 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailWAM: Jailbreaking World Action Models in Robot Control
Apr 07, 2026The World Action Model (WAM) can jointly predict future world states and actions, exhibiting stronger physical manipulation capabilities compared with traditional models. Such powerful physical interaction ability is a double-edged sword: if safety is ignored, it will directly threaten personal safety, property security and environmental safety. However, existing research pays extremely limited attention to the critical security gap: the vulnerability of WAM to jailbreak attacks. To fill this gap, we define the Three-Level Safety Classification Framework to systematically quantify the safety of robotic arm motions. Furthermore, we propose JailWAM, the first dedicated jailbreak attack and evaluation framework for WAM, which consists of three core components: (1) Visual-Trajectory Mapping, which unifies heterogeneous action spaces into visual trajectory representations and enables cross-architectural unified evaluation; (2) Risk Discriminator, which serves as a high-recall screening tool that optimizes the efficiency-accuracy trade-off when identifying destructive behaviors in visual trajectories; (3) Dual-Path Verification Strategy, which first conducts rapid coarse screening via a single-image-based video-action generation module, and then performs efficient and comprehensive verification through full closed-loop physical simulation. In addition, we construct JailWAM-Bench, a benchmark for comprehensively evaluating the safety alignment performance of WAM under jailbreak attacks. Experiments in RoboTwin simulation environment demonstrate that the proposed framework efficiently exposes physical vulnerabilities, achieving an 84.2% attack success rate on the state-of-the-art LingBot-VA. Meanwhile, robust defense mechanisms can be constructed based on JailWAM, providing an effective technical solution for designing safe and reliable robot control systems.
Revealing Physical-World Semantic Vulnerabilities: Universal Adversarial Patches for Infrared Vision-Language Models
Apr 03, 2026Infrared vision-language models (IR-VLMs) have emerged as a promising paradigm for multimodal perception in low-visibility environments, yet their robustness to adversarial attacks remains largely unexplored. Existing adversarial patch methods are mainly designed for RGB-based models in closed-set settings and are not readily applicable to the open-ended semantic understanding and physical deployment requirements of infrared VLMs. To bridge this gap, we propose Universal Curved-Grid Patch (UCGP), a universal physical adversarial patch framework for IR-VLMs. UCGP integrates Curved-Grid Mesh (CGM) parameterization for continuous, low-frequency, and deployable patch generation with a unified representation-driven objective that promotes subspace departure, topology disruption, and stealth. To improve robustness under real-world deployment and domain shift, we further incorporate Meta Differential Evolution and EOT-augmented TPS deformation modeling. Rather than manipulating labels or prompts, UCGP directly disrupts the visual representation space, weakening cross-modal semantic alignment. Extensive experiments demonstrate that UCGP consistently compromises semantic understanding across diverse IR-VLM architectures while maintaining cross-model transferability, cross-dataset generalization, real-world physical effectiveness, and robustness against defenses. These findings reveal a previously overlooked robustness vulnerability in current infrared multimodal systems.
Thermally Activated Dual-Modal Adversarial Clothing against AI Surveillance Systems
Nov 17, 2025Adversarial patches have emerged as a popular privacy-preserving approach for resisting AI-driven surveillance systems. However, their conspicuous appearance makes them difficult to deploy in real-world scenarios. In this paper, we propose a thermally activated adversarial wearable designed to ensure adaptability and effectiveness in complex real-world environments. The system integrates thermochromic dyes with flexible heating units to induce visually dynamic adversarial patterns on clothing surfaces. In its default state, the clothing appears as an ordinary black T-shirt. Upon heating via an embedded thermal unit, hidden adversarial patterns on the fabric are activated, allowing the wearer to effectively evade detection across both visible and infrared modalities. Physical experiments demonstrate that the adversarial wearable achieves rapid texture activation within 50 seconds and maintains an adversarial success rate above 80\% across diverse real-world surveillance environments. This work demonstrates a new pathway toward physically grounded, user-controllable anti-AI systems, highlighting the growing importance of proactive adversarial techniques for privacy protection in the age of ubiquitous AI surveillance.
FR-Mamba: Time-Series Physical Field Reconstruction Based on State Space Model
May 21, 2025Physical field reconstruction (PFR) aims to predict the state distribution of physical quantities (e.g., velocity, pressure, and temperature) based on limited sensor measurements. It plays a critical role in domains such as fluid dynamics and thermodynamics. However, existing deep learning methods often fail to capture long-range temporal dependencies, resulting in suboptimal performance on time-evolving physical systems. To address this, we propose FR-Mamba, a novel spatiotemporal flow field reconstruction framework based on state space modeling. Specifically, we design a hybrid neural network architecture that combines Fourier Neural Operator (FNO) and State Space Model (SSM) to capture both global spatial features and long-range temporal dependencies. We adopt Mamba, a recently proposed efficient SSM architecture, to model long-range temporal dependencies with linear time complexity. In parallel, the FNO is employed to capture non-local spatial features by leveraging frequency-domain transformations. The spatiotemporal representations extracted by these two components are then fused to reconstruct the full-field distribution of the physical system. Extensive experiments demonstrate that our approach significantly outperforms existing PFR methods in flow field reconstruction tasks, achieving high-accuracy performance on long sequences.
CDUPatch: Color-Driven Universal Adversarial Patch Attack for Dual-Modal Visible-Infrared Detectors
Apr 15, 2025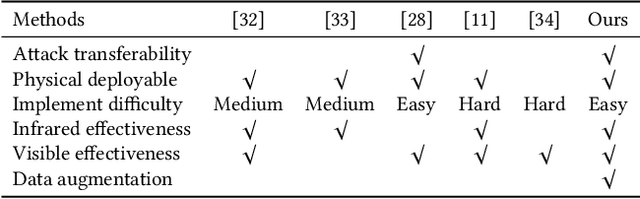
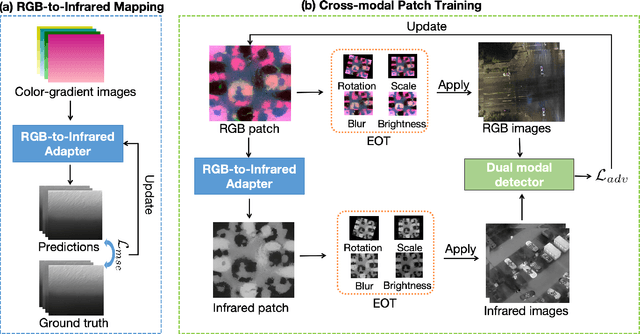


Adversarial patches are widely used to evaluate the robustness of object detection systems in real-world scenarios. These patches were initially designed to deceive single-modal detectors (e.g., visible or infrared) and have recently been extended to target visible-infrared dual-modal detectors. However, existing dual-modal adversarial patch attacks have limited attack effectiveness across diverse physical scenarios. To address this, we propose CDUPatch, a universal cross-modal patch attack against visible-infrared object detectors across scales, views, and scenarios. Specifically, we observe that color variations lead to different levels of thermal absorption, resulting in temperature differences in infrared imaging. Leveraging this property, we propose an RGB-to-infrared adapter that maps RGB patches to infrared patches, enabling unified optimization of cross-modal patches. By learning an optimal color distribution on the adversarial patch, we can manipulate its thermal response and generate an adversarial infrared texture. Additionally, we introduce a multi-scale clipping strategy and construct a new visible-infrared dataset, MSDrone, which contains aerial vehicle images in varying scales and perspectives. These data augmentation strategies enhance the robustness of our patch in real-world conditions. Experiments on four benchmark datasets (e.g., DroneVehicle, LLVIP, VisDrone, MSDrone) show that our method outperforms existing patch attacks in the digital domain. Extensive physical tests further confirm strong transferability across scales, views, and scenarios.
PapMOT: Exploring Adversarial Patch Attack against Multiple Object Tracking
Apr 12, 2025Tracking multiple objects in a continuous video stream is crucial for many computer vision tasks. It involves detecting and associating objects with their respective identities across successive frames. Despite significant progress made in multiple object tracking (MOT), recent studies have revealed the vulnerability of existing MOT methods to adversarial attacks. Nevertheless, all of these attacks belong to digital attacks that inject pixel-level noise into input images, and are therefore ineffective in physical scenarios. To fill this gap, we propose PapMOT, which can generate physical adversarial patches against MOT for both digital and physical scenarios. Besides attacking the detection mechanism, PapMOT also optimizes a printable patch that can be detected as new targets to mislead the identity association process. Moreover, we introduce a patch enhancement strategy to further degrade the temporal consistency of tracking results across video frames, resulting in more aggressive attacks. We further develop new evaluation metrics to assess the robustness of MOT against such attacks. Extensive evaluations on multiple datasets demonstrate that our PapMOT can successfully attack various architectures of MOT trackers in digital scenarios. We also validate the effectiveness of PapMOT for physical attacks by deploying printed adversarial patches in the real world.
Robust SAM: On the Adversarial Robustness of Vision Foundation Models
Apr 11, 2025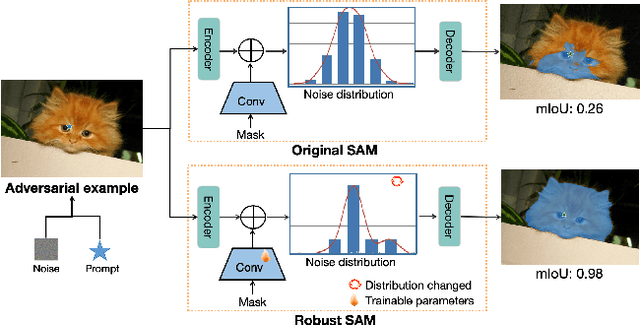
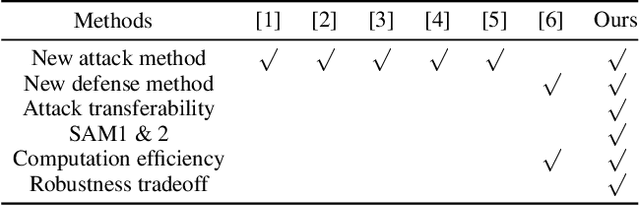
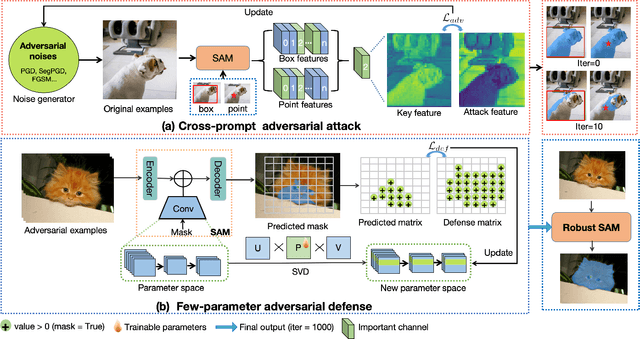
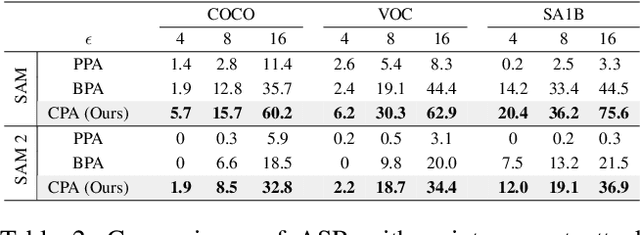
The Segment Anything Model (SAM) is a widely used vision foundation model with diverse applications, including image segmentation, detection, and tracking. Given SAM's wide applications, understanding its robustness against adversarial attacks is crucial for real-world deployment. However, research on SAM's robustness is still in its early stages. Existing attacks often overlook the role of prompts in evaluating SAM's robustness, and there has been insufficient exploration of defense methods to balance the robustness and accuracy. To address these gaps, this paper proposes an adversarial robustness framework designed to evaluate and enhance the robustness of SAM. Specifically, we introduce a cross-prompt attack method to enhance the attack transferability across different prompt types. Besides attacking, we propose a few-parameter adaptation strategy to defend SAM against various adversarial attacks. To balance robustness and accuracy, we use the singular value decomposition (SVD) to constrain the space of trainable parameters, where only singular values are adaptable. Experiments demonstrate that our cross-prompt attack method outperforms previous approaches in terms of attack success rate on both SAM and SAM 2. By adapting only 512 parameters, we achieve at least a 15\% improvement in mean intersection over union (mIoU) against various adversarial attacks. Compared to previous defense methods, our approach enhances the robustness of SAM while maximally maintaining its original performance.
Parameter-Free Fine-tuning via Redundancy Elimination for Vision Foundation Models
Apr 11, 2025Vision foundation models (VFMs) are large pre-trained models that form the backbone of various vision tasks. Fine-tuning VFMs can further unlock their potential for downstream tasks or scenarios. However, VFMs often contain significant feature redundancy, which may limit their adaptability to new tasks. In this paper, we investigate the redundancies in the segment anything model (SAM) and then propose a parameter-free fine-tuning method to address this issue. Unlike traditional fine-tuning methods that adjust parameters, our method emphasizes selecting, reusing, and enhancing pre-trained features, offering a new perspective on model fine-tuning. Specifically, we introduce a channel selection algorithm based on the model's output difference to identify redundant and effective channels. By selectively replacing the redundant channels with more effective ones, we filter out less useful features and reuse the more relevant features to downstream tasks, thereby enhancing the task-specific feature representation. Experiments on both out-of-domain and in-domain datasets demonstrate the efficiency and effectiveness of our method. Notably, our approach can seamlessly integrate with existing fine-tuning strategies (e.g., LoRA, Adapter), further boosting the performance of already fine-tuned models. Moreover, since our channel selection involves only model inference, our method significantly reduces computational and GPU memory overhead.
HeteroMorpheus: Universal Control Based on Morphological Heterogeneity Modeling
Aug 02, 2024



In the field of robotic control, designing individual controllers for each robot leads to high computational costs. Universal control policies, applicable across diverse robot morphologies, promise to mitigate this challenge. Predominantly, models based on Graph Neural Networks (GNN) and Transformers are employed, owing to their effectiveness in capturing relational dynamics across a robot's limbs. However, these models typically employ homogeneous graph structures that overlook the functional diversity of different limbs. To bridge this gap, we introduce HeteroMorpheus, a novel method based on heterogeneous graph Transformer. This method uniquely addresses limb heterogeneity, fostering better representation of robot dynamics of various morphologies. Through extensive experiments we demonstrate the superiority of HeteroMorpheus against state-of-the-art methods in the capability of policy generalization, including zero-shot generalization and sample-efficient transfer to unfamiliar robot morphologies.
Universal Multi-view Black-box Attack against Object Detectors via Layout Optimization
Jul 09, 2024



Object detectors have demonstrated vulnerability to adversarial examples crafted by small perturbations that can deceive the object detector. Existing adversarial attacks mainly focus on white-box attacks and are merely valid at a specific viewpoint, while the universal multi-view black-box attack is less explored, limiting their generalization in practice. In this paper, we propose a novel universal multi-view black-box attack against object detectors, which optimizes a universal adversarial UV texture constructed by multiple image stickers for a 3D object via the designed layout optimization algorithm. Specifically, we treat the placement of image stickers on the UV texture as a circle-based layout optimization problem, whose objective is to find the optimal circle layout filled with image stickers so that it can deceive the object detector under the multi-view scenario. To ensure reasonable placement of image stickers, two constraints are elaborately devised. To optimize the layout, we adopt the random search algorithm enhanced by the devised important-aware selection strategy to find the most appropriate image sticker for each circle from the image sticker pools. Extensive experiments conducted on four common object detectors suggested that the detection performance decreases by a large magnitude of 74.29% on average in multi-view scenarios. Additionally, a novel evaluation tool based on the photo-realistic simulator is designed to assess the texture-based attack fairly.