stereo image datasets Cityscapes and InStereo2K with fast encoding and decoding speed.