 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTL-FNO: A Lightweight Multi-Task Fourier Neural Operator for Sparse Field Reconstruction
May 26, 2026Efficient onboard multi-field sparse reconstruction is essential for the autonomous operation of aerospace vehicles. While existing deep learning models exhibit promise for single-field reconstruction, deploying multiple independent models leads to prohibitive model size growth and fails to exploit cross-field correlations, particularly under few-shot conditions. To address these challenges, we first propose a lightweight multi-task Fourier neural operator (MTL-FNO), an end-to-end joint training framework based on hard parameter sharing. In each layer, the parameters are divided into shared and task-specific components to capture common features across fields while preserving task-specific characteristics. Moreover, the task-specific fine-tuning parameters are implemented as low-rank terms, achieving substantial model compression. Second, to address the difficulty of co-optimizing shared and task-specific parameters along with their real and imaginary parts, we revisit the FNO's spectral weight from a polar-form perspective and devise a physically meaningful decoupled optimization scheme. Specifically, we apply polar decomposition to slice-wise disentangle the spectral weight into a unitary tensor encoding phase information and a positive semi-definite tensor characterizing amplitude. By decoupling the optimization of phase and amplitude, our method can effectively mitigate tasks conflict. Meanwhile, to preserve unitary geometric fidelity during training, the Cayley transform is introduced to reparameterize the unitary tensor, converting the constrained optimization problem to an unconstrained one. Finally, the effectiveness of the proposed method under few-shot conditions is validated on two representative engineering cases. Results show that MTL-FNO achieves accuracy comparable to or even surpassing that of standard FNO, while reducing total model size by 76% and 60%, respectively.
Vision-Language Navigation for Aerial Robots: Towards the Era of Large Language Models
Apr 09, 2026Aerial vision-and-language navigation (Aerial VLN) aims to enable unmanned aerial vehicles (UAVs) to interpret natural language instructions and autonomously navigate complex three-dimensional environments by grounding language in visual perception. This survey provides a critical and analytical review of the Aerial VLN field, with particular attention to the recent integration of large language models (LLMs) and vision-language models (VLMs). We first formally introduce the Aerial VLN problem and define two interaction paradigms: single-instruction and dialog-based, as foundational axes. We then organize the body of Aerial VLN methods into a taxonomy of five architectural categories: sequence-to-sequence and attention-based methods, end-to-end LLM/VLM methods, hierarchical methods, multi-agent methods, and dialog-based navigation methods. For each category, we systematically analyze design rationales, technical trade-offs, and reported performance. We critically assess the evaluation infrastructure for Aerial VLN, including datasets, simulation platforms, and metrics, and identify their gaps in scale, environmental diversity, real-world grounding, and metric coverage. We consolidate cross-method comparisons on shared benchmarks and analyze key architectural trade-offs, including discrete versus continuous actions, end-to-end versus hierarchical designs, and the simulation-to-reality gap. Finally, we synthesize seven concrete open problems: long-horizon instruction grounding, viewpoint robustness, scalable spatial representation, continuous 6-DoF action execution, onboard deployment, benchmark standardization, and multi-UAV swarm navigation, with specific research directions grounded in the evidence presented throughout the survey.
JailWAM: Jailbreaking World Action Models in Robot Control
Apr 07, 2026The World Action Model (WAM) can jointly predict future world states and actions, exhibiting stronger physical manipulation capabilities compared with traditional models. Such powerful physical interaction ability is a double-edged sword: if safety is ignored, it will directly threaten personal safety, property security and environmental safety. However, existing research pays extremely limited attention to the critical security gap: the vulnerability of WAM to jailbreak attacks. To fill this gap, we define the Three-Level Safety Classification Framework to systematically quantify the safety of robotic arm motions. Furthermore, we propose JailWAM, the first dedicated jailbreak attack and evaluation framework for WAM, which consists of three core components: (1) Visual-Trajectory Mapping, which unifies heterogeneous action spaces into visual trajectory representations and enables cross-architectural unified evaluation; (2) Risk Discriminator, which serves as a high-recall screening tool that optimizes the efficiency-accuracy trade-off when identifying destructive behaviors in visual trajectories; (3) Dual-Path Verification Strategy, which first conducts rapid coarse screening via a single-image-based video-action generation module, and then performs efficient and comprehensive verification through full closed-loop physical simulation. In addition, we construct JailWAM-Bench, a benchmark for comprehensively evaluating the safety alignment performance of WAM under jailbreak attacks. Experiments in RoboTwin simulation environment demonstrate that the proposed framework efficiently exposes physical vulnerabilities, achieving an 84.2% attack success rate on the state-of-the-art LingBot-VA. Meanwhile, robust defense mechanisms can be constructed based on JailWAM, providing an effective technical solution for designing safe and reliable robot control systems.
Revealing Physical-World Semantic Vulnerabilities: Universal Adversarial Patches for Infrared Vision-Language Models
Apr 03, 2026Infrared vision-language models (IR-VLMs) have emerged as a promising paradigm for multimodal perception in low-visibility environments, yet their robustness to adversarial attacks remains largely unexplored. Existing adversarial patch methods are mainly designed for RGB-based models in closed-set settings and are not readily applicable to the open-ended semantic understanding and physical deployment requirements of infrared VLMs. To bridge this gap, we propose Universal Curved-Grid Patch (UCGP), a universal physical adversarial patch framework for IR-VLMs. UCGP integrates Curved-Grid Mesh (CGM) parameterization for continuous, low-frequency, and deployable patch generation with a unified representation-driven objective that promotes subspace departure, topology disruption, and stealth. To improve robustness under real-world deployment and domain shift, we further incorporate Meta Differential Evolution and EOT-augmented TPS deformation modeling. Rather than manipulating labels or prompts, UCGP directly disrupts the visual representation space, weakening cross-modal semantic alignment. Extensive experiments demonstrate that UCGP consistently compromises semantic understanding across diverse IR-VLM architectures while maintaining cross-model transferability, cross-dataset generalization, real-world physical effectiveness, and robustness against defenses. These findings reveal a previously overlooked robustness vulnerability in current infrared multimodal systems.
$G^2$-Reader: Dual Evolving Graphs for Multimodal Document QA
Jan 29, 2026Retrieval-augmented generation is a practical paradigm for question answering over long documents, but it remains brittle for multimodal reading where text, tables, and figures are interleaved across many pages. First, flat chunking breaks document-native structure and cross-modal alignment, yielding semantic fragments that are hard to interpret in isolation. Second, even iterative retrieval can fail in long contexts by looping on partial evidence or drifting into irrelevant sections as noise accumulates, since each step is guided only by the current snippet without a persistent global search state. We introduce $G^2$-Reader, a dual-graph system, to address both issues. It evolves a Content Graph to preserve document-native structure and cross-modal semantics, and maintains a Planning Graph, an agentic directed acyclic graph of sub-questions, to track intermediate findings and guide stepwise navigation for evidence completion. On VisDoMBench across five multimodal domains, $G^2$-Reader with Qwen3-VL-32B-Instruct reaches 66.21\% average accuracy, outperforming strong baselines and a standalone GPT-5 (53.08\%).
SynergyWarpNet: Attention-Guided Cooperative Warping for Neural Portrait Animation
Dec 19, 2025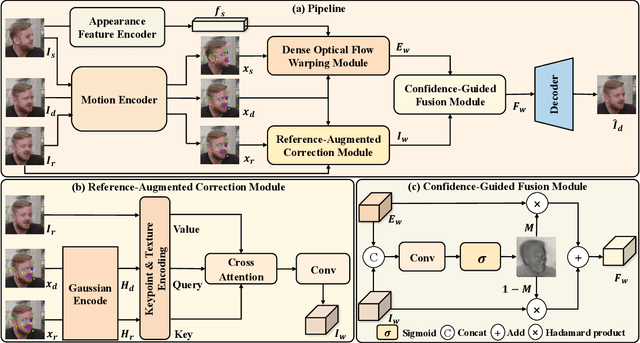
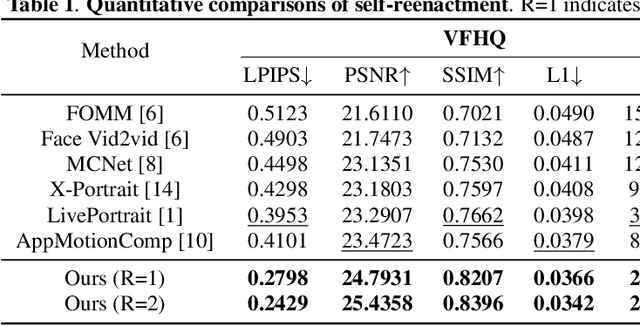

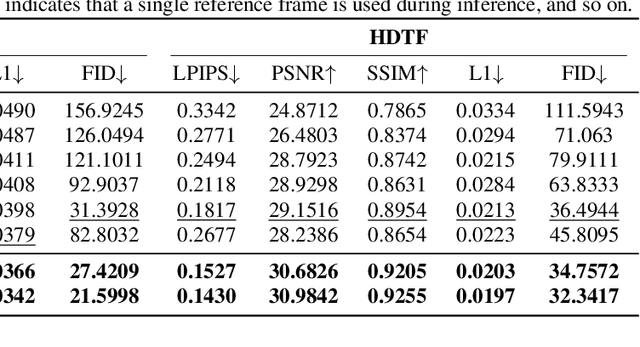
Recent advances in neural portrait animation have demonstrated remarked potential for applications in virtual avatars, telepresence, and digital content creation. However, traditional explicit warping approaches often struggle with accurate motion transfer or recovering missing regions, while recent attention-based warping methods, though effective, frequently suffer from high complexity and weak geometric grounding. To address these issues, we propose SynergyWarpNet, an attention-guided cooperative warping framework designed for high-fidelity talking head synthesis. Given a source portrait, a driving image, and a set of reference images, our model progressively refines the animation in three stages. First, an explicit warping module performs coarse spatial alignment between the source and driving image using 3D dense optical flow. Next, a reference-augmented correction module leverages cross-attention across 3D keypoints and texture features from multiple reference images to semantically complete occluded or distorted regions. Finally, a confidence-guided fusion module integrates the warped outputs with spatially-adaptive fusing, using a learned confidence map to balance structural alignment and visual consistency. Comprehensive evaluations on benchmark datasets demonstrate state-of-the-art performance.
RAVES-Calib: Robust, Accurate and Versatile Extrinsic Self Calibration Using Optimal Geometric Features
Dec 09, 2025


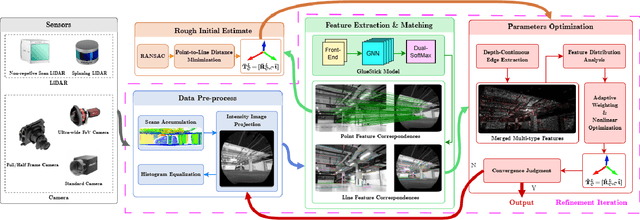
In this paper, we present a user-friendly LiDAR-camera calibration toolkit that is compatible with various LiDAR and camera sensors and requires only a single pair of laser points and a camera image in targetless environments. Our approach eliminates the need for an initial transform and remains robust even with large positional and rotational LiDAR-camera extrinsic parameters. We employ the Gluestick pipeline to establish 2D-3D point and line feature correspondences for a robust and automatic initial guess. To enhance accuracy, we quantitatively analyze the impact of feature distribution on calibration results and adaptively weight the cost of each feature based on these metrics. As a result, extrinsic parameters are optimized by filtering out the adverse effects of inferior features. We validated our method through extensive experiments across various LiDAR-camera sensors in both indoor and outdoor settings. The results demonstrate that our method provides superior robustness and accuracy compared to SOTA techniques. Our code is open-sourced on GitHub to benefit the community.
Thermally Activated Dual-Modal Adversarial Clothing against AI Surveillance Systems
Nov 17, 2025Adversarial patches have emerged as a popular privacy-preserving approach for resisting AI-driven surveillance systems. However, their conspicuous appearance makes them difficult to deploy in real-world scenarios. In this paper, we propose a thermally activated adversarial wearable designed to ensure adaptability and effectiveness in complex real-world environments. The system integrates thermochromic dyes with flexible heating units to induce visually dynamic adversarial patterns on clothing surfaces. In its default state, the clothing appears as an ordinary black T-shirt. Upon heating via an embedded thermal unit, hidden adversarial patterns on the fabric are activated, allowing the wearer to effectively evade detection across both visible and infrared modalities. Physical experiments demonstrate that the adversarial wearable achieves rapid texture activation within 50 seconds and maintains an adversarial success rate above 80\% across diverse real-world surveillance environments. This work demonstrates a new pathway toward physically grounded, user-controllable anti-AI systems, highlighting the growing importance of proactive adversarial techniques for privacy protection in the age of ubiquitous AI surveillance.
FR-Mamba: Time-Series Physical Field Reconstruction Based on State Space Model
May 21, 2025Physical field reconstruction (PFR) aims to predict the state distribution of physical quantities (e.g., velocity, pressure, and temperature) based on limited sensor measurements. It plays a critical role in domains such as fluid dynamics and thermodynamics. However, existing deep learning methods often fail to capture long-range temporal dependencies, resulting in suboptimal performance on time-evolving physical systems. To address this, we propose FR-Mamba, a novel spatiotemporal flow field reconstruction framework based on state space modeling. Specifically, we design a hybrid neural network architecture that combines Fourier Neural Operator (FNO) and State Space Model (SSM) to capture both global spatial features and long-range temporal dependencies. We adopt Mamba, a recently proposed efficient SSM architecture, to model long-range temporal dependencies with linear time complexity. In parallel, the FNO is employed to capture non-local spatial features by leveraging frequency-domain transformations. The spatiotemporal representations extracted by these two components are then fused to reconstruct the full-field distribution of the physical system. Extensive experiments demonstrate that our approach significantly outperforms existing PFR methods in flow field reconstruction tasks, achieving high-accuracy performance on long sequences.
You Only Look One Step: Accelerating Backpropagation in Diffusion Sampling with Gradient Shortcuts
May 12, 2025Diffusion models (DMs) have recently demonstrated remarkable success in modeling large-scale data distributions. However, many downstream tasks require guiding the generated content based on specific differentiable metrics, typically necessitating backpropagation during the generation process. This approach is computationally expensive, as generating with DMs often demands tens to hundreds of recursive network calls, resulting in high memory usage and significant time consumption. In this paper, we propose a more efficient alternative that approaches the problem from the perspective of parallel denoising. We show that full backpropagation throughout the entire generation process is unnecessary. The downstream metrics can be optimized by retaining the computational graph of only one step during generation, thus providing a shortcut for gradient propagation. The resulting method, which we call Shortcut Diffusion Optimization (SDO), is generic, high-performance, and computationally lightweight, capable of optimizing all parameter types in diffusion sampling. We demonstrate the effectiveness of SDO on several real-world tasks, including controlling generation by optimizing latent and aligning the DMs by fine-tuning network parameters. Compared to full backpropagation, our approach reduces computational costs by $\sim 90\%$ while maintaining superior performance. Code is available at https://github.com/deng-ai-lab/SDO.