 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMan-in-the-Middle Attacks against Machine Learning Classifiers via Malicious Generative Models
Oct 14, 2019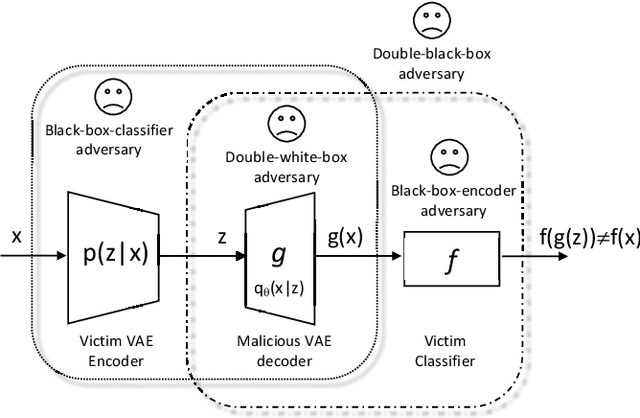

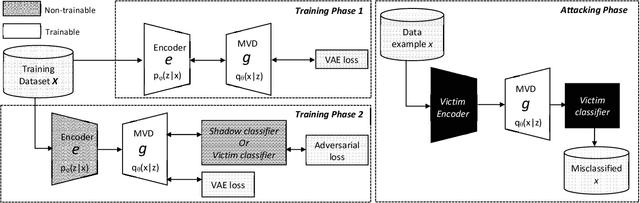

Deep Neural Networks (DNNs) are vulnerable to deliberately crafted adversarial examples. In the past few years, many efforts have been spent on exploring query-optimisation attacks to find adversarial examples of either black-box or white-box DNN models, as well as the defending countermeasures against those attacks. In this work, we explore vulnerabilities of DNN models under the umbrella of Man-in-the-Middle (MitM) attacks, which has not been investigated before. From the perspective of an MitM adversary, the aforementioned adversarial example attacks are not viable anymore. First, such attacks must acquire the outputs from the models by multiple times before actually launching attacks, which is difficult for the MitM adversary in practice. Second, such attacks are one-off and cannot be directly generalised onto new data examples, which decreases the rate of return for the attacker. In contrast, using generative models to craft adversarial examples on the fly can mitigate the drawbacks. However, the adversarial capability of the generative models, such as Variational Auto-Encoder (VAE), has not been extensively studied. Therefore, given a classifier, we investigate using a VAE decoder to either transform benign inputs to their adversarial counterparts or decode outputs from benign VAE encoders to be adversarial examples. The proposed method can endue more capability to MitM attackers. Based on our evaluation, the proposed attack can achieve above 95% success rate on both MNIST and CIFAR10 datasets, which is better or comparable with state-of-the-art query-optimisation attacks. At the meantime, the attack is 104 times faster than the query-optimisation attacks.