 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Dual Process Theory in Language Agent Framework for Real-time Simultaneous Human-AI Collaboration
Feb 17, 2025Agents built on large language models (LLMs) have excelled in turn-by-turn human-AI collaboration but struggle with simultaneous tasks requiring real-time interaction. Latency issues and the challenge of inferring variable human strategies hinder their ability to make autonomous decisions without explicit instructions. Through experiments with current independent System 1 and System 2 methods, we validate the necessity of using Dual Process Theory (DPT) in real-time tasks. We propose DPT-Agent, a novel language agent framework that integrates System 1 and System 2 for efficient real-time simultaneous human-AI collaboration. DPT-Agent's System 1 uses a Finite-state Machine (FSM) and code-as-policy for fast, intuitive, and controllable decision-making. DPT-Agent's System 2 integrates Theory of Mind (ToM) and asynchronous reflection to infer human intentions and perform reasoning-based autonomous decisions. We demonstrate the effectiveness of DPT-Agent through further experiments with rule-based agents and human collaborators, showing significant improvements over mainstream LLM-based frameworks. To the best of our knowledge, DPT-Agent is the first language agent framework that achieves successful real-time simultaneous human-AI collaboration autonomously. Code of DPT-Agent can be found in https://github.com/sjtu-marl/DPT-Agent.
Man-in-the-Middle Attacks against Machine Learning Classifiers via Malicious Generative Models
Oct 14, 2019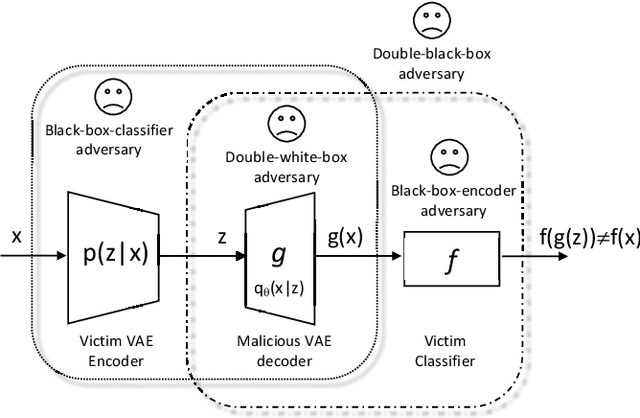

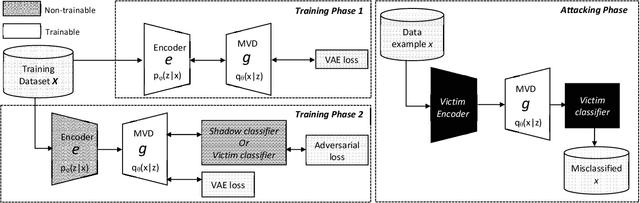

Deep Neural Networks (DNNs) are vulnerable to deliberately crafted adversarial examples. In the past few years, many efforts have been spent on exploring query-optimisation attacks to find adversarial examples of either black-box or white-box DNN models, as well as the defending countermeasures against those attacks. In this work, we explore vulnerabilities of DNN models under the umbrella of Man-in-the-Middle (MitM) attacks, which has not been investigated before. From the perspective of an MitM adversary, the aforementioned adversarial example attacks are not viable anymore. First, such attacks must acquire the outputs from the models by multiple times before actually launching attacks, which is difficult for the MitM adversary in practice. Second, such attacks are one-off and cannot be directly generalised onto new data examples, which decreases the rate of return for the attacker. In contrast, using generative models to craft adversarial examples on the fly can mitigate the drawbacks. However, the adversarial capability of the generative models, such as Variational Auto-Encoder (VAE), has not been extensively studied. Therefore, given a classifier, we investigate using a VAE decoder to either transform benign inputs to their adversarial counterparts or decode outputs from benign VAE encoders to be adversarial examples. The proposed method can endue more capability to MitM attackers. Based on our evaluation, the proposed attack can achieve above 95% success rate on both MNIST and CIFAR10 datasets, which is better or comparable with state-of-the-art query-optimisation attacks. At the meantime, the attack is 104 times faster than the query-optimisation attacks.
Daedalus: Breaking Non-Maximum Suppression in Object Detection via Adversarial Examples
Feb 06, 2019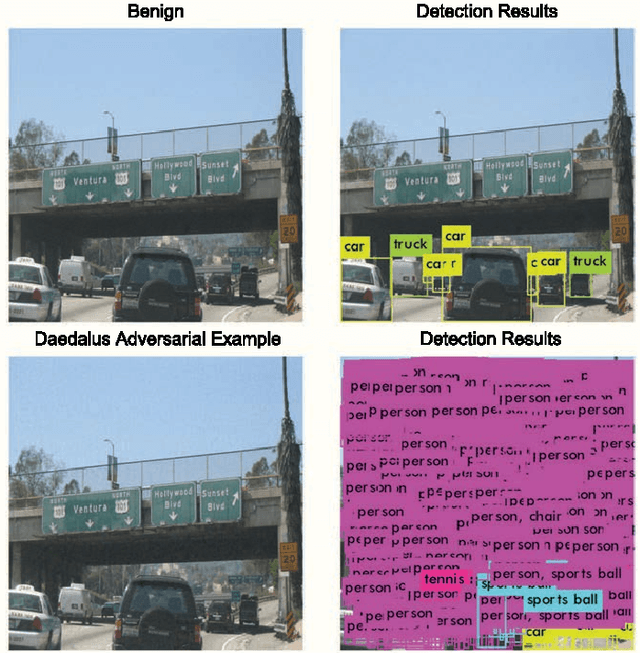
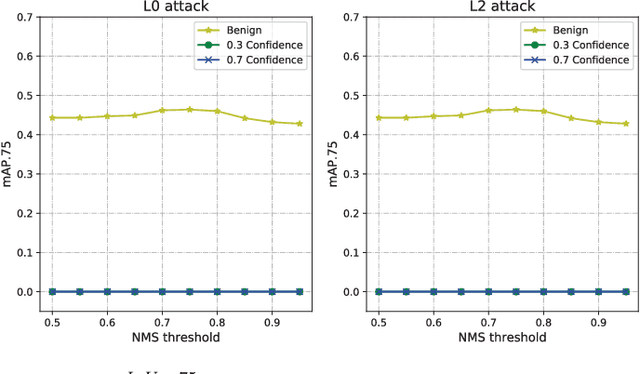


We demonstrated that Non-Maximum Suppression (NMS), which is commonly used in object detection tasks to filter redundant detection results, is no longer secure. NMS has always been an integral part of object detection algorithms. Currently, Fully Convolutional Network (FCN) is widely used as the backbone architecture of object detection models. Given an input instance, since FCN generates end-to-end detection results in a single stage, it outputs a large number of raw detection boxes. These bounding boxes are then filtered by NMS to make the final detection results. In this paper, we propose an adversarial example attack which triggers malfunctioning of NMS in the end-to-end object detection models. Our attack, namely Daedalus, manipulates the detection box regression values to compress the dimensions of detection boxes. Henceforth, NMS will no longer be able to filter redundant detection boxes correctly. And as a result, the final detection output contains extremely dense false positives. This can be fatal for many object detection applications such as autonomous vehicle and smart manufacturing industry. Our attack can be applied to different end-to-end object detection models. Furthermore, we suggest crafting robust adversarial examples by using an ensemble of popular detection models as the substitutes. Considering that model reusing is commonly seen in real-world object detection scenarios, Daedalus examples crafted based on an ensemble of substitutes can launch attacks without knowing the details of the victim models. Our experiments demonstrate that our attack effectively stops NMS from filtering redundant bounding boxes. As the evaluation results suggest, Daedalus increases the false positive rate in detection results to 99.9% and reduces the mean average precision scores to 0, while maintaining a low cost of distortion on the original inputs.
Defensive Collaborative Multi-task Training - Defending against Adversarial Attack towards Deep Neural Networks
Jul 03, 2018
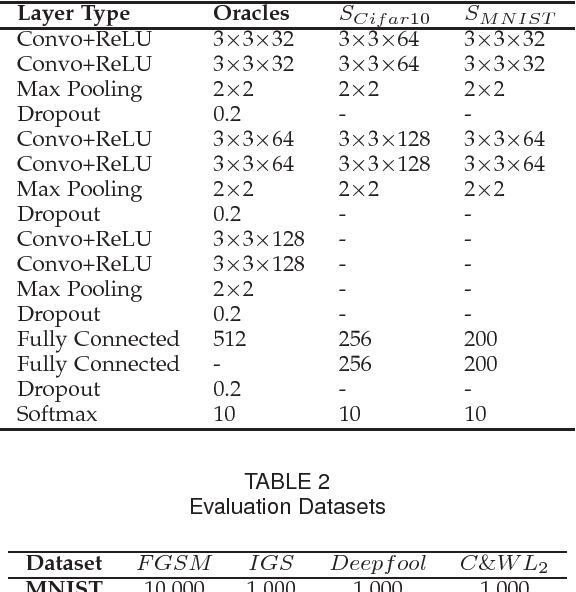
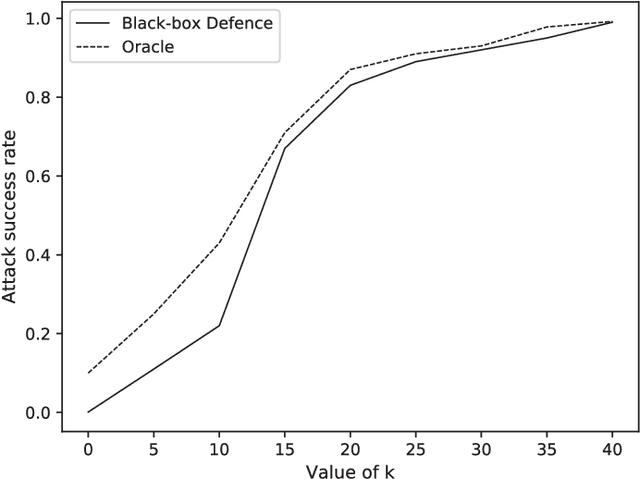

Deep neural network (DNN) has shown an impressive performance on hard perceptual problems. However, researchers found that DNN-based systems are vulnerable to adversarial examples that contain specially crafted humans-imperceptible perturbations. Such perturbations cause DNN based systems to misclassify the adversarial examples, with potentially disastrous consequences in applications where the safety or security is crucial. To address this problem, this paper proposes a novel defensive framework based on a collaborative multi-task training. The proposed defence mechanism first incorporates specific label pairs into adversarial training process to enhance the model robustness in a black-box setting. Then a novel collaborative multi-task training framework is proposed to construct a detector that identifies adversarial examples based on the pairwise relationship of the label pairs. The detector can identify and reject high confidence adversarial examples that bypass the black-box defence. The model, whose robustness has been enhanced, works reciprocally with the detector on the false-negative adversarial examples.Importantly, the proposed collaborative architecture can prevent the adversary from finding valid adversarial examples in a near-white-box setting. We evaluate our defence against four state-of-the-art attacks onMNIST and CIFAR10 datasets. Our defence method increases the classification accuracy of black-box adversarial examples up to 96.3%, and detects up to 98.7% of the high confidence adversarial examples, while only decreases the accuracy of benign example classification by 2.1% on the CIFAR10 dataset.