 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Shift Estimation With Incremental Prior Update
Apr 02, 2026An assumption often made in supervised learning is that the training and testing sets have the same label distribution. However, in real-life scenarios, this assumption rarely holds. For example, medical diagnosis result distributions change over time and across locations; fraud detection models must adapt as patterns of fraudulent activity shift; the category distribution of social media posts changes based on trending topics and user demographics. In the task of label shift estimation, the goal is to estimate the changing label distribution $p_t(y)$ in the testing set, assuming the likelihood $p(x|y)$ does not change, implying no concept drift. In this paper, we propose a new approach for post-hoc label shift estimation, unlike previous methods that perform moment matching with confusion matrix estimated from a validation set or maximize the likelihood of the new data with an expectation-maximization algorithm. We aim to incrementally update the prior on each sample, adjusting each posterior for more accurate label shift estimation. The proposed method is based on intuitive assumptions on classifiers that are generally true for modern probabilistic classifiers. The proposed method relies on a weaker notion of calibration compared to other methods. As a post-hoc approach for label shift estimation, the proposed method is versatile and can be applied to any black-box probabilistic classifier. Experiments on CIFAR-10 and MNIST show that the proposed method consistently outperforms the current state-of-the-art maximum likelihood-based methods under different calibrations and varying intensities of label shift.
* SIAM SDM 2025
In Vino Veritas and Vulnerabilities: Examining LLM Safety via Drunk Language Inducement
Jan 19, 2026Humans are susceptible to undesirable behaviours and privacy leaks under the influence of alcohol. This paper investigates drunk language, i.e., text written under the influence of alcohol, as a driver for safety failures in large language models (LLMs). We investigate three mechanisms for inducing drunk language in LLMs: persona-based prompting, causal fine-tuning, and reinforcement-based post-training. When evaluated on 5 LLMs, we observe a higher susceptibility to jailbreaking on JailbreakBench (even in the presence of defences) and privacy leaks on ConfAIde, where both benchmarks are in English, as compared to the base LLMs as well as previously reported approaches. Via a robust combination of manual evaluation and LLM-based evaluators and analysis of error categories, our findings highlight a correspondence between human-intoxicated behaviour, and anthropomorphism in LLMs induced with drunk language. The simplicity and efficiency of our drunk language inducement approaches position them as potential counters for LLM safety tuning, highlighting significant risks to LLM safety.
Demo: TOSense -- What Did You Just Agree to?
Aug 01, 2025



Online services often require users to agree to lengthy and obscure Terms of Service (ToS), leading to information asymmetry and legal risks. This paper proposes TOSense-a Chrome extension that allows users to ask questions about ToS in natural language and get concise answers in real time. The system combines (i) a crawler "tos-crawl" that automatically extracts ToS content, and (ii) a lightweight large language model pipeline: MiniLM for semantic retrieval and BART-encoder for answer relevance verification. To avoid expensive manual annotation, we present a novel Question Answering Evaluation Pipeline (QEP) that generates synthetic questions and verifies the correctness of answers using clustered topic matching. Experiments on five major platforms, Apple, Google, X (formerly Twitter), Microsoft, and Netflix, show the effectiveness of TOSense (with up to 44.5% accuracy) across varying number of topic clusters. During the demonstration, we will showcase TOSense in action. Attendees will be able to experience seamless extraction, interactive question answering, and instant indexing of new sites.
Instance-Wise Monotonic Calibration by Constrained Transformation
Jul 09, 2025Deep neural networks often produce miscalibrated probability estimates, leading to overconfident predictions. A common approach for calibration is fitting a post-hoc calibration map on unseen validation data that transforms predicted probabilities. A key desirable property of the calibration map is instance-wise monotonicity (i.e., preserving the ranking of probability outputs). However, most existing post-hoc calibration methods do not guarantee monotonicity. Previous monotonic approaches either use an under-parameterized calibration map with limited expressive ability or rely on black-box neural networks, which lack interpretability and robustness. In this paper, we propose a family of novel monotonic post-hoc calibration methods, which employs a constrained calibration map parameterized linearly with respect to the number of classes. Our proposed approach ensures expressiveness, robustness, and interpretability while preserving the relative ordering of the probability output by formulating the proposed calibration map as a constrained optimization problem. Our proposed methods achieve state-of-the-art performance across datasets with different deep neural network models, outperforming existing calibration methods while being data and computation-efficient. Our code is available at https://github.com/YunruiZhang/Calibration-by-Constrained-Transformation
What is the Cost of Differential Privacy for Deep Learning-Based Trajectory Generation?
Jun 11, 2025While location trajectories offer valuable insights, they also reveal sensitive personal information. Differential Privacy (DP) offers formal protection, but achieving a favourable utility-privacy trade-off remains challenging. Recent works explore deep learning-based generative models to produce synthetic trajectories. However, current models lack formal privacy guarantees and rely on conditional information derived from real data during generation. This work investigates the utility cost of enforcing DP in such models, addressing three research questions across two datasets and eleven utility metrics. (1) We evaluate how DP-SGD, the standard DP training method for deep learning, affects the utility of state-of-the-art generative models. (2) Since DP-SGD is limited to unconditional models, we propose a novel DP mechanism for conditional generation that provides formal guarantees and assess its impact on utility. (3) We analyse how model types - Diffusion, VAE, and GAN - affect the utility-privacy trade-off. Our results show that DP-SGD significantly impacts performance, although some utility remains if the datasets is sufficiently large. The proposed DP mechanism improves training stability, particularly when combined with DP-SGD, for unstable models such as GANs and on smaller datasets. Diffusion models yield the best utility without guarantees, but with DP-SGD, GANs perform best, indicating that the best non-private model is not necessarily optimal when targeting formal guarantees. In conclusion, DP trajectory generation remains a challenging task, and formal guarantees are currently only feasible with large datasets and in constrained use cases.
Revisit Time Series Classification Benchmark: The Impact of Temporal Information for Classification
Mar 26, 2025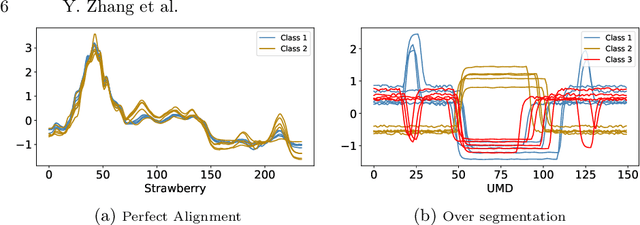
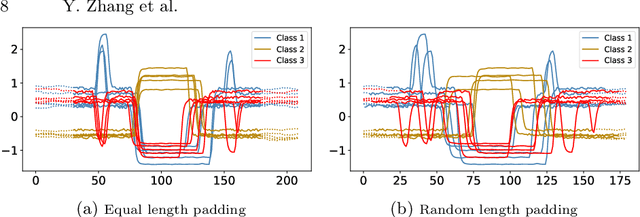
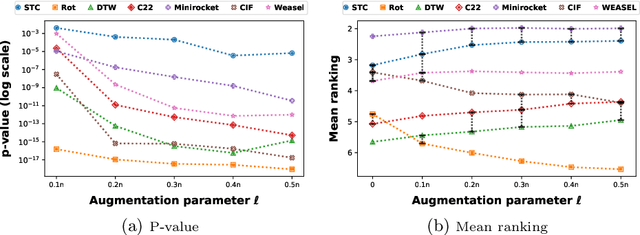
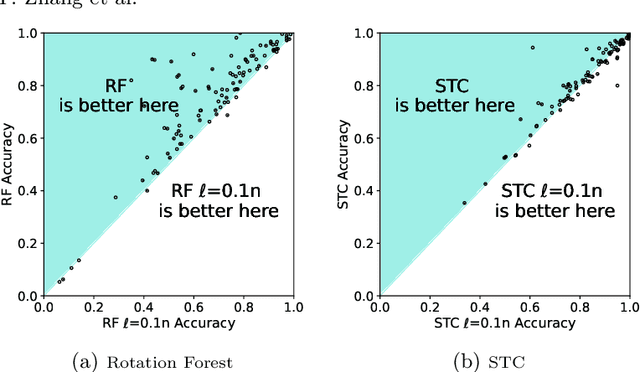
Time series classification is usually regarded as a distinct task from tabular data classification due to the importance of temporal information. However, in this paper, by performing permutation tests that disrupt temporal information on the UCR time series classification archive, the most widely used benchmark for time series classification, we identify a significant proportion of datasets where temporal information has little to no impact on classification. Many of these datasets are tabular in nature or rely mainly on tabular features, leading to potentially biased evaluations of time series classifiers focused on temporal information. To address this, we propose UCR Augmented, a benchmark based on the UCR time series classification archive designed to evaluate classifiers' ability to extract and utilize temporal information. Testing classifiers from seven categories on this benchmark revealed notable shifts in performance rankings. Some previously overlooked approaches perform well, while others see their performance decline significantly when temporal information is crucial. UCR Augmented provides a more robust framework for assessing time series classifiers, ensuring fairer evaluations. Our code is available at https://github.com/YunruiZhang/Revisit-Time-Series-Classification-Benchmark.
Comparison of Multilingual and Bilingual Models for Satirical News Detection of Arabic and English
Nov 16, 2024


Satirical news is real news combined with a humorous comment or exaggerated content, and it often mimics the format and style of real news. However, satirical news is often misunderstood as misinformation, especially by individuals from different cultural and social backgrounds. This research addresses the challenge of distinguishing satire from truthful news by leveraging multilingual satire detection methods in English and Arabic. We explore both zero-shot and chain-of-thought (CoT) prompting using two language models, Jais-chat(13B) and LLaMA-2-chat(7B). Our results show that CoT prompting offers a significant advantage for the Jais-chat model over the LLaMA-2-chat model. Specifically, Jais-chat achieved the best performance, with an F1-score of 80\% in English when using CoT prompting. These results highlight the importance of structured reasoning in CoT, which enhances contextual understanding and is vital for complex tasks like satire detection.
Adversarially Guided Stateful Defense Against Backdoor Attacks in Federated Deep Learning
Oct 15, 2024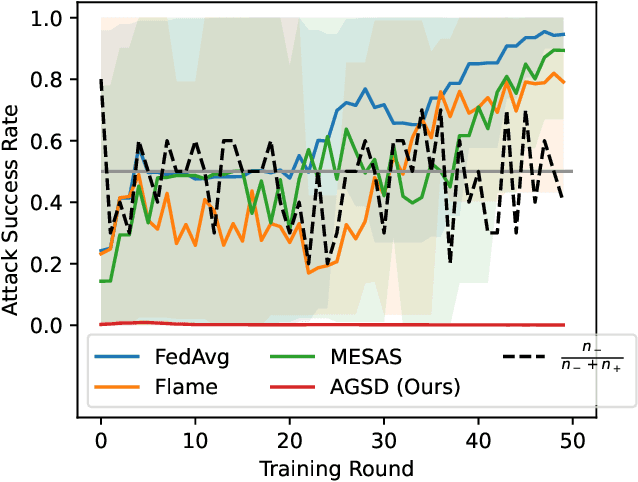
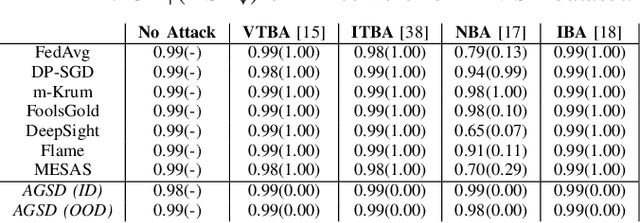
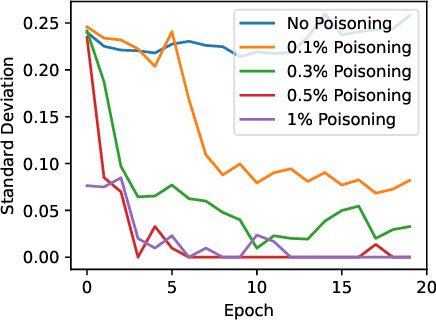
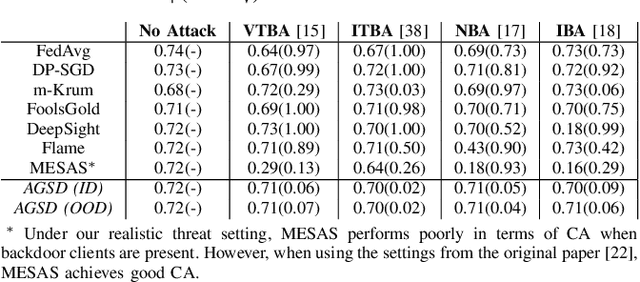
Recent works have shown that Federated Learning (FL) is vulnerable to backdoor attacks. Existing defenses cluster submitted updates from clients and select the best cluster for aggregation. However, they often rely on unrealistic assumptions regarding client submissions and sampled clients population while choosing the best cluster. We show that in realistic FL settings, state-of-the-art (SOTA) defenses struggle to perform well against backdoor attacks in FL. To address this, we highlight that backdoored submissions are adversarially biased and overconfident compared to clean submissions. We, therefore, propose an Adversarially Guided Stateful Defense (AGSD) against backdoor attacks on Deep Neural Networks (DNNs) in FL scenarios. AGSD employs adversarial perturbations to a small held-out dataset to compute a novel metric, called the trust index, that guides the cluster selection without relying on any unrealistic assumptions regarding client submissions. Moreover, AGSD maintains a trust state history of each client that adaptively penalizes backdoored clients and rewards clean clients. In realistic FL settings, where SOTA defenses mostly fail to resist attacks, AGSD mostly outperforms all SOTA defenses with minimal drop in clean accuracy (5% in the worst-case compared to best accuracy) even when (a) given a very small held-out dataset -- typically AGSD assumes 50 samples (<= 0.1% of the training data) and (b) no heldout dataset is available, and out-of-distribution data is used instead. For reproducibility, our code will be openly available at: https://github.com/hassanalikhatim/AGSD.
Demystifying Trajectory Recovery From Ash: An Open-Source Evaluation and Enhancement
Sep 23, 2024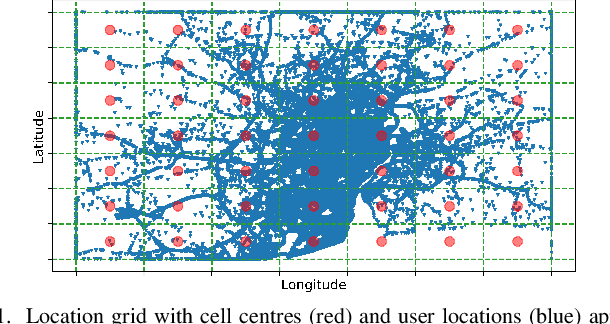
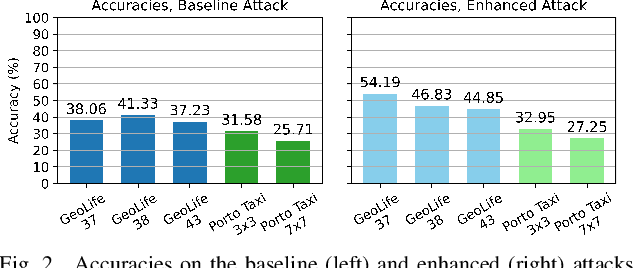
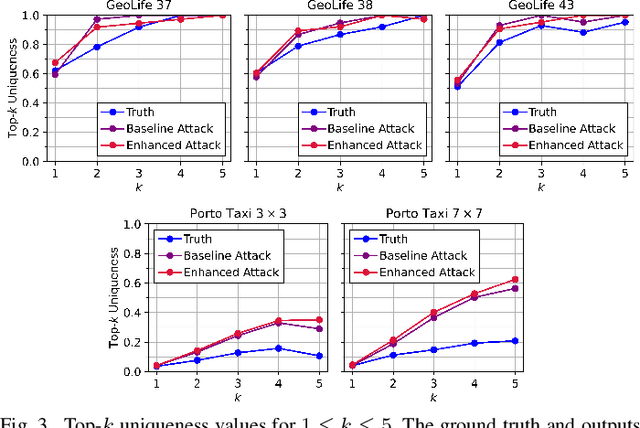
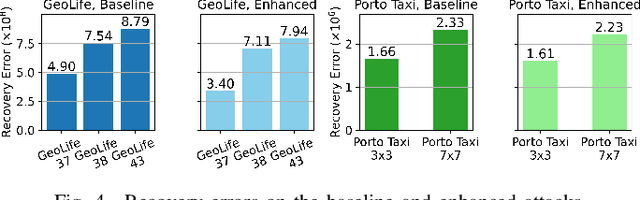
Once analysed, location trajectories can provide valuable insights beneficial to various applications. However, such data is also highly sensitive, rendering them susceptible to privacy risks in the event of mismanagement, for example, revealing an individual's identity, home address, or political affiliations. Hence, ensuring that privacy is preserved for this data is a priority. One commonly taken measure to mitigate this concern is aggregation. Previous work by Xu et al. shows that trajectories are still recoverable from anonymised and aggregated datasets. However, the study lacks implementation details, obfuscating the mechanisms of the attack. Additionally, the attack was evaluated on commercial non-public datasets, rendering the results and subsequent claims unverifiable. This study reimplements the trajectory recovery attack from scratch and evaluates it on two open-source datasets, detailing the preprocessing steps and implementation. Results confirm that privacy leakage still exists despite common anonymisation and aggregation methods but also indicate that the initial accuracy claims may have been overly ambitious. We release all code as open-source to ensure the results are entirely reproducible and, therefore, verifiable. Moreover, we propose a stronger attack by designing a series of enhancements to the baseline attack. These enhancements yield higher accuracies by up to 16%, providing an improved benchmark for future research in trajectory recovery methods. Our improvements also enable online execution of the attack, allowing partial attacks on larger datasets previously considered unprocessable, thereby furthering the extent of privacy leakage. The findings emphasise the importance of using strong privacy-preserving mechanisms when releasing aggregated mobility data and not solely relying on aggregation as a means of anonymisation.
Synthetic Trajectory Generation Through Convolutional Neural Networks
Jul 24, 2024



Location trajectories provide valuable insights for applications from urban planning to pandemic control. However, mobility data can also reveal sensitive information about individuals, such as political opinions, religious beliefs, or sexual orientations. Existing privacy-preserving approaches for publishing this data face a significant utility-privacy trade-off. Releasing synthetic trajectory data generated through deep learning offers a promising solution. Due to the trajectories' sequential nature, most existing models are based on recurrent neural networks (RNNs). However, research in generative adversarial networks (GANs) largely employs convolutional neural networks (CNNs) for image generation. This discrepancy raises the question of whether advances in computer vision can be applied to trajectory generation. In this work, we introduce a Reversible Trajectory-to-CNN Transformation (RTCT) that adapts trajectories into a format suitable for CNN-based models. We integrated this transformation with the well-known DCGAN in a proof-of-concept (PoC) and evaluated its performance against an RNN-based trajectory GAN using four metrics across two datasets. The PoC was superior in capturing spatial distributions compared to the RNN model but had difficulty replicating sequential and temporal properties. Although the PoC's utility is not sufficient for practical applications, the results demonstrate the transformation's potential to facilitate the use of CNNs for trajectory generation, opening up avenues for future research. To support continued research, all source code has been made available under an open-source license.