 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Aware Encoder Control for Deep Video Compression
Apr 07, 2024



Prior research on deep video compression (DVC) for machine tasks typically necessitates training a unique codec for each specific task, mandating a dedicated decoder per task. In contrast, traditional video codecs employ a flexible encoder controller, enabling the adaptation of a single codec to different tasks through mechanisms like mode prediction. Drawing inspiration from this, we introduce an innovative encoder controller for deep video compression for machines. This controller features a mode prediction and a Group of Pictures (GoP) selection module. Our approach centralizes control at the encoding stage, allowing for adaptable encoder adjustments across different tasks, such as detection and tracking, while maintaining compatibility with a standard pre-trained DVC decoder. Empirical evidence demonstrates that our method is applicable across multiple tasks with various existing pre-trained DVCs. Moreover, extensive experiments demonstrate that our method outperforms previous DVC by about 25% bitrate for different tasks, with only one pre-trained decoder.
GaussianImage: 1000 FPS Image Representation and Compression by 2D Gaussian Splatting
Mar 14, 2024



Implicit neural representations (INRs) recently achieved great success in image representation and compression, offering high visual quality and fast rendering speeds with 10-1000 FPS, assuming sufficient GPU resources are available. However, this requirement often hinders their use on low-end devices with limited memory. In response, we propose a groundbreaking paradigm of image representation and compression by 2D Gaussian Splatting, named GaussianImage. We first introduce 2D Gaussian to represent the image, where each Gaussian has 8 parameters including position, covariance and color. Subsequently, we unveil a novel rendering algorithm based on accumulated summation. Remarkably, our method with a minimum of 3$\times$ lower GPU memory usage and 5$\times$ faster fitting time not only rivals INRs (e.g., WIRE, I-NGP) in representation performance, but also delivers a faster rendering speed of 1500-2000 FPS regardless of parameter size. Furthermore, we integrate existing vector quantization technique to build an image codec. Experimental results demonstrate that our codec attains rate-distortion performance comparable to compression-based INRs such as COIN and COIN++, while facilitating decoding speeds of approximately 1000 FPS. Additionally, preliminary proof of concept shows that our codec surpasses COIN and COIN++ in performance when using partial bits-back coding.
Deep Contrastive Multi-view Clustering under Semantic Feature Guidance
Mar 09, 2024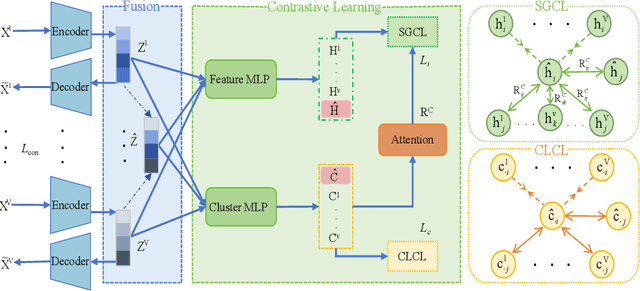
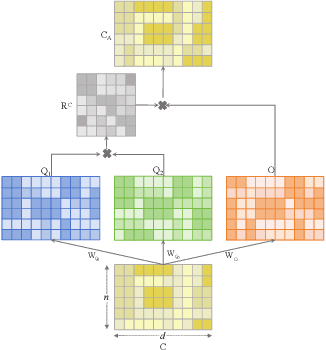
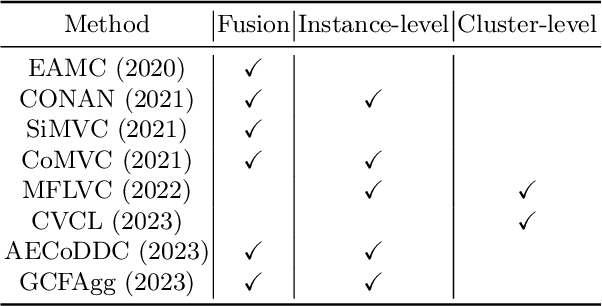
Contrastive learning has achieved promising performance in the field of multi-view clustering recently. However, the positive and negative sample construction mechanisms ignoring semantic consistency lead to false negative pairs, limiting the performance of existing algorithms from further improvement. To solve this problem, we propose a multi-view clustering framework named Deep Contrastive Multi-view Clustering under Semantic feature guidance (DCMCS) to alleviate the influence of false negative pairs. Specifically, view-specific features are firstly extracted from raw features and fused to obtain fusion view features according to view importance. To mitigate the interference of view-private information, specific view and fusion view semantic features are learned by cluster-level contrastive learning and concatenated to measure the semantic similarity of instances. By minimizing instance-level contrastive loss weighted by semantic similarity, DCMCS adaptively weakens contrastive leaning between false negative pairs. Experimental results on several public datasets demonstrate the proposed framework outperforms the state-of-the-art methods.
PTGCF: Printing Texture Guided Color Fusion for Impressionism Oil Painting Style Rendering
Jul 27, 2022


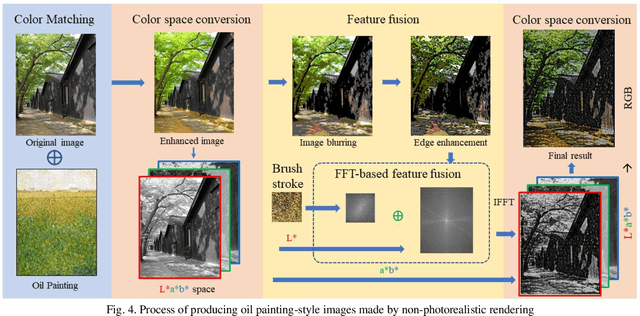
As a major branch of Non-Photorealistic Rendering (NPR), image stylization mainly uses the computer algorithms to render a photo into an artistic painting. Recent work has shown that the extraction of style information such as stroke texture and color of the target style image is the key to image stylization. Given its stroke texture and color characteristics, a new stroke rendering method is proposed, which fully considers the tonal characteristics and the representative color of the original oil painting, in order to fit the tone of the original oil painting image into the stylized image and make it close to the artist's creative effect. The experiments have validated the efficacy of the proposed model. This method would be more suitable for the works of pointillism painters with a relatively uniform sense of direction, especially for natural scenes. When the original painting brush strokes have a clearer sense of direction, using this method to simulate brushwork texture features can be less satisfactory.
Preprocessing Enhanced Image Compression for Machine Vision
Jun 12, 2022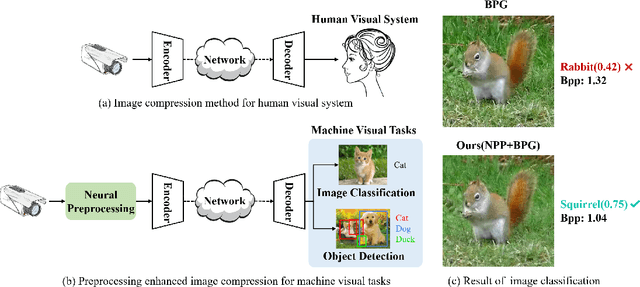
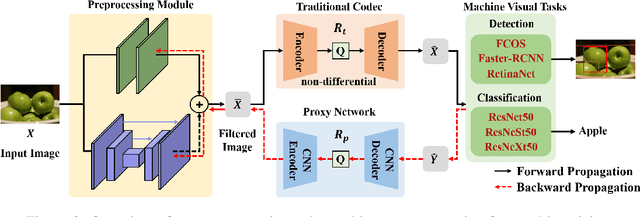

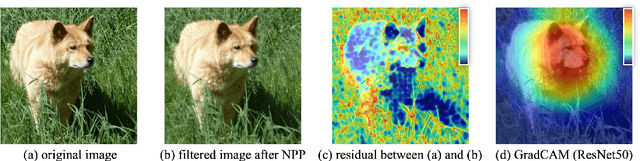
Recently, more and more images are compressed and sent to the back-end devices for the machine analysis tasks~(\textit{e.g.,} object detection) instead of being purely watched by humans. However, most traditional or learned image codecs are designed to minimize the distortion of the human visual system without considering the increased demand from machine vision systems. In this work, we propose a preprocessing enhanced image compression method for machine vision tasks to address this challenge. Instead of relying on the learned image codecs for end-to-end optimization, our framework is built upon the traditional non-differential codecs, which means it is standard compatible and can be easily deployed in practical applications. Specifically, we propose a neural preprocessing module before the encoder to maintain the useful semantic information for the downstream tasks and suppress the irrelevant information for bitrate saving. Furthermore, our neural preprocessing module is quantization adaptive and can be used in different compression ratios. More importantly, to jointly optimize the preprocessing module with the downstream machine vision tasks, we introduce the proxy network for the traditional non-differential codecs in the back-propagation stage. We provide extensive experiments by evaluating our compression method for two representative downstream tasks with different backbone networks. Experimental results show our method achieves a better trade-off between the coding bitrate and the performance of the downstream machine vision tasks by saving about 20% bitrate.
Shaking Force Balancing of the Orthoglide
Nov 13, 2020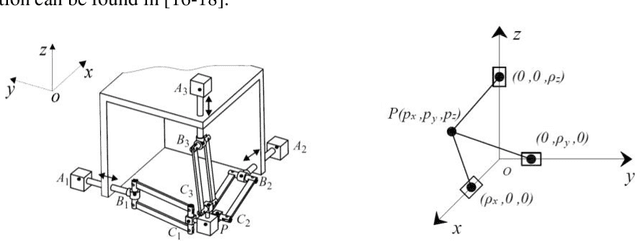
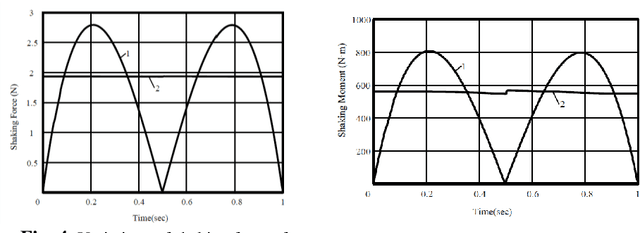

The shaking force balancing is a well-known problem in the design of high-speed robotic systems because the variable dynamic loads cause noises, wear and fatigue of mechanical structures. Different solutions, for full or partial shaking force balancing, via internal mass redistribution or by adding auxiliary links were developed. The paper deals with the shaking force balancing of the Orthoglide. The suggested solution based on the optimal acceleration control of the manipulator's common center of mass allows a significant reduction of the shaking force. Compared with the balancing method via adding counterweights or auxiliary substructures, the proposed method can avoid some drawbacks: the increase of the total mass, the overall size and the complexity of the mechanism, which become especially challenging for special parallel manipulators. Using the proposed motion control method, the maximal value of the total mass center acceleration is reduced, as a consequence, the shaking force of the manipulator decreases. The efficiency of the suggested method via numerical simulations carried out with ADAMS is demonstrated.