 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation and Optimization of Distributed Machine Learning Techniques for Internet of Things
Mar 03, 2021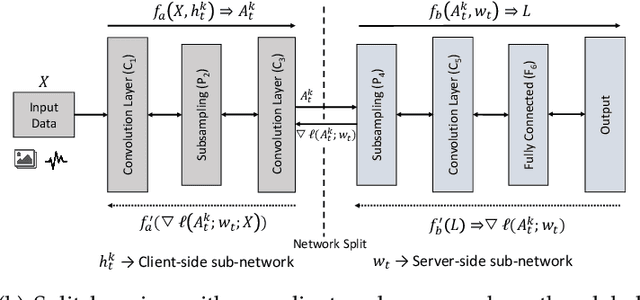
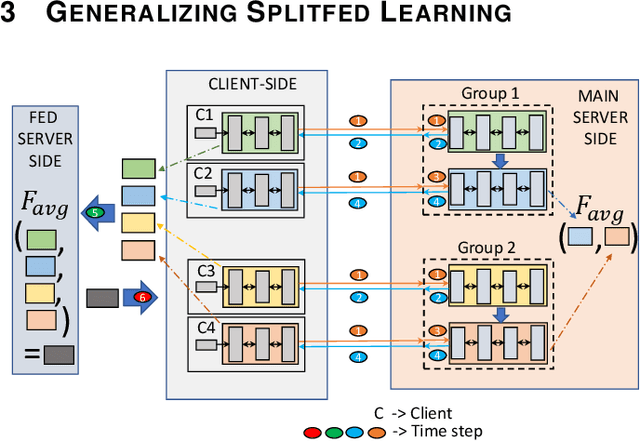
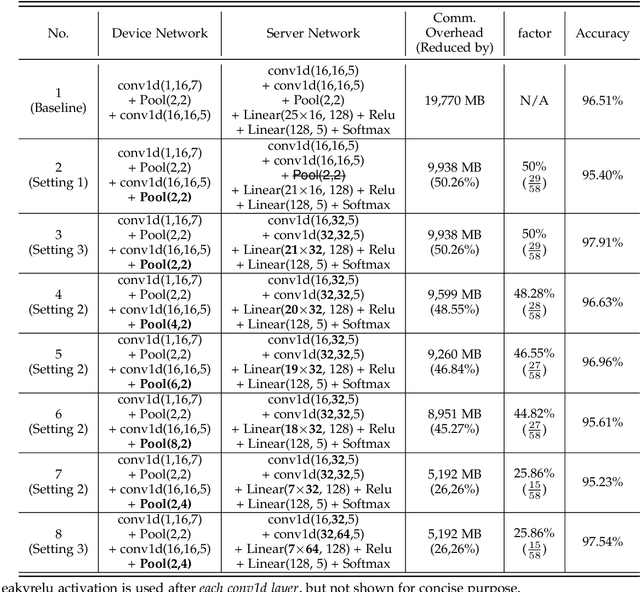
Federated learning (FL) and split learning (SL) are state-of-the-art distributed machine learning techniques to enable machine learning training without accessing raw data on clients or end devices. However, their \emph{comparative training performance} under real-world resource-restricted Internet of Things (IoT) device settings, e.g., Raspberry Pi, remains barely studied, which, to our knowledge, have not yet been evaluated and compared, rendering inconvenient reference for practitioners. This work firstly provides empirical comparisons of FL and SL in real-world IoT settings regarding (i) learning performance with heterogeneous data distributions and (ii) on-device execution overhead. Our analyses in this work demonstrate that the learning performance of SL is better than FL under an imbalanced data distribution but worse than FL under an extreme non-IID data distribution. Recently, FL and SL are combined to form splitfed learning (SFL) to leverage each of their benefits (e.g., parallel training of FL and lightweight on-device computation requirement of SL). This work then considers FL, SL, and SFL, and mount them on Raspberry Pi devices to evaluate their performance, including training time, communication overhead, power consumption, and memory usage. Besides evaluations, we apply two optimizations. Firstly, we generalize SFL by carefully examining the possibility of a hybrid type of model training at the server-side. The generalized SFL merges sequential (dependent) and parallel (independent) processes of model training and is thus beneficial for a system with large-scaled IoT devices, specifically at the server-side operations. Secondly, we propose pragmatic techniques to substantially reduce the communication overhead by up to four times for the SL and (generalized) SFL.
End-to-End Evaluation of Federated Learning and Split Learning for Internet of Things
Mar 30, 2020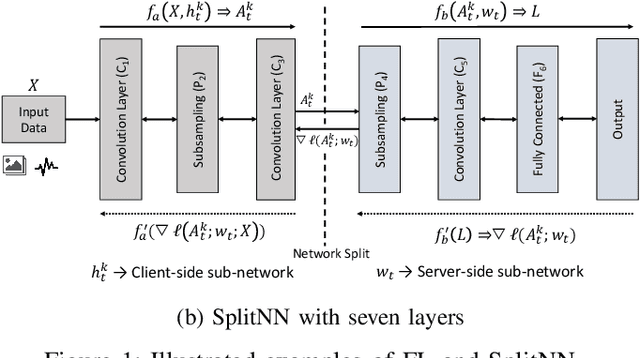
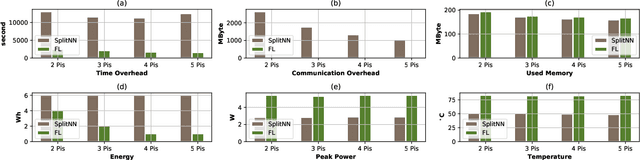
This work is the first attempt to evaluate and compare felderated learning (FL) and split neural networks (SplitNN) in real-world IoT settings in terms of learning performance and device implementation overhead. We consider a variety of datasets, different model architectures, multiple clients, and various performance metrics. For learning performance, which is specified by the model accuracy and convergence speed metrics, we empirically evaluate both FL and SplitNN under different types of data distributions such as imbalanced and non-independent and identically distributed (non-IID) data. We show that the learning performance of SplitNN is better than FL under an imbalanced data distribution, but worse than FL under an extreme non-IID data distribution. For implementation overhead, we end-to-end mount both FL and SplitNN on Raspberry Pis, and comprehensively evaluate overheads including training time, communication overhead under the real LAN setting, power consumption and memory usage. Our key observations are that under IoT scenario where the communication traffic is the main concern, the FL appears to perform better over SplitNN because FL has the significantly lower communication overhead compared with SplitNN, which empirically corroborate previous statistical analysis. In addition, we reveal several unrecognized limitations about SplitNN, forming the basis for future research.
Can We Use Split Learning on 1D CNN Models for Privacy Preserving Training?
Mar 16, 2020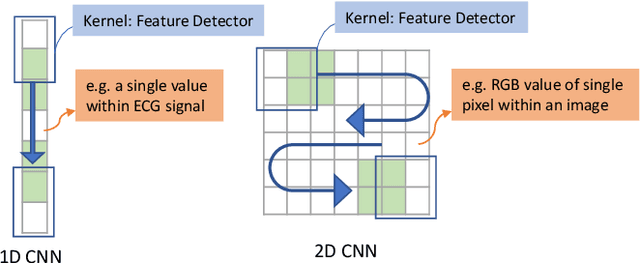
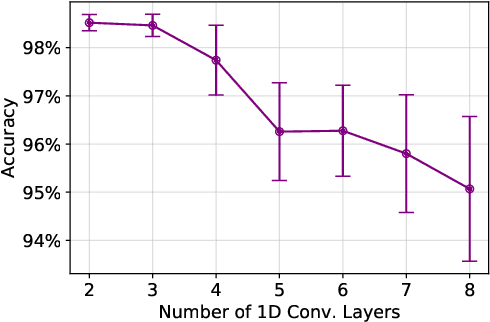
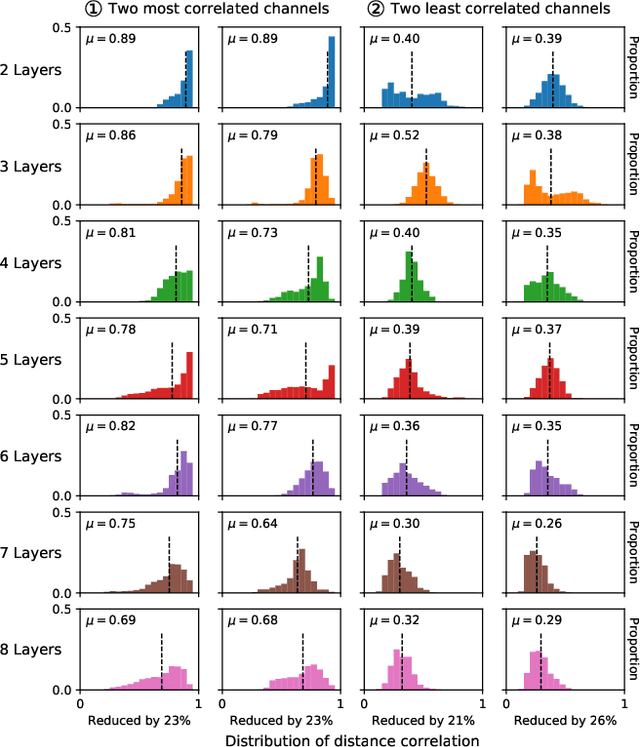
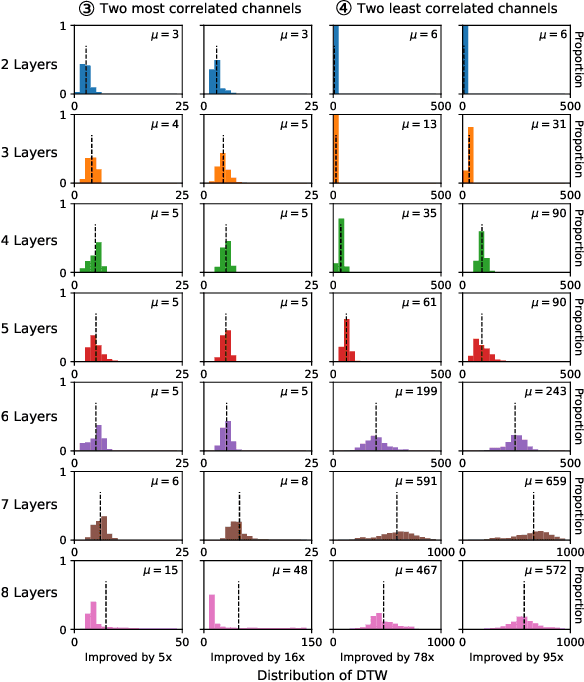
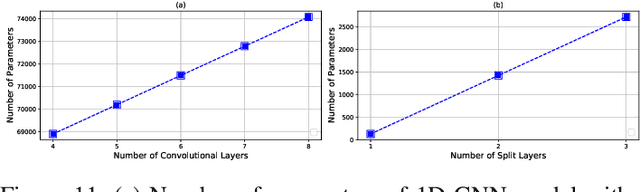
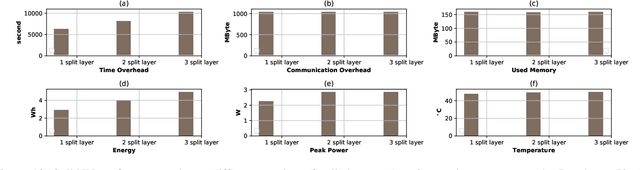
A new collaborative learning, called split learning, was recently introduced, aiming to protect user data privacy without revealing raw input data to a server. It collaboratively runs a deep neural network model where the model is split into two parts, one for the client and the other for the server. Therefore, the server has no direct access to raw data processed at the client. Until now, the split learning is believed to be a promising approach to protect the client's raw data; for example, the client's data was protected in healthcare image applications using 2D convolutional neural network (CNN) models. However, it is still unclear whether the split learning can be applied to other deep learning models, in particular, 1D CNN. In this paper, we examine whether split learning can be used to perform privacy-preserving training for 1D CNN models. To answer this, we first design and implement an 1D CNN model under split learning and validate its efficacy in detecting heart abnormalities using medical ECG data. We observed that the 1D CNN model under split learning can achieve the same accuracy of 98.9\% like the original (non-split) model. However, our evaluation demonstrates that split learning may fail to protect the raw data privacy on 1D CNN models. To address the observed privacy leakage in split learning, we adopt two privacy leakage mitigation techniques: 1) adding more hidden layers to the client side and 2) applying differential privacy. Although those mitigation techniques are helpful in reducing privacy leakage, they have a significant impact on model accuracy. Hence, based on those results, we conclude that split learning alone would not be sufficient to maintain the confidentiality of raw sequential data in 1D CNN models.