 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Methodologies for Agentic Evaluations Across Domains: Leakage of Sensitive Information, Fraud and Cybersecurity Threats
Jan 22, 2026The rapid rise of autonomous AI systems and advancements in agent capabilities are introducing new risks due to reduced oversight of real-world interactions. Yet agent testing remains nascent and is still a developing science. As AI agents begin to be deployed globally, it is important that they handle different languages and cultures accurately and securely. To address this, participants from The International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the European Commission, France, Kenya, South Korea, and the United Kingdom have come together to align approaches to agentic evaluations. This is the third exercise, building on insights from two earlier joint testing exercises conducted by the Network in November 2024 and February 2025. The objective is to further refine best practices for testing advanced AI systems. The exercise was split into two strands: (1) common risks, including leakage of sensitive information and fraud, led by Singapore AISI; and (2) cybersecurity, led by UK AISI. A mix of open and closed-weight models were evaluated against tasks from various public agentic benchmarks. Given the nascency of agentic testing, our primary focus was on understanding methodological issues in conducting such tests, rather than examining test results or model capabilities. This collaboration marks an important step forward as participants work together to advance the science of agentic evaluations.
Robust Anomaly Detection in O-RAN: Leveraging LLMs against Data Manipulation Attacks
Aug 11, 2025The introduction of 5G and the Open Radio Access Network (O-RAN) architecture has enabled more flexible and intelligent network deployments. However, the increased complexity and openness of these architectures also introduce novel security challenges, such as data manipulation attacks on the semi-standardised Shared Data Layer (SDL) within the O-RAN platform through malicious xApps. In particular, malicious xApps can exploit this vulnerability by introducing subtle Unicode-wise alterations (hypoglyphs) into the data that are being used by traditional machine learning (ML)-based anomaly detection methods. These Unicode-wise manipulations can potentially bypass detection and cause failures in anomaly detection systems based on traditional ML, such as AutoEncoders, which are unable to process hypoglyphed data without crashing. We investigate the use of Large Language Models (LLMs) for anomaly detection within the O-RAN architecture to address this challenge. We demonstrate that LLM-based xApps maintain robust operational performance and are capable of processing manipulated messages without crashing. While initial detection accuracy requires further improvements, our results highlight the robustness of LLMs to adversarial attacks such as hypoglyphs in input data. There is potential to use their adaptability through prompt engineering to further improve the accuracy, although this requires further research. Additionally, we show that LLMs achieve low detection latency (under 0.07 seconds), making them suitable for Near-Real-Time (Near-RT) RIC deployments.
Self-Adaptive and Robust Federated Spectrum Sensing without Benign Majority for Cellular Networks
Jul 16, 2025Advancements in wireless and mobile technologies, including 5G advanced and the envisioned 6G, are driving exponential growth in wireless devices. However, this rapid expansion exacerbates spectrum scarcity, posing a critical challenge. Dynamic spectrum allocation (DSA)--which relies on sensing and dynamically sharing spectrum--has emerged as an essential solution to address this issue. While machine learning (ML) models hold significant potential for improving spectrum sensing, their adoption in centralized ML-based DSA systems is limited by privacy concerns, bandwidth constraints, and regulatory challenges. To overcome these limitations, distributed ML-based approaches such as Federated Learning (FL) offer promising alternatives. This work addresses two key challenges in FL-based spectrum sensing (FLSS). First, the scarcity of labeled data for training FL models in practical spectrum sensing scenarios is tackled with a semi-supervised FL approach, combined with energy detection, enabling model training on unlabeled datasets. Second, we examine the security vulnerabilities of FLSS, focusing on the impact of data poisoning attacks. Our analysis highlights the shortcomings of existing majority-based defenses in countering such attacks. To address these vulnerabilities, we propose a novel defense mechanism inspired by vaccination, which effectively mitigates data poisoning attacks without relying on majority-based assumptions. Extensive experiments on both synthetic and real-world datasets validate our solutions, demonstrating that FLSS can achieve near-perfect accuracy on unlabeled datasets and maintain Byzantine robustness against both targeted and untargeted data poisoning attacks, even when a significant proportion of participants are malicious.
RLSA-PFL: Robust Lightweight Secure Aggregation with Model Inconsistency Detection in Privacy-Preserving Federated Learning
Feb 13, 2025Federated Learning (FL) allows users to collaboratively train a global machine learning model by sharing local model only, without exposing their private data to a central server. This distributed learning is particularly appealing in scenarios where data privacy is crucial, and it has garnered substantial attention from both industry and academia. However, studies have revealed privacy vulnerabilities in FL, where adversaries can potentially infer sensitive information from the shared model parameters. In this paper, we present an efficient masking-based secure aggregation scheme utilizing lightweight cryptographic primitives to mitigate privacy risks. Our scheme offers several advantages over existing methods. First, it requires only a single setup phase for the entire FL training session, significantly reducing communication overhead. Second, it minimizes user-side overhead by eliminating the need for user-to-user interactions, utilizing an intermediate server layer and a lightweight key negotiation method. Third, the scheme is highly resilient to user dropouts, and the users can join at any FL round. Fourth, it can detect and defend against malicious server activities, including recently discovered model inconsistency attacks. Finally, our scheme ensures security in both semi-honest and malicious settings. We provide security analysis to formally prove the robustness of our approach. Furthermore, we implemented an end-to-end prototype of our scheme. We conducted comprehensive experiments and comparisons, which show that it outperforms existing solutions in terms of communication and computation overhead, functionality, and security.
Quantum Down Sampling Filter for Variational Auto-encoder
Jan 09, 2025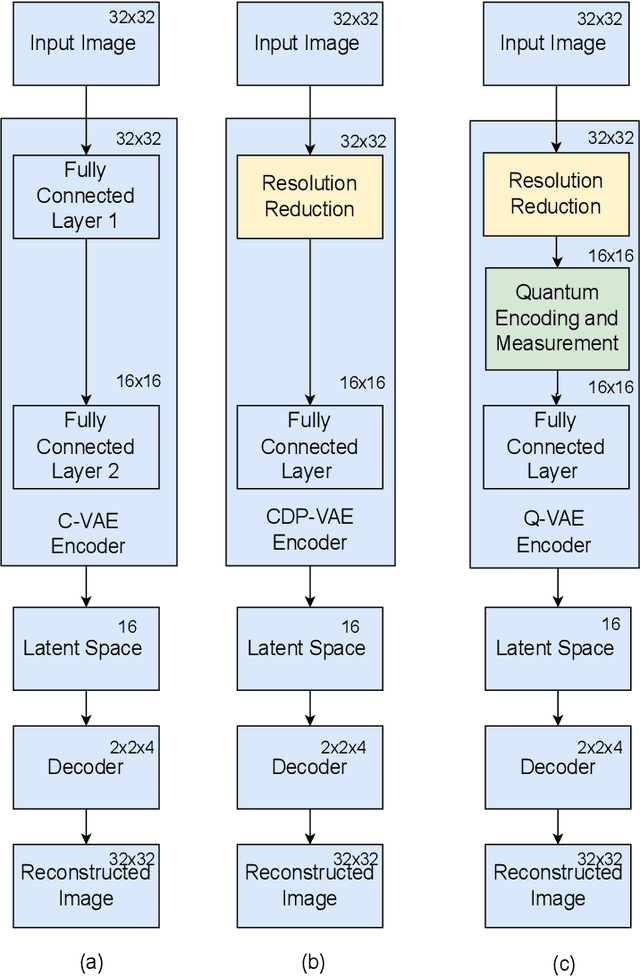



Variational Autoencoders (VAEs) are essential tools in generative modeling and image reconstruction, with their performance heavily influenced by the encoder-decoder architecture. This study aims to improve the quality of reconstructed images by enhancing their resolution and preserving finer details, particularly when working with low-resolution inputs (16x16 pixels), where traditional VAEs often yield blurred or in-accurate results. To address this, we propose a hybrid model that combines quantum computing techniques in the VAE encoder with convolutional neural networks (CNNs) in the decoder. By upscaling the resolution from 16x16 to 32x32 during the encoding process, our approach evaluates how the model reconstructs images with enhanced resolution while maintaining key features and structures. This method tests the model's robustness in handling image reconstruction and its ability to preserve essential details despite training on lower-resolution data. We evaluate our proposed down sampling filter for Quantum VAE (Q-VAE) on the MNIST and USPS datasets and compare it with classical VAEs and a variant called Classical Direct Passing VAE (CDP-VAE), which uses windowing pooling filters in the encoding process. Performance is assessed using metrics such as the Fr\'echet Inception Distance (FID) and Mean Squared Error (MSE), which measure the fidelity of reconstructed images. Our results demonstrate that the Q-VAE consistently outperforms both the Classical VAE and CDP-VAE, achieving significantly lower FID and MSE scores. Additionally, CDP-VAE yields better performance than C-VAE. These findings highlight the potential of quantum-enhanced VAEs to improve image reconstruction quality by enhancing resolution and preserving essential features, offering a promising direction for future applications in computer vision and synthetic data generation.
Security and Privacy of 6G Federated Learning-enabled Dynamic Spectrum Sharing
Jun 18, 2024



Spectrum sharing is increasingly vital in 6G wireless communication, facilitating dynamic access to unused spectrum holes. Recently, there has been a significant shift towards employing machine learning (ML) techniques for sensing spectrum holes. In this context, federated learning (FL)-enabled spectrum sensing technology has garnered wide attention, allowing for the construction of an aggregated ML model without disclosing the private spectrum sensing information of wireless user devices. However, the integrity of collaborative training and the privacy of spectrum information from local users have remained largely unexplored. This article first examines the latest developments in FL-enabled spectrum sharing for prospective 6G scenarios. It then identifies practical attack vectors in 6G to illustrate potential AI-powered security and privacy threats in these contexts. Finally, the study outlines future directions, including practical defense challenges and guidelines.
Contextual Chart Generation for Cyber Deception
Apr 07, 2024Honeyfiles are security assets designed to attract and detect intruders on compromised systems. Honeyfiles are a type of honeypot that mimic real, sensitive documents, creating the illusion of the presence of valuable data. Interaction with a honeyfile reveals the presence of an intruder, and can provide insights into their goals and intentions. Their practical use, however, is limited by the time, cost and effort associated with manually creating realistic content. The introduction of large language models has made high-quality text generation accessible, but honeyfiles contain a variety of content including charts, tables and images. This content needs to be plausible and realistic, as well as semantically consistent both within honeyfiles and with the real documents they mimic, to successfully deceive an intruder. In this paper, we focus on an important component of the honeyfile content generation problem: document charts. Charts are ubiquitous in corporate documents and are commonly used to communicate quantitative and scientific data. Existing image generation models, such as DALL-E, are rather prone to generating charts with incomprehensible text and unconvincing data. We take a multi-modal approach to this problem by combining two purpose-built generative models: a multitask Transformer and a specialized multi-head autoencoder. The Transformer generates realistic captions and plot text, while the autoencoder generates the underlying tabular data for the plot. To advance the field of automated honeyplot generation, we also release a new document-chart dataset and propose a novel metric Keyword Semantic Matching (KSM). This metric measures the semantic consistency between keywords of a corpus and a smaller bag of words. Extensive experiments demonstrate excellent performance against multiple large language models, including ChatGPT and GPT4.
Interpretability and Transparency-Driven Detection and Transformation of Textual Adversarial Examples (IT-DT)
Jul 03, 2023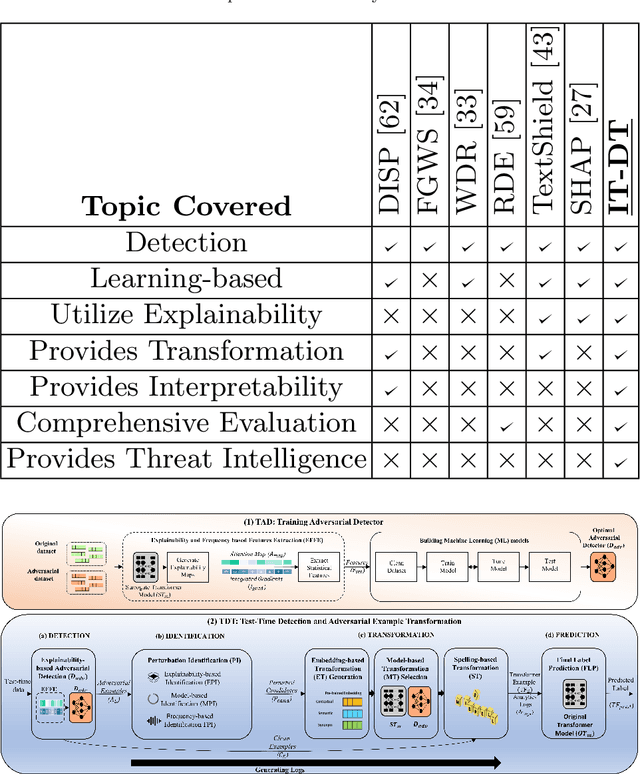



Transformer-based text classifiers like BERT, Roberta, T5, and GPT-3 have shown impressive performance in NLP. However, their vulnerability to adversarial examples poses a security risk. Existing defense methods lack interpretability, making it hard to understand adversarial classifications and identify model vulnerabilities. To address this, we propose the Interpretability and Transparency-Driven Detection and Transformation (IT-DT) framework. It focuses on interpretability and transparency in detecting and transforming textual adversarial examples. IT-DT utilizes techniques like attention maps, integrated gradients, and model feedback for interpretability during detection. This helps identify salient features and perturbed words contributing to adversarial classifications. In the transformation phase, IT-DT uses pre-trained embeddings and model feedback to generate optimal replacements for perturbed words. By finding suitable substitutions, we aim to convert adversarial examples into non-adversarial counterparts that align with the model's intended behavior while preserving the text's meaning. Transparency is emphasized through human expert involvement. Experts review and provide feedback on detection and transformation results, enhancing decision-making, especially in complex scenarios. The framework generates insights and threat intelligence empowering analysts to identify vulnerabilities and improve model robustness. Comprehensive experiments demonstrate the effectiveness of IT-DT in detecting and transforming adversarial examples. The approach enhances interpretability, provides transparency, and enables accurate identification and successful transformation of adversarial inputs. By combining technical analysis and human expertise, IT-DT significantly improves the resilience and trustworthiness of transformer-based text classifiers against adversarial attacks.
Integrity Fingerprinting of DNN with Double Black-box Design and Verification
Mar 23, 2022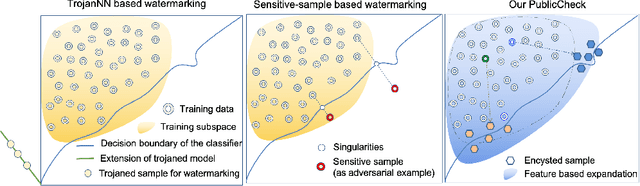

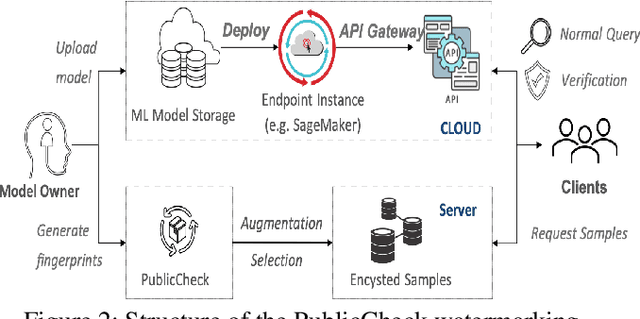

Cloud-enabled Machine Learning as a Service (MLaaS) has shown enormous promise to transform how deep learning models are developed and deployed. Nonetheless, there is a potential risk associated with the use of such services since a malicious party can modify them to achieve an adverse result. Therefore, it is imperative for model owners, service providers, and end-users to verify whether the deployed model has not been tampered with or not. Such verification requires public verifiability (i.e., fingerprinting patterns are available to all parties, including adversaries) and black-box access to the deployed model via APIs. Existing watermarking and fingerprinting approaches, however, require white-box knowledge (such as gradient) to design the fingerprinting and only support private verifiability, i.e., verification by an honest party. In this paper, we describe a practical watermarking technique that enables black-box knowledge in fingerprint design and black-box queries during verification. The service ensures the integrity of cloud-based services through public verification (i.e. fingerprinting patterns are available to all parties, including adversaries). If an adversary manipulates a model, this will result in a shift in the decision boundary. Thus, the underlying principle of double-black watermarking is that a model's decision boundary could serve as an inherent fingerprint for watermarking. Our approach captures the decision boundary by generating a limited number of encysted sample fingerprints, which are a set of naturally transformed and augmented inputs enclosed around the model's decision boundary in order to capture the inherent fingerprints of the model. We evaluated our watermarking approach against a variety of model integrity attacks and model compression attacks.
Characterizing Malicious URL Campaigns
Aug 29, 2021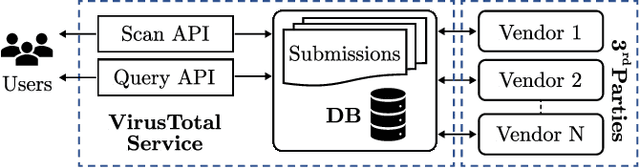

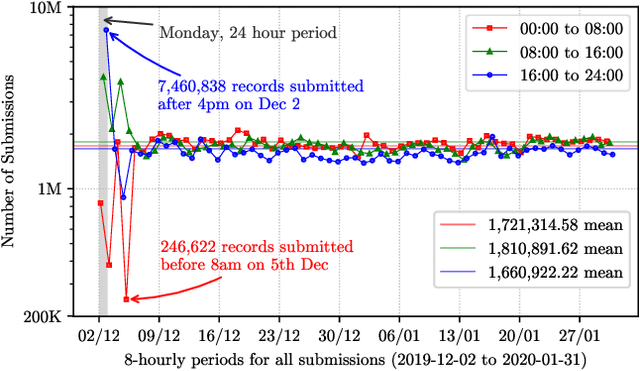
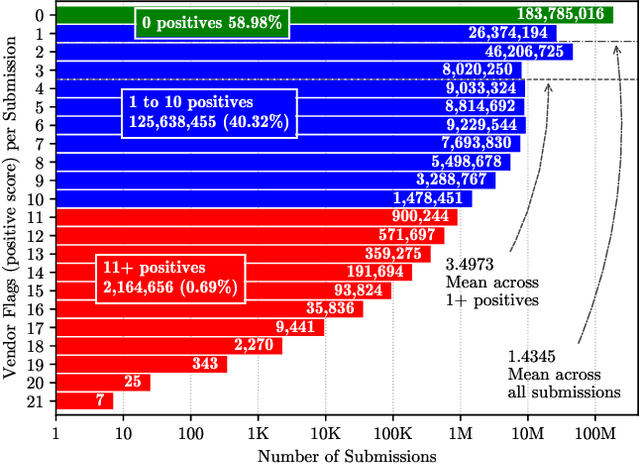
URLs are central to a myriad of cyber-security threats, from phishing to the distribution of malware. Their inherent ease of use and familiarity is continuously abused by attackers to evade defences and deceive end-users. Seemingly dissimilar URLs are being used in an organized way to perform phishing attacks and distribute malware. We refer to such behaviours as campaigns, with the hypothesis being that attacks are often coordinated to maximize success rates and develop evasion tactics. The aim is to gain better insights into campaigns, bolster our grasp of their characteristics, and thus aid the community devise more robust solutions. To this end, we performed extensive research and analysis into 311M records containing 77M unique real-world URLs that were submitted to VirusTotal from Dec 2019 to Jan 2020. From this dataset, 2.6M suspicious campaigns were identified based on their attached metadata, of which 77,810 were doubly verified as malicious. Using the 38.1M records and 9.9M URLs within these malicious campaigns, we provide varied insights such as their targeted victim brands as well as URL sizes and heterogeneity. Some surprising findings were observed, such as detection rates falling to just 13.27% for campaigns that employ more than 100 unique URLs. The paper concludes with several case-studies that illustrate the common malicious techniques employed by attackers to imperil users and circumvent defences.