 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-model Machine Learning Inference Serving with GPU Spatial Partitioning
Sep 01, 2021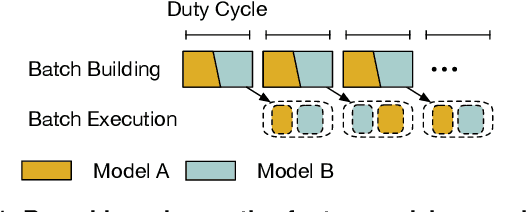

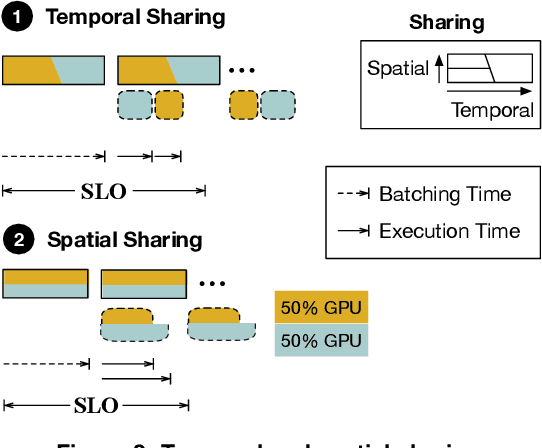
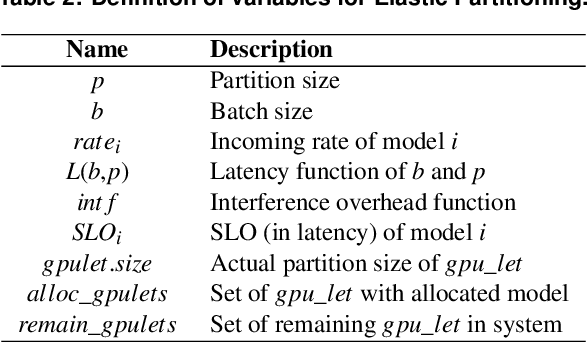
As machine learning techniques are applied to a widening range of applications, high throughput machine learning (ML) inference servers have become critical for online service applications. Such ML inference servers pose two challenges: first, they must provide a bounded latency for each request to support consistent service-level objective (SLO), and second, they can serve multiple heterogeneous ML models in a system as certain tasks involve invocation of multiple models and consolidating multiple models can improve system utilization. To address the two requirements of ML inference servers, this paper proposes a new ML inference scheduling framework for multi-model ML inference servers. The paper first shows that with SLO constraints, current GPUs are not fully utilized for ML inference tasks. To maximize the resource efficiency of inference servers, a key mechanism proposed in this paper is to exploit hardware support for spatial partitioning of GPU resources. With the partitioning mechanism, a new abstraction layer of GPU resources is created with configurable GPU resources. The scheduler assigns requests to virtual GPUs, called gpu-lets, with the most effective amount of resources. The paper also investigates a remedy for potential interference effects when two ML tasks are running concurrently in a GPU. Our prototype implementation proves that spatial partitioning enhances throughput by 102.6% on average while satisfying SLOs.
End-to-End Evaluation of Federated Learning and Split Learning for Internet of Things
Mar 30, 2020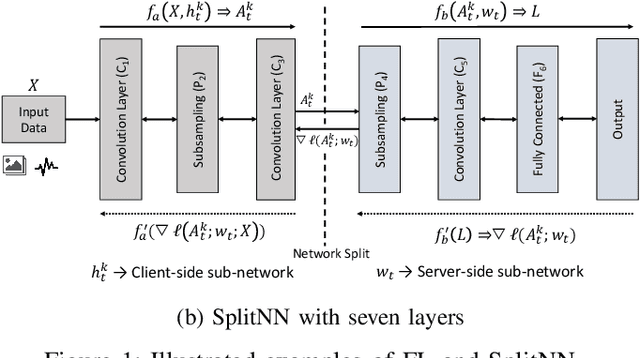
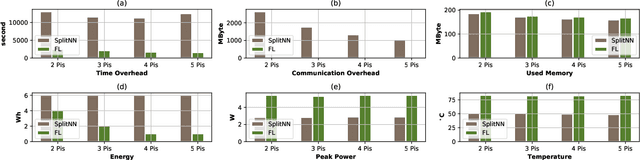
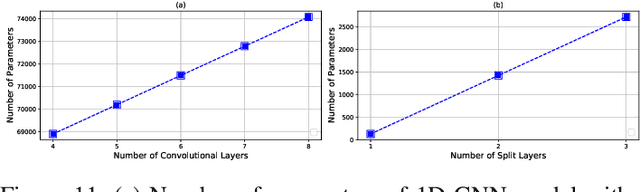
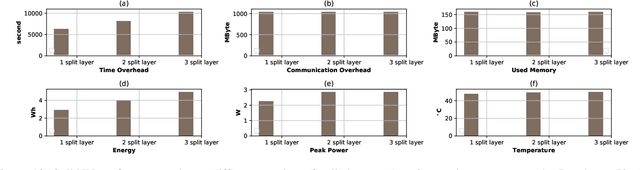
This work is the first attempt to evaluate and compare felderated learning (FL) and split neural networks (SplitNN) in real-world IoT settings in terms of learning performance and device implementation overhead. We consider a variety of datasets, different model architectures, multiple clients, and various performance metrics. For learning performance, which is specified by the model accuracy and convergence speed metrics, we empirically evaluate both FL and SplitNN under different types of data distributions such as imbalanced and non-independent and identically distributed (non-IID) data. We show that the learning performance of SplitNN is better than FL under an imbalanced data distribution, but worse than FL under an extreme non-IID data distribution. For implementation overhead, we end-to-end mount both FL and SplitNN on Raspberry Pis, and comprehensively evaluate overheads including training time, communication overhead under the real LAN setting, power consumption and memory usage. Our key observations are that under IoT scenario where the communication traffic is the main concern, the FL appears to perform better over SplitNN because FL has the significantly lower communication overhead compared with SplitNN, which empirically corroborate previous statistical analysis. In addition, we reveal several unrecognized limitations about SplitNN, forming the basis for future research.