 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacial Attractiveness Prediction in Live Streaming: A New Benchmark and Multi-modal Method
Jan 05, 2025



Facial attractiveness prediction (FAP) has long been an important computer vision task, which could be widely applied in live streaming for facial retouching, content recommendation, etc. However, previous FAP datasets are either small, closed-source, or lack diversity. Moreover, the corresponding FAP models exhibit limited generalization and adaptation ability. To overcome these limitations, in this paper we present LiveBeauty, the first large-scale live-specific FAP dataset, in a more challenging application scenario, i.e., live streaming. 10,000 face images are collected from a live streaming platform directly, with 200,000 corresponding attractiveness annotations obtained from a well-devised subjective experiment, making LiveBeauty the largest open-access FAP dataset in the challenging live scenario. Furthermore, a multi-modal FAP method is proposed to measure the facial attractiveness in live streaming. Specifically, we first extract holistic facial prior knowledge and multi-modal aesthetic semantic features via a Personalized Attractiveness Prior Module (PAPM) and a Multi-modal Attractiveness Encoder Module (MAEM), respectively, then integrate the extracted features through a Cross-Modal Fusion Module (CMFM). Extensive experiments conducted on both LiveBeauty and other open-source FAP datasets demonstrate that our proposed method achieves state-of-the-art performance. Dataset will be available soon.
Evaluating the Practicality of Learned Image Compression
Jul 29, 2022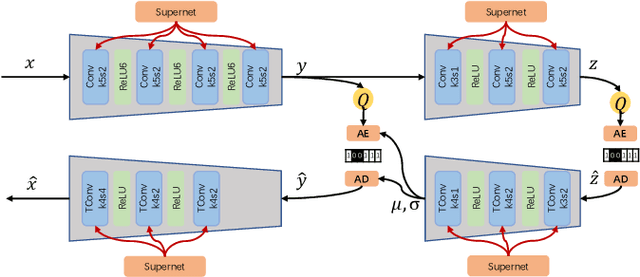
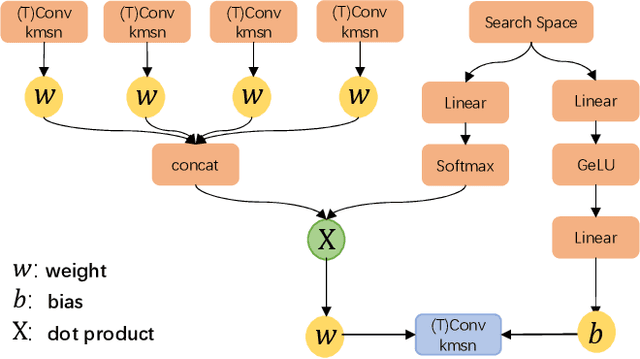
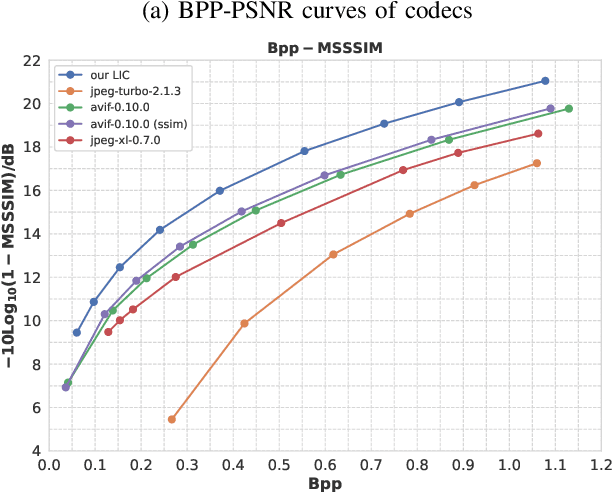
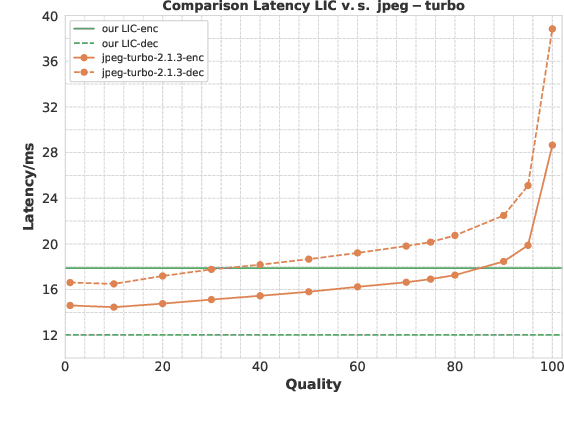
Learned image compression has achieved extraordinary rate-distortion performance in PSNR and MS-SSIM compared to traditional methods. However, it suffers from intensive computation, which is intolerable for real-world applications and leads to its limited industrial application for now. In this paper, we introduce neural architecture search (NAS) to designing more efficient networks with lower latency, and leverage quantization to accelerate the inference process. Meanwhile, efforts in engineering like multi-threading and SIMD have been made to improve efficiency. Optimized using a hybrid loss of PSNR and MS-SSIM for better visual quality, we obtain much higher MS-SSIM than JPEG, JPEG XL and AVIF over all bit rates, and PSNR between that of JPEG XL and AVIF. Our software implementation of LIC achieves comparable or even faster inference speed compared to jpeg-turbo while being multiple times faster than JPEG XL and AVIF. Besides, our implementation of LIC reaches stunning throughput of 145 fps for encoding and 208 fps for decoding on a Tesla T4 GPU for 1080p images. On CPU, the latency of our implementation is comparable with JPEG XL.
PO-ELIC: Perception-Oriented Efficient Learned Image Coding
May 28, 2022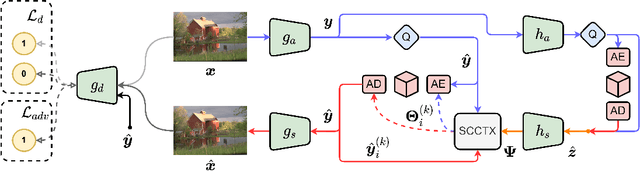


In the past years, learned image compression (LIC) has achieved remarkable performance. The recent LIC methods outperform VVC in both PSNR and MS-SSIM. However, the low bit-rate reconstructions of LIC suffer from artifacts such as blurring, color drifting and texture missing. Moreover, those varied artifacts make image quality metrics correlate badly with human perceptual quality. In this paper, we propose PO-ELIC, i.e., Perception-Oriented Efficient Learned Image Coding. To be specific, we adapt ELIC, one of the state-of-the-art LIC models, with adversarial training techniques. We apply a mixture of losses including hinge-form adversarial loss, Charbonnier loss, and style loss, to finetune the model towards better perceptual quality. Experimental results demonstrate that our method achieves comparable perceptual quality with HiFiC with much lower bitrate.