 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning More from Less: Unlocking Internal Representations for Benchmark Compression
Feb 03, 2026The prohibitive cost of evaluating Large Language Models (LLMs) necessitates efficient alternatives to full-scale benchmarking. Prevalent approaches address this by identifying a small coreset of items to approximate full-benchmark performance. However, existing methods must estimate a reliable item profile from response patterns across many source models, which becomes statistically unstable when the source pool is small. This dependency is particularly limiting for newly released benchmarks with minimal historical evaluation data. We argue that discrete correctness labels are a lossy view of the model's decision process and fail to capture information encoded in hidden states. To address this, we introduce REPCORE, which aligns heterogeneous hidden states into a unified latent space to construct representative coresets. Using these subsets for performance extrapolation, REPCORE achieves precise estimation accuracy with as few as ten source models. Experiments on five benchmarks and over 200 models show consistent gains over output-based baselines in ranking correlation and estimation accuracy. Spectral analysis further indicates that the aligned representations contain separable components reflecting broad response tendencies and task-specific reasoning patterns.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
Exploring Semantic-constrained Adversarial Example with Instruction Uncertainty Reduction
Oct 27, 2025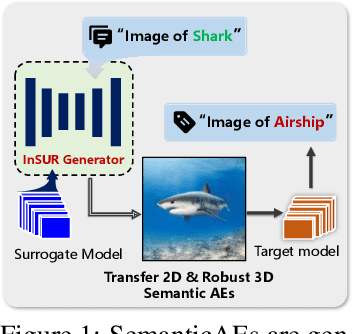
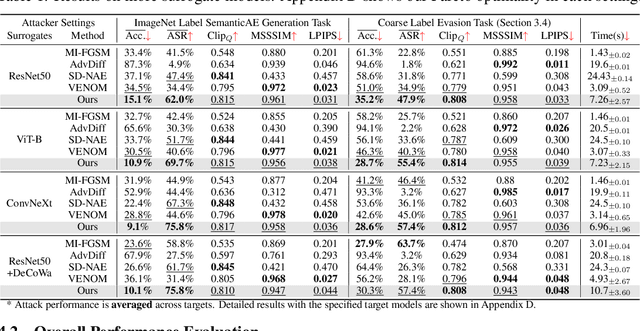
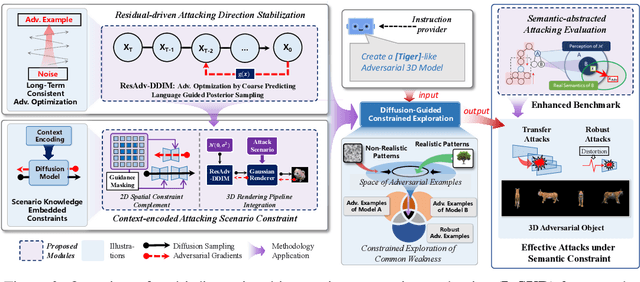

Recently, semantically constrained adversarial examples (SemanticAE), which are directly generated from natural language instructions, have become a promising avenue for future research due to their flexible attacking forms. To generate SemanticAEs, current methods fall short of satisfactory attacking ability as the key underlying factors of semantic uncertainty in human instructions, such as referring diversity, descriptive incompleteness, and boundary ambiguity, have not been fully investigated. To tackle the issues, this paper develops a multi-dimensional instruction uncertainty reduction (InSUR) framework to generate more satisfactory SemanticAE, i.e., transferable, adaptive, and effective. Specifically, in the dimension of the sampling method, we propose the residual-driven attacking direction stabilization to alleviate the unstable adversarial optimization caused by the diversity of language references. By coarsely predicting the language-guided sampling process, the optimization process will be stabilized by the designed ResAdv-DDIM sampler, therefore releasing the transferable and robust adversarial capability of multi-step diffusion models. In task modeling, we propose the context-encoded attacking scenario constraint to supplement the missing knowledge from incomplete human instructions. Guidance masking and renderer integration are proposed to regulate the constraints of 2D/3D SemanticAE, activating stronger scenario-adapted attacks. Moreover, in the dimension of generator evaluation, we propose the semantic-abstracted attacking evaluation enhancement by clarifying the evaluation boundary, facilitating the development of more effective SemanticAE generators. Extensive experiments demonstrate the superiority of the transfer attack performance of InSUR. Moreover, we realize the reference-free generation of semantically constrained 3D adversarial examples for the first time.
NTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
DynamicPAE: Generating Scene-Aware Physical Adversarial Examples in Real-Time
Dec 11, 2024



Physical adversarial examples (PAEs) are regarded as "whistle-blowers" of real-world risks in deep-learning applications. However, current PAE generation studies show limited adaptive attacking ability to diverse and varying scenes. The key challenges in generating dynamic PAEs are exploring their patterns under noisy gradient feedback and adapting the attack to agnostic scenario natures. To address the problems, we present DynamicPAE, the first generative framework that enables scene-aware real-time physical attacks beyond static attacks. Specifically, to train the dynamic PAE generator under noisy gradient feedback, we introduce the residual-driven sample trajectory guidance technique, which redefines the training task to break the limited feedback information restriction that leads to the degeneracy problem. Intuitively, it allows the gradient feedback to be passed to the generator through a low-noise auxiliary task, thereby guiding the optimization away from degenerate solutions and facilitating a more comprehensive and stable exploration of feasible PAEs. To adapt the generator to agnostic scenario natures, we introduce the context-aligned scene expectation simulation process, consisting of the conditional-uncertainty-aligned data module and the skewness-aligned objective re-weighting module. The former enhances robustness in the context of incomplete observation by employing a conditional probabilistic model for domain randomization, while the latter facilitates consistent stealth control across different attack targets by automatically reweighting losses based on the skewness indicator. Extensive digital and physical evaluations demonstrate the superior attack performance of DynamicPAE, attaining a 1.95 $\times$ boost (65.55% average AP drop under attack) on representative object detectors (e.g., Yolo-v8) over state-of-the-art static PAE generating methods.
ShadowHack: Hacking Shadows via Luminance-Color Divide and Conquer
Dec 03, 2024
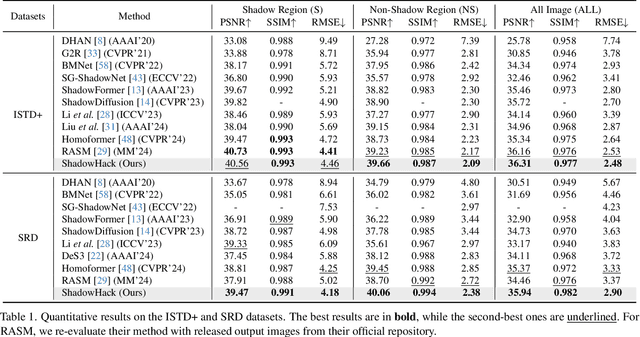
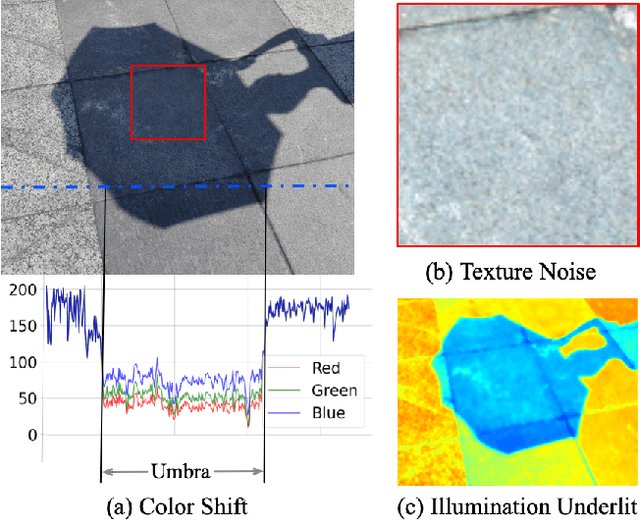
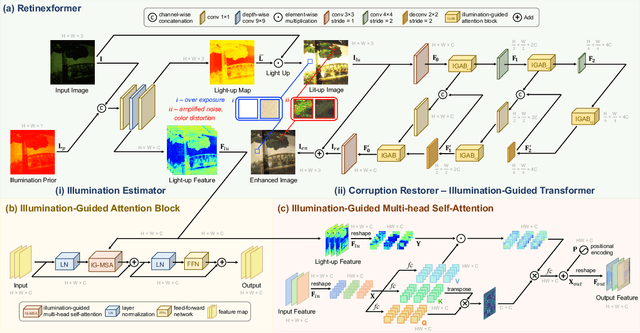
Shadows introduce challenges such as reduced brightness, texture deterioration, and color distortion in images, complicating a holistic solution. This study presents \textbf{ShadowHack}, a divide-and-conquer strategy that tackles these complexities by decomposing the original task into luminance recovery and color remedy. To brighten shadow regions and repair the corrupted textures in the luminance space, we customize LRNet, a U-shaped network with a rectified outreach attention module, to enhance information interaction and recalibrate contaminated attention maps. With luminance recovered, CRNet then leverages cross-attention mechanisms to revive vibrant colors, producing visually compelling results. Extensive experiments on multiple datasets are conducted to demonstrate the superiority of ShadowHack over existing state-of-the-art solutions both quantitatively and qualitatively, highlighting the effectiveness of our design. Our code will be made publicly available at https://github.com/lime-j/ShadowHack
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024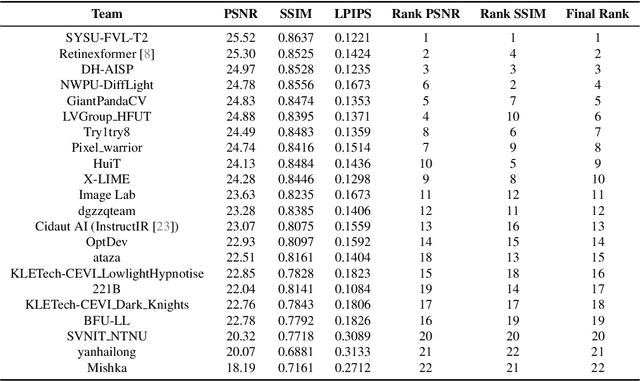


This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
Adversarial Examples in the Physical World: A Survey
Nov 01, 2023Deep neural networks (DNNs) have demonstrated high vulnerability to adversarial examples. Besides the attacks in the digital world, the practical implications of adversarial examples in the physical world present significant challenges and safety concerns. However, current research on physical adversarial examples (PAEs) lacks a comprehensive understanding of their unique characteristics, leading to limited significance and understanding. In this paper, we address this gap by thoroughly examining the characteristics of PAEs within a practical workflow encompassing training, manufacturing, and re-sampling processes. By analyzing the links between physical adversarial attacks, we identify manufacturing and re-sampling as the primary sources of distinct attributes and particularities in PAEs. Leveraging this knowledge, we develop a comprehensive analysis and classification framework for PAEs based on their specific characteristics, covering over 100 studies on physical-world adversarial examples. Furthermore, we investigate defense strategies against PAEs and identify open challenges and opportunities for future research. We aim to provide a fresh, thorough, and systematic understanding of PAEs, thereby promoting the development of robust adversarial learning and its application in open-world scenarios.
Evaluating the Practicality of Learned Image Compression
Jul 29, 2022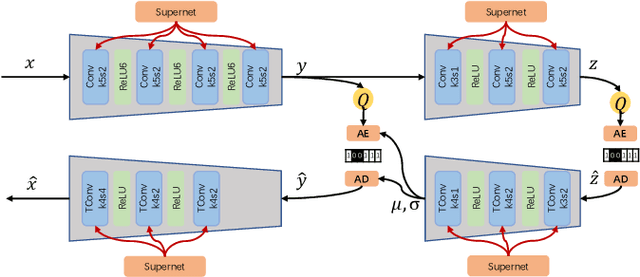
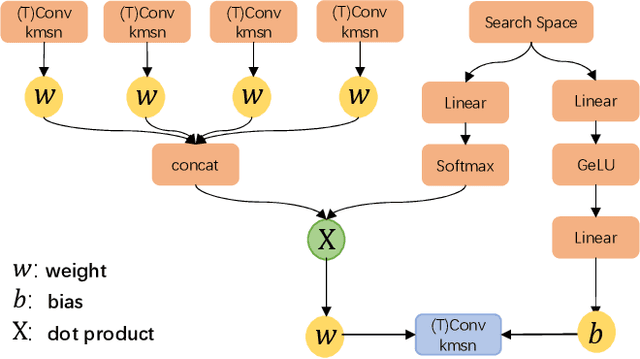
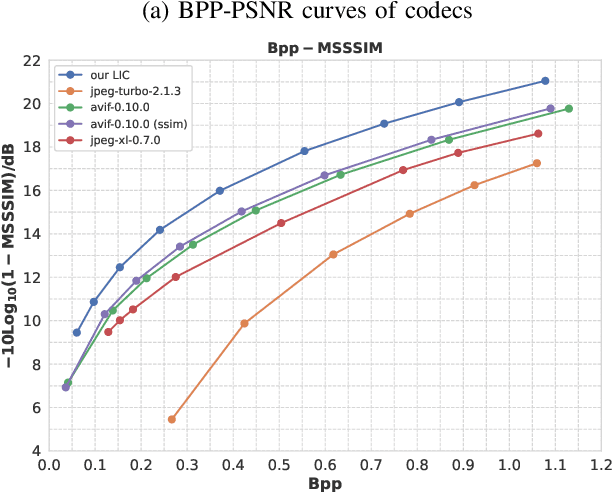
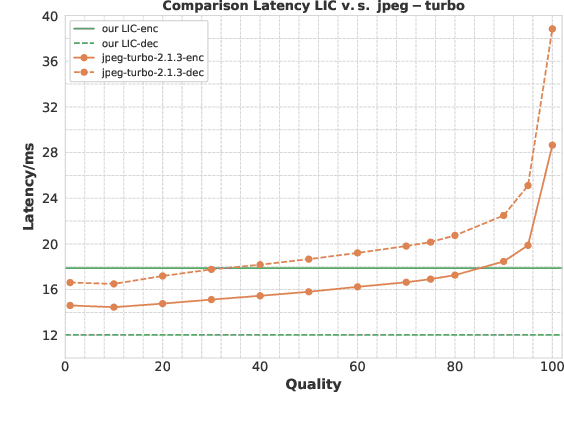
Learned image compression has achieved extraordinary rate-distortion performance in PSNR and MS-SSIM compared to traditional methods. However, it suffers from intensive computation, which is intolerable for real-world applications and leads to its limited industrial application for now. In this paper, we introduce neural architecture search (NAS) to designing more efficient networks with lower latency, and leverage quantization to accelerate the inference process. Meanwhile, efforts in engineering like multi-threading and SIMD have been made to improve efficiency. Optimized using a hybrid loss of PSNR and MS-SSIM for better visual quality, we obtain much higher MS-SSIM than JPEG, JPEG XL and AVIF over all bit rates, and PSNR between that of JPEG XL and AVIF. Our software implementation of LIC achieves comparable or even faster inference speed compared to jpeg-turbo while being multiple times faster than JPEG XL and AVIF. Besides, our implementation of LIC reaches stunning throughput of 145 fps for encoding and 208 fps for decoding on a Tesla T4 GPU for 1080p images. On CPU, the latency of our implementation is comparable with JPEG XL.