 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Aligning Draft Models via Parameter- and Data-Efficient Adaptation
Mar 10, 2026Speculative decoding accelerates LLM inference but suffers from performance degradation when target models are fine-tuned for specific domains. A naive solution is to retrain draft models for every target model, which is costly and inefficient. To address this, we introduce a parameter- and data-efficient framework named Efficient Draft Adaptation, abbreviated as EDA, for efficiently adapting draft models. EDA introduces three innovations: (1) a decoupled architecture that utilizes shared and private components to model the shared and target-specific output distributions separately, enabling parameter-efficient adaptation by updating only the lightweight private component;(2) a data regeneration strategy that utilizes the fine-tuned target model to regenerate training data, thereby improving the alignment between training and speculative decoding, leading to higher average acceptance length;(3) a sample selection mechanism that prioritizes high-value data for efficient adaptation. Our experiments show that EDA effectively restores speculative performance on fine-tuned models, achieving superior average acceptance lengths with significantly reduced training costs compared to full retraining. Code is available at https://github.com/Lyn-Lucy/Efficient-Draft-Adaptation.
STMI: Segmentation-Guided Token Modulation with Cross-Modal Hypergraph Interaction for Multi-Modal Object Re-Identification
Feb 28, 2026Multi-modal object Re-Identification (ReID) aims to exploit complementary information from different modalities to retrieve specific objects. However, existing methods often rely on hard token filtering or simple fusion strategies, which can lead to the loss of discriminative cues and increased background interference. To address these challenges, we propose STMI, a novel multi-modal learning framework consisting of three key components: (1) Segmentation-Guided Feature Modulation (SFM) module leverages SAM-generated masks to enhance foreground representations and suppress background noise through learnable attention modulation; (2) Semantic Token Reallocation (STR) module employs learnable query tokens and an adaptive reallocation mechanism to extract compact and informative representations without discarding any tokens; (3) Cross-Modal Hypergraph Interaction (CHI) module constructs a unified hypergraph across modalities to capture high-order semantic relationships. Extensive experiments on public benchmarks (i.e., RGBNT201, RGBNT100, and MSVR310) demonstrate the effectiveness and robustness of our proposed STMI framework in multi-modal ReID scenarios.
Generative Video Compression: Towards 0.01% Compression Rate for Video Transmission
Dec 30, 2025Whether a video can be compressed at an extreme compression rate as low as 0.01%? To this end, we achieve the compression rate as 0.02% at some cases by introducing Generative Video Compression (GVC), a new framework that redefines the limits of video compression by leveraging modern generative video models to achieve extreme compression rates while preserving a perception-centric, task-oriented communication paradigm, corresponding to Level C of the Shannon-Weaver model. Besides, How we trade computation for compression rate or bandwidth? GVC answers this question by shifting the burden from transmission to inference: it encodes video into extremely compact representations and delegates content reconstruction to the receiver, where powerful generative priors synthesize high-quality video from minimal transmitted information. Is GVC practical and deployable? To ensure practical deployment, we propose a compression-computation trade-off strategy, enabling fast inference on consume-grade GPUs. Within the AI Flow framework, GVC opens new possibility for video communication in bandwidth- and resource-constrained environments such as emergency rescue, remote surveillance, and mobile edge computing. Through empirical validation, we demonstrate that GVC offers a viable path toward a new effective, efficient, scalable, and practical video communication paradigm.
Beyond Heuristics: A Decision-Theoretic Framework for Agent Memory Management
Dec 25, 2025External memory is a key component of modern large language model (LLM) systems, enabling long-term interaction and personalization. Despite its importance, memory management is still largely driven by hand-designed heuristics, offering little insight into the long-term and uncertain consequences of memory decisions. In practice, choices about what to read or write shape future retrieval and downstream behavior in ways that are difficult to anticipate. We argue that memory management should be viewed as a sequential decision-making problem under uncertainty, where the utility of memory is delayed and dependent on future interactions. To this end, we propose DAM (Decision-theoretic Agent Memory), a decision-theoretic framework that decomposes memory management into immediate information access and hierarchical storage maintenance. Within this architecture, candidate operations are evaluated via value functions and uncertainty estimators, enabling an aggregate policy to arbitrate decisions based on estimated long-term utility and risk. Our contribution is not a new algorithm, but a principled reframing that clarifies the limitations of heuristic approaches and provides a foundation for future research on uncertainty-aware memory systems.
SmartFreeEdit: Mask-Free Spatial-Aware Image Editing with Complex Instruction Understanding
Apr 17, 2025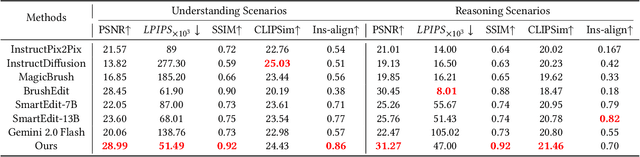

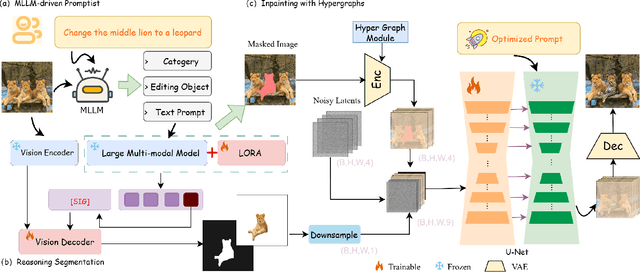
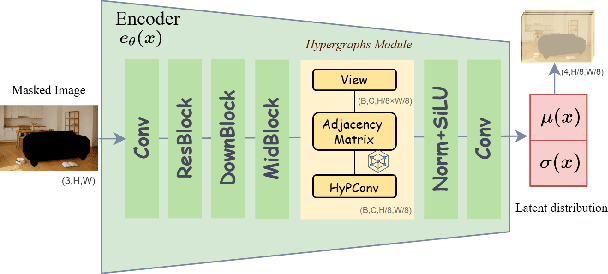
Recent advancements in image editing have utilized large-scale multimodal models to enable intuitive, natural instruction-driven interactions. However, conventional methods still face significant challenges, particularly in spatial reasoning, precise region segmentation, and maintaining semantic consistency, especially in complex scenes. To overcome these challenges, we introduce SmartFreeEdit, a novel end-to-end framework that integrates a multimodal large language model (MLLM) with a hypergraph-enhanced inpainting architecture, enabling precise, mask-free image editing guided exclusively by natural language instructions. The key innovations of SmartFreeEdit include:(1)the introduction of region aware tokens and a mask embedding paradigm that enhance the spatial understanding of complex scenes;(2) a reasoning segmentation pipeline designed to optimize the generation of editing masks based on natural language instructions;and (3) a hypergraph-augmented inpainting module that ensures the preservation of both structural integrity and semantic coherence during complex edits, overcoming the limitations of local-based image generation. Extensive experiments on the Reason-Edit benchmark demonstrate that SmartFreeEdit surpasses current state-of-the-art methods across multiple evaluation metrics, including segmentation accuracy, instruction adherence, and visual quality preservation, while addressing the issue of local information focus and improving global consistency in the edited image. Our project will be available at https://github.com/smileformylove/SmartFreeEdit.
Rethinking Learned Image Compression: Context is All You Need
Jul 16, 2024Since LIC has made rapid progress recently compared to traditional methods, this paper attempts to discuss the question about 'Where is the boundary of Learned Image Compression(LIC)?' with regard to subjective matrics. Thus this paper splits the above problem into two sub-problems:1)Where is the boundary of rate-distortion performance of PSNR? 2)How to further improve the compression gain and achieve the boundary? Therefore this paper analyzes the effectiveness of scaling parameters for encoder, decoder and context model, which are the three components of LIC. Then we conclude that scaling for LIC is to scale for context model and decoder within LIC. Extensive experiments demonstrate that overfitting can actually serve as an effective context. By optimizing the context, this paper further improves PSNR and achieves state-of-the-art performance, showing a performance gain of 14.39% with BD-RATE over VVC.
Compressible and Searchable: AI-native Multi-Modal Retrieval System with Learned Image Compression
Apr 16, 2024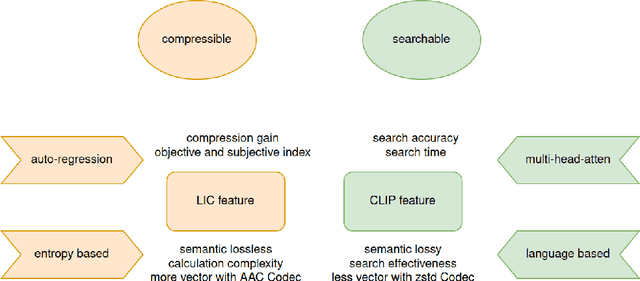
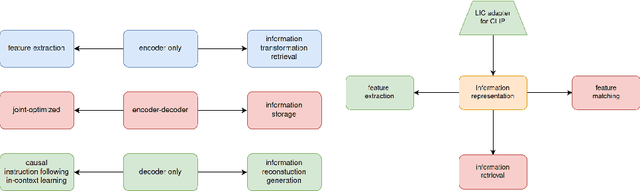

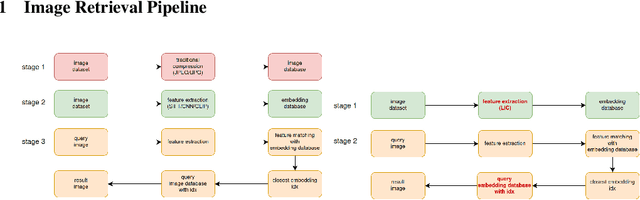
The burgeoning volume of digital content across diverse modalities necessitates efficient storage and retrieval methods. Conventional approaches struggle to cope with the escalating complexity and scale of multimedia data. In this paper, we proposed framework addresses this challenge by fusing AI-native multi-modal search capabilities with neural image compression. First we analyze the intricate relationship between compressibility and searchability, recognizing the pivotal role each plays in the efficiency of storage and retrieval systems. Through the usage of simple adapter is to bridge the feature of Learned Image Compression(LIC) and Contrastive Language-Image Pretraining(CLIP) while retaining semantic fidelity and retrieval of multi-modal data. Experimental evaluations on Kodak datasets demonstrate the efficacy of our approach, showcasing significant enhancements in compression efficiency and search accuracy compared to existing methodologies. Our work marks a significant advancement towards scalable and efficient multi-modal search systems in the era of big data.
Task-Aware Encoder Control for Deep Video Compression
Apr 07, 2024



Prior research on deep video compression (DVC) for machine tasks typically necessitates training a unique codec for each specific task, mandating a dedicated decoder per task. In contrast, traditional video codecs employ a flexible encoder controller, enabling the adaptation of a single codec to different tasks through mechanisms like mode prediction. Drawing inspiration from this, we introduce an innovative encoder controller for deep video compression for machines. This controller features a mode prediction and a Group of Pictures (GoP) selection module. Our approach centralizes control at the encoding stage, allowing for adaptable encoder adjustments across different tasks, such as detection and tracking, while maintaining compatibility with a standard pre-trained DVC decoder. Empirical evidence demonstrates that our method is applicable across multiple tasks with various existing pre-trained DVCs. Moreover, extensive experiments demonstrate that our method outperforms previous DVC by about 25% bitrate for different tasks, with only one pre-trained decoder.
Super-High-Fidelity Image Compression via Hierarchical-ROI and Adaptive Quantization
Mar 19, 2024



Learned Image Compression (LIC) has achieved dramatic progress regarding objective and subjective metrics. MSE-based models aim to improve objective metrics while generative models are leveraged to improve visual quality measured by subjective metrics. However, they all suffer from blurring or deformation at low bit rates, especially at below $0.2bpp$. Besides, deformation on human faces and text is unacceptable for visual quality assessment, and the problem becomes more prominent on small faces and text. To solve this problem, we combine the advantage of MSE-based models and generative models by utilizing region of interest (ROI). We propose Hierarchical-ROI (H-ROI), to split images into several foreground regions and one background region to improve the reconstruction of regions containing faces, text, and complex textures. Further, we propose adaptive quantization by non-linear mapping within the channel dimension to constrain the bit rate while maintaining the visual quality. Exhaustive experiments demonstrate that our methods achieve better visual quality on small faces and text with lower bit rates, e.g., $0.7X$ bits of HiFiC and $0.5X$ bits of BPG.
Unified learning-based lossy and lossless JPEG recompression
Dec 05, 2023
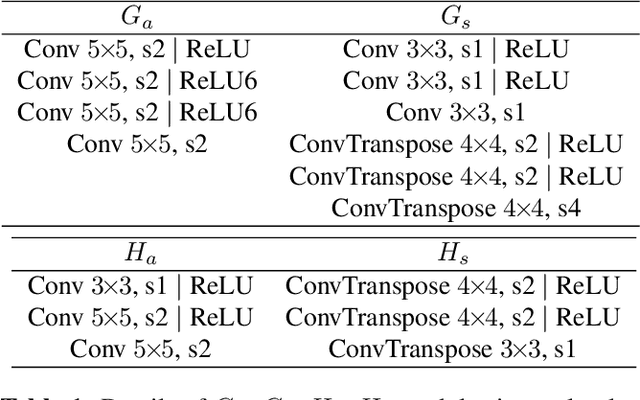
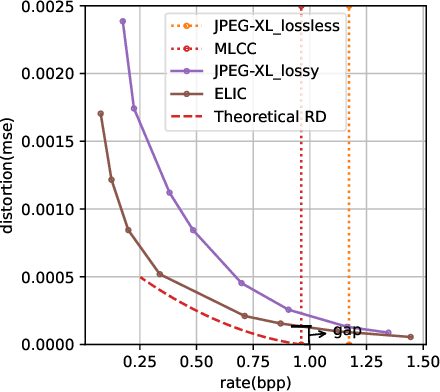
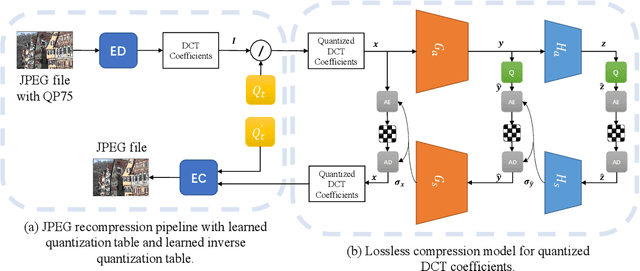
JPEG is still the most widely used image compression algorithm. Most image compression algorithms only consider uncompressed original image, while ignoring a large number of already existing JPEG images. Recently, JPEG recompression approaches have been proposed to further reduce the size of JPEG files. However, those methods only consider JPEG lossless recompression, which is just a special case of the rate-distortion theorem. In this paper, we propose a unified lossly and lossless JPEG recompression framework, which consists of learned quantization table and Markovian hierarchical variational autoencoders. Experiments show that our method can achieve arbitrarily low distortion when the bitrate is close to the upper bound, namely the bitrate of the lossless compression model. To the best of our knowledge, this is the first learned method that bridges the gap between lossy and lossless recompression of JPEG images.