 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Society-Inspired Approaches to Agentic AI Security: The 4C Framework
Feb 02, 2026AI is moving from domain-specific autonomy in closed, predictable settings to large-language-model-driven agents that plan and act in open, cross-organizational environments. As a result, the cybersecurity risk landscape is changing in fundamental ways. Agentic AI systems can plan, act, collaborate, and persist over time, functioning as participants in complex socio-technical ecosystems rather than as isolated software components. Although recent work has strengthened defenses against model and pipeline level vulnerabilities such as prompt injection, data poisoning, and tool misuse, these system centric approaches may fail to capture risks that arise from autonomy, interaction, and emergent behavior. This article introduces the 4C Framework for multi-agent AI security, inspired by societal governance. It organizes agentic risks across four interdependent dimensions: Core (system, infrastructure, and environmental integrity), Connection (communication, coordination, and trust), Cognition (belief, goal, and reasoning integrity), and Compliance (ethical, legal, and institutional governance). By shifting AI security from a narrow focus on system-centric protection to the broader preservation of behavioral integrity and intent, the framework complements existing AI security strategies and offers a principled foundation for building agentic AI systems that are trustworthy, governable, and aligned with human values.
Keep the Lights On, Keep the Lengths in Check: Plug-In Adversarial Detection for Time-Series LLMs in Energy Forecasting
Dec 13, 2025Accurate time-series forecasting is increasingly critical for planning and operations in low-carbon power systems. Emerging time-series large language models (TS-LLMs) now deliver this capability at scale, requiring no task-specific retraining, and are quickly becoming essential components within the Internet-of-Energy (IoE) ecosystem. However, their real-world deployment is complicated by a critical vulnerability: adversarial examples (AEs). Detecting these AEs is challenging because (i) adversarial perturbations are optimized across the entire input sequence and exploit global temporal dependencies, which renders local detection methods ineffective, and (ii) unlike traditional forecasting models with fixed input dimensions, TS-LLMs accept sequences of variable length, increasing variability that complicates detection. To address these challenges, we propose a plug-in detection framework that capitalizes on the TS-LLM's own variable-length input capability. Our method uses sampling-induced divergence as a detection signal. Given an input sequence, we generate multiple shortened variants and detect AEs by measuring the consistency of their forecasts: Benign sequences tend to produce stable predictions under sampling, whereas adversarial sequences show low forecast similarity, because perturbations optimized for a full-length sequence do not transfer reliably to shorter, differently-structured subsamples. We evaluate our approach on three representative TS-LLMs (TimeGPT, TimesFM, and TimeLLM) across three energy datasets: ETTh2 (Electricity Transformer Temperature), NI (Hourly Energy Consumption), and Consumption (Hourly Electricity Consumption and Production). Empirical results confirm strong and robust detection performance across both black-box and white-box attack scenarios, highlighting its practicality as a reliable safeguard for TS-LLM forecasting in real-world energy systems.
MulVuln: Enhancing Pre-trained LMs with Shared and Language-Specific Knowledge for Multilingual Vulnerability Detection
Oct 05, 2025Software vulnerabilities (SVs) pose a critical threat to safety-critical systems, driving the adoption of AI-based approaches such as machine learning and deep learning for software vulnerability detection. Despite promising results, most existing methods are limited to a single programming language. This is problematic given the multilingual nature of modern software, which is often complex and written in multiple languages. Current approaches often face challenges in capturing both shared and language-specific knowledge of source code, which can limit their performance on diverse programming languages and real-world codebases. To address this gap, we propose MULVULN, a novel multilingual vulnerability detection approach that learns from source code across multiple languages. MULVULN captures both the shared knowledge that generalizes across languages and the language-specific knowledge that reflects unique coding conventions. By integrating these aspects, it achieves more robust and effective detection of vulnerabilities in real-world multilingual software systems. The rigorous and extensive experiments on the real-world and diverse REEF dataset, consisting of 4,466 CVEs with 30,987 patches across seven programming languages, demonstrate the superiority of MULVULN over thirteen effective and state-of-the-art baselines. Notably, MULVULN achieves substantially higher F1-score, with improvements ranging from 1.45% to 23.59% compared to the baseline methods.
Adversarial Attacks Against Automated Fact-Checking: A Survey
Sep 10, 2025In an era where misinformation spreads freely, fact-checking (FC) plays a crucial role in verifying claims and promoting reliable information. While automated fact-checking (AFC) has advanced significantly, existing systems remain vulnerable to adversarial attacks that manipulate or generate claims, evidence, or claim-evidence pairs. These attacks can distort the truth, mislead decision-makers, and ultimately undermine the reliability of FC models. Despite growing research interest in adversarial attacks against AFC systems, a comprehensive, holistic overview of key challenges remains lacking. These challenges include understanding attack strategies, assessing the resilience of current models, and identifying ways to enhance robustness. This survey provides the first in-depth review of adversarial attacks targeting FC, categorizing existing attack methodologies and evaluating their impact on AFC systems. Additionally, we examine recent advancements in adversary-aware defenses and highlight open research questions that require further exploration. Our findings underscore the urgent need for resilient FC frameworks capable of withstanding adversarial manipulations in pursuit of preserving high verification accuracy.
What is the Cost of Differential Privacy for Deep Learning-Based Trajectory Generation?
Jun 11, 2025While location trajectories offer valuable insights, they also reveal sensitive personal information. Differential Privacy (DP) offers formal protection, but achieving a favourable utility-privacy trade-off remains challenging. Recent works explore deep learning-based generative models to produce synthetic trajectories. However, current models lack formal privacy guarantees and rely on conditional information derived from real data during generation. This work investigates the utility cost of enforcing DP in such models, addressing three research questions across two datasets and eleven utility metrics. (1) We evaluate how DP-SGD, the standard DP training method for deep learning, affects the utility of state-of-the-art generative models. (2) Since DP-SGD is limited to unconditional models, we propose a novel DP mechanism for conditional generation that provides formal guarantees and assess its impact on utility. (3) We analyse how model types - Diffusion, VAE, and GAN - affect the utility-privacy trade-off. Our results show that DP-SGD significantly impacts performance, although some utility remains if the datasets is sufficiently large. The proposed DP mechanism improves training stability, particularly when combined with DP-SGD, for unstable models such as GANs and on smaller datasets. Diffusion models yield the best utility without guarantees, but with DP-SGD, GANs perform best, indicating that the best non-private model is not necessarily optimal when targeting formal guarantees. In conclusion, DP trajectory generation remains a challenging task, and formal guarantees are currently only feasible with large datasets and in constrained use cases.
Adversarially Guided Stateful Defense Against Backdoor Attacks in Federated Deep Learning
Oct 15, 2024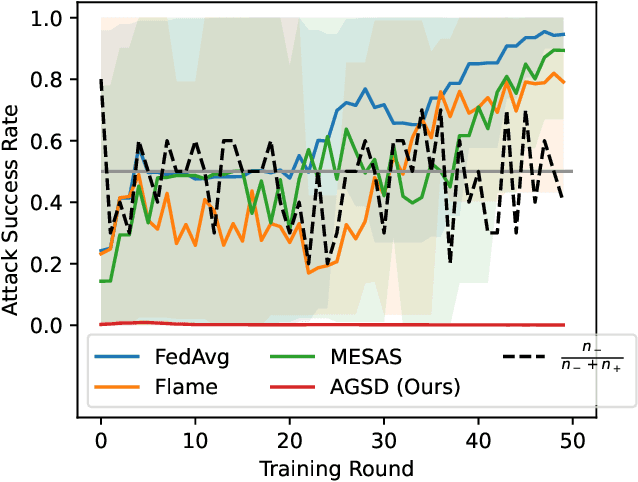
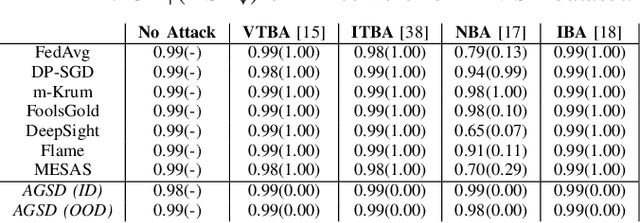
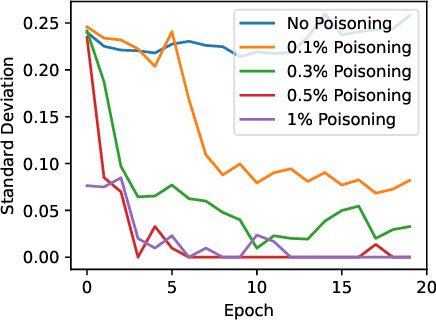
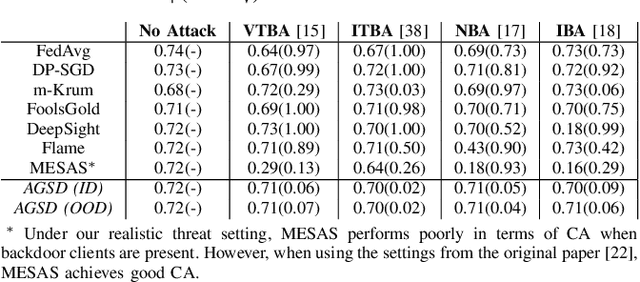
Recent works have shown that Federated Learning (FL) is vulnerable to backdoor attacks. Existing defenses cluster submitted updates from clients and select the best cluster for aggregation. However, they often rely on unrealistic assumptions regarding client submissions and sampled clients population while choosing the best cluster. We show that in realistic FL settings, state-of-the-art (SOTA) defenses struggle to perform well against backdoor attacks in FL. To address this, we highlight that backdoored submissions are adversarially biased and overconfident compared to clean submissions. We, therefore, propose an Adversarially Guided Stateful Defense (AGSD) against backdoor attacks on Deep Neural Networks (DNNs) in FL scenarios. AGSD employs adversarial perturbations to a small held-out dataset to compute a novel metric, called the trust index, that guides the cluster selection without relying on any unrealistic assumptions regarding client submissions. Moreover, AGSD maintains a trust state history of each client that adaptively penalizes backdoored clients and rewards clean clients. In realistic FL settings, where SOTA defenses mostly fail to resist attacks, AGSD mostly outperforms all SOTA defenses with minimal drop in clean accuracy (5% in the worst-case compared to best accuracy) even when (a) given a very small held-out dataset -- typically AGSD assumes 50 samples (<= 0.1% of the training data) and (b) no heldout dataset is available, and out-of-distribution data is used instead. For reproducibility, our code will be openly available at: https://github.com/hassanalikhatim/AGSD.
Honeyfile Camouflage: Hiding Fake Files in Plain Sight
May 08, 2024Honeyfiles are a particularly useful type of honeypot: fake files deployed to detect and infer information from malicious behaviour. This paper considers the challenge of naming honeyfiles so they are camouflaged when placed amongst real files in a file system. Based on cosine distances in semantic vector spaces, we develop two metrics for filename camouflage: one based on simple averaging and one on clustering with mixture fitting. We evaluate and compare the metrics, showing that both perform well on a publicly available GitHub software repository dataset.
Contextual Chart Generation for Cyber Deception
Apr 07, 2024Honeyfiles are security assets designed to attract and detect intruders on compromised systems. Honeyfiles are a type of honeypot that mimic real, sensitive documents, creating the illusion of the presence of valuable data. Interaction with a honeyfile reveals the presence of an intruder, and can provide insights into their goals and intentions. Their practical use, however, is limited by the time, cost and effort associated with manually creating realistic content. The introduction of large language models has made high-quality text generation accessible, but honeyfiles contain a variety of content including charts, tables and images. This content needs to be plausible and realistic, as well as semantically consistent both within honeyfiles and with the real documents they mimic, to successfully deceive an intruder. In this paper, we focus on an important component of the honeyfile content generation problem: document charts. Charts are ubiquitous in corporate documents and are commonly used to communicate quantitative and scientific data. Existing image generation models, such as DALL-E, are rather prone to generating charts with incomprehensible text and unconvincing data. We take a multi-modal approach to this problem by combining two purpose-built generative models: a multitask Transformer and a specialized multi-head autoencoder. The Transformer generates realistic captions and plot text, while the autoencoder generates the underlying tabular data for the plot. To advance the field of automated honeyplot generation, we also release a new document-chart dataset and propose a novel metric Keyword Semantic Matching (KSM). This metric measures the semantic consistency between keywords of a corpus and a smaller bag of words. Extensive experiments demonstrate excellent performance against multiple large language models, including ChatGPT and GPT4.
SoK: Can Trajectory Generation Combine Privacy and Utility?
Mar 12, 2024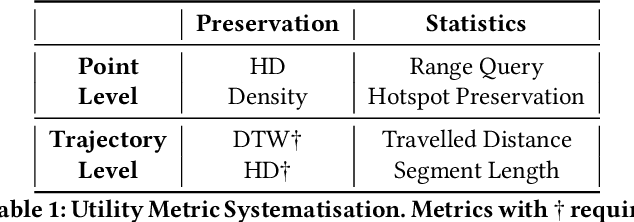
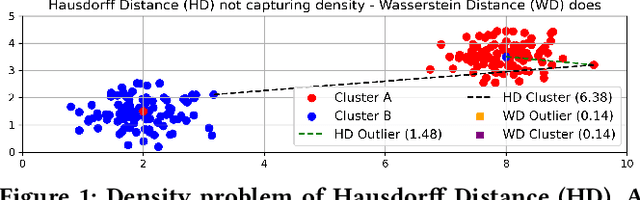
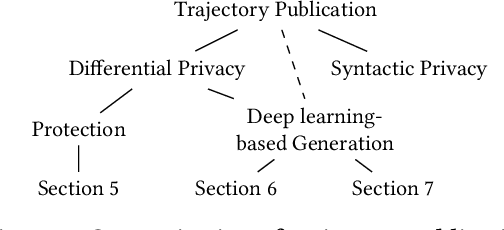
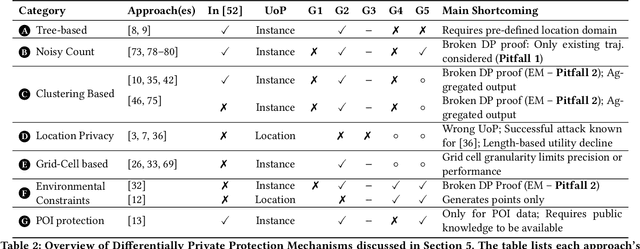
While location trajectories represent a valuable data source for analyses and location-based services, they can reveal sensitive information, such as political and religious preferences. Differentially private publication mechanisms have been proposed to allow for analyses under rigorous privacy guarantees. However, the traditional protection schemes suffer from a limiting privacy-utility trade-off and are vulnerable to correlation and reconstruction attacks. Synthetic trajectory data generation and release represent a promising alternative to protection algorithms. While initial proposals achieve remarkable utility, they fail to provide rigorous privacy guarantees. This paper proposes a framework for designing a privacy-preserving trajectory publication approach by defining five design goals, particularly stressing the importance of choosing an appropriate Unit of Privacy. Based on this framework, we briefly discuss the existing trajectory protection approaches, emphasising their shortcomings. This work focuses on the systematisation of the state-of-the-art generative models for trajectories in the context of the proposed framework. We find that no existing solution satisfies all requirements. Thus, we perform an experimental study evaluating the applicability of six sequential generative models to the trajectory domain. Finally, we conclude that a generative trajectory model providing semantic guarantees remains an open research question and propose concrete next steps for future research.
A2C: A Modular Multi-stage Collaborative Decision Framework for Human-AI Teams
Jan 25, 2024This paper introduces A2C, a multi-stage collaborative decision framework designed to enable robust decision-making within human-AI teams. Drawing inspiration from concepts such as rejection learning and learning to defer, A2C incorporates AI systems trained to recognise uncertainty in their decisions and defer to human experts when needed. Moreover, A2C caters to scenarios where even human experts encounter limitations, such as in incident detection and response in cyber Security Operations Centres (SOC). In such scenarios, A2C facilitates collaborative explorations, enabling collective resolution of complex challenges. With support for three distinct decision-making modes in human-AI teams: Automated, Augmented, and Collaborative, A2C offers a flexible platform for developing effective strategies for human-AI collaboration. By harnessing the strengths of both humans and AI, it significantly improves the efficiency and effectiveness of complex decision-making in dynamic and evolving environments. To validate A2C's capabilities, we conducted extensive simulative experiments using benchmark datasets. The results clearly demonstrate that all three modes of decision-making can be effectively supported by A2C. Most notably, collaborative exploration by (simulated) human experts and AI achieves superior performance compared to AI in isolation, underscoring the framework's potential to enhance decision-making within human-AI teams.