 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMServingSim 2.0: A Unified Simulator for Heterogeneous and Disaggregated LLM Serving Infrastructure
Feb 26, 2026Large language model (LLM) serving infrastructures are undergoing a shift toward heterogeneity and disaggregation. Modern deployments increasingly integrate diverse accelerators and near-memory processing technologies, introducing significant hardware heterogeneity, while system software increasingly separates computation, memory, and model components across distributed resources to improve scalability and efficiency. As a result, LLM serving performance is no longer determined by hardware or software choices in isolation, but by their runtime interaction through scheduling, data movement, and interconnect behavior. However, understanding these interactions remains challenging, as existing simulators lack the ability to jointly model heterogeneous hardware and disaggregated serving techniques within a unified, runtime-driven framework. This paper presents LLMServingSim 2.0, a unified system-level simulator designed to make runtime-driven hardware-software interactions in heterogeneous and disaggregated LLM serving infrastructures explicit and analyzable. LLMServingSim 2.0 embeds serving decisions and hardware behavior into a single runtime loop, enabling interaction-aware modeling of batching, routing, offloading, memory, and power. The simulator supports extensible integration of emerging accelerators and memory systems through profile-based modeling, while capturing dynamic serving behavior and system-level effects. We validate LLMServingSim 2.0 against real deployments, showing that it reproduces key performance, memory, and power metrics with an average error of 0.97%, while maintaining simulation times of around 10 minutes even for complex configurations. These results demonstrate that LLMServingSim 2.0 provides a practical bridge between hardware innovation and serving-system design, enabling systematic exploration and co-design for next-generation LLM serving infrastructures.
Neo: Real-Time On-Device 3D Gaussian Splatting with Reuse-and-Update Sorting Acceleration
Nov 17, 2025



3D Gaussian Splatting (3DGS) rendering in real-time on resource-constrained devices is essential for delivering immersive augmented and virtual reality (AR/VR) experiences. However, existing solutions struggle to achieve high frame rates, especially for high-resolution rendering. Our analysis identifies the sorting stage in the 3DGS rendering pipeline as the major bottleneck due to its high memory bandwidth demand. This paper presents Neo, which introduces a reuse-and-update sorting algorithm that exploits temporal redundancy in Gaussian ordering across consecutive frames, and devises a hardware accelerator optimized for this algorithm. By efficiently tracking and updating Gaussian depth ordering instead of re-sorting from scratch, Neo significantly reduces redundant computations and memory bandwidth pressure. Experimental results show that Neo achieves up to 10.0x and 5.6x higher throughput than state-of-the-art edge GPU and ASIC solution, respectively, while reducing DRAM traffic by 94.5% and 81.3%. These improvements make high-quality and low-latency on-device 3D rendering more practical.
LLMServingSim2.0: A Unified Simulator for Heterogeneous Hardware and Serving Techniques in LLM Infrastructure
Nov 10, 2025



This paper introduces LLMServingSim2.0, a system simulator designed for exploring heterogeneous hardware in large-scale LLM serving systems. LLMServingSim2.0 addresses two key limitations of its predecessor: (1) integrating hardware models into system-level simulators is non-trivial due to the lack of a clear abstraction, and (2) existing simulators support only a narrow subset of serving techniques, leaving no infrastructure that captures the breadth of approaches in modern LLM serving. To overcome these issues, LLMServingSim2.0 adopts trace-driven performance modeling, accompanied by an operator-level latency profiler, enabling the integration of new accelerators with a single command. It further embeds up-to-date serving techniques while exposing flexible interfaces for request routing, cache management, and scheduling policies. In a TPU case study, our profiler requires 18.5x fewer LoC and outperforms the predecessor's hardware-simulator integration, demonstrating LLMServingSim2.0's low-effort hardware extensibility. Our experiments further show that LLMServingSim2.0 reproduces GPU-based LLM serving with 1.9% error, while maintaining practical simulation time, making it a comprehensive platform for both hardware developers and LLM service providers.
* 4 pages, 3 figures
Cocoon: A System Architecture for Differentially Private Training with Correlated Noises
Oct 08, 2025Machine learning (ML) models memorize and leak training data, causing serious privacy issues to data owners. Training algorithms with differential privacy (DP), such as DP-SGD, have been gaining attention as a solution. However, DP-SGD adds a noise at each training iteration, which degrades the accuracy of the trained model. To improve accuracy, a new family of approaches adds carefully designed correlated noises, so that noises cancel out each other across iterations. We performed an extensive characterization study of these new mechanisms, for the first time to the best of our knowledge, and show they incur non-negligible overheads when the model is large or uses large embedding tables. Motivated by the analysis, we propose Cocoon, a hardware-software co-designed framework for efficient training with correlated noises. Cocoon accelerates models with embedding tables through pre-computing and storing correlated noises in a coalesced format (Cocoon-Emb), and supports large models through a custom near-memory processing device (Cocoon-NMP). On a real system with an FPGA-based NMP device prototype, Cocoon improves the performance by 2.33-10.82x(Cocoon-Emb) and 1.55-3.06x (Cocoon-NMP).
Déjà Vu: Efficient Video-Language Query Engine with Learning-based Inter-Frame Computation Reuse
Jun 17, 2025Recently, Video-Language Models (VideoLMs) have demonstrated remarkable capabilities, offering significant potential for flexible and powerful video query systems. These models typically rely on Vision Transformers (ViTs), which process video frames individually to extract visual embeddings. However, generating embeddings for large-scale videos requires ViT inferencing across numerous frames, posing a major hurdle to real-world deployment and necessitating solutions for integration into scalable video data management systems. This paper introduces D\'ej\`a Vu, a video-language query engine that accelerates ViT-based VideoLMs by reusing computations across consecutive frames. At its core is ReuseViT, a modified ViT model specifically designed for VideoLM tasks, which learns to detect inter-frame reuse opportunities, striking an effective balance between accuracy and reuse. Although ReuseViT significantly reduces computation, these savings do not directly translate into performance gains on GPUs. To overcome this, D\'ej\`a Vu integrates memory-compute joint compaction techniques that convert the FLOP savings into tangible performance gains. Evaluations on three VideoLM tasks show that D\'ej\`a Vu accelerates embedding generation by up to a 2.64x within a 2% error bound, dramatically enhancing the practicality of VideoLMs for large-scale video analytics.
MixDiT: Accelerating Image Diffusion Transformer Inference with Mixed-Precision MX Quantization
Apr 11, 2025Diffusion Transformer (DiT) has driven significant progress in image generation tasks. However, DiT inferencing is notoriously compute-intensive and incurs long latency even on datacenter-scale GPUs, primarily due to its iterative nature and heavy reliance on GEMM operations inherent to its encoder-based structure. To address the challenge, prior work has explored quantization, but achieving low-precision quantization for DiT inferencing with both high accuracy and substantial speedup remains an open problem. To this end, this paper proposes MixDiT, an algorithm-hardware co-designed acceleration solution that exploits mixed Microscaling (MX) formats to quantize DiT activation values. MixDiT quantizes the DiT activation tensors by selectively applying higher precision to magnitude-based outliers, which produce mixed-precision GEMM operations. To achieve tangible speedup from the mixed-precision arithmetic, we design a MixDiT accelerator that enables precision-flexible multiplications and efficient MX precision conversions. Our experimental results show that MixDiT delivers a speedup of 2.10-5.32 times over RTX 3090, with no loss in FID.
Oaken: Fast and Efficient LLM Serving with Online-Offline Hybrid KV Cache Quantization
Mar 24, 2025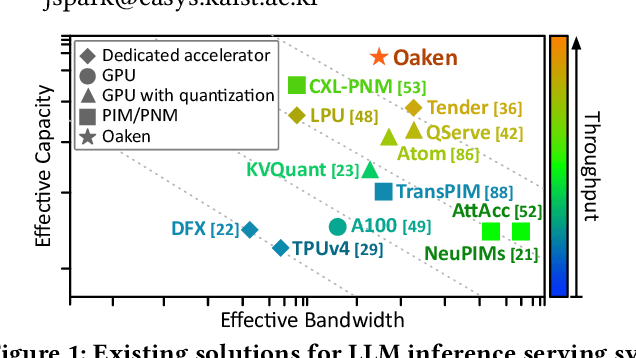

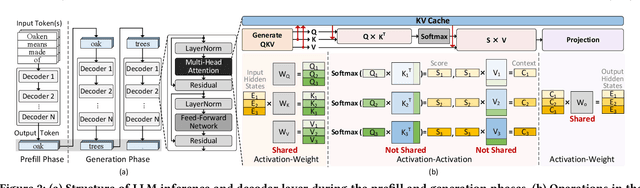
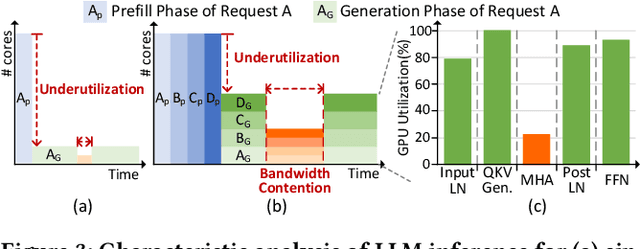
Modern Large Language Model serving system batches multiple requests to achieve high throughput, while batching attention operations is challenging, rendering memory bandwidth a critical bottleneck. The community relies on high-end GPUs with multiple high-bandwidth memory channels. Unfortunately, HBM's high bandwidth often comes at the expense of limited memory capacity, which reduces core utilization and increases costs. Recent advancements enabling longer contexts for LLMs have substantially increased the key-value cache size, further intensifying the pressures on memory capacity. The literature has explored KV cache quantization techniques, which commonly use low bitwidth for most values, selectively using higher bitwidth for outlier values. While this approach helps achieve high accuracy and low bitwidth simultaneously, it comes with the limitation that cost for online outlier detection is excessively high, negating the advantages. We propose Oaken, an acceleration solution that achieves high accuracy and high performance simultaneously through co-designing algorithm and hardware. To effectively find a sweet spot in the accuracy-performance trade-off space of KV cache quantization, Oaken employs an online-offline hybrid approach, setting outlier thresholds offline, which are then used to determine the quantization scale online. To translate the proposed algorithmic technique into tangible performance gains, Oaken also comes with custom quantization engines and memory management units that can be integrated with any LLM accelerators. We built an Oaken accelerator on top of an LLM accelerator, LPU, and conducted a comprehensive evaluation. Our experiments show that for a batch size of 256, Oaken achieves up to 1.58x throughput improvement over NVIDIA A100 GPU, incurring a minimal accuracy loss of only 0.54\% on average, compared to state-of-the-art KV cache quantization techniques.
LLMServingSim: A HW/SW Co-Simulation Infrastructure for LLM Inference Serving at Scale
Aug 10, 2024Recently, there has been an extensive research effort in building efficient large language model (LLM) inference serving systems. These efforts not only include innovations in the algorithm and software domains but also constitute developments of various hardware acceleration techniques. Nevertheless, there is a lack of simulation infrastructure capable of accurately modeling versatile hardware-software behaviors in LLM serving systems without extensively extending the simulation time. This paper aims to develop an effective simulation tool, called LLMServingSim, to support future research in LLM serving systems. In designing LLMServingSim, we focus on two limitations of existing simulators: (1) they lack consideration of the dynamic workload variations of LLM inference serving due to its autoregressive nature, and (2) they incur repetitive simulations without leveraging algorithmic redundancies in LLMs. To address these limitations, LLMServingSim simulates the LLM serving in the granularity of iterations, leveraging the computation redundancies across decoder blocks and reusing the simulation results from previous iterations. Additionally, LLMServingSim provides a flexible framework that allows users to plug in any accelerator compiler-and-simulation stacks for exploring various system designs with heterogeneous processors. Our experiments demonstrate that LLMServingSim produces simulation results closely following the performance behaviors of real GPU-based LLM serving system with less than 14.7% error rate, while offering 91.5x faster simulation speed compared to existing accelerator simulators.
DaCapo: Accelerating Continuous Learning in Autonomous Systems for Video Analytics
Mar 21, 2024Deep neural network (DNN) video analytics is crucial for autonomous systems such as self-driving vehicles, unmanned aerial vehicles (UAVs), and security robots. However, real-world deployment faces challenges due to their limited computational resources and battery power. To tackle these challenges, continuous learning exploits a lightweight "student" model at deployment (inference), leverages a larger "teacher" model for labeling sampled data (labeling), and continuously retrains the student model to adapt to changing scenarios (retraining). This paper highlights the limitations in state-of-the-art continuous learning systems: (1) they focus on computations for retraining, while overlooking the compute needs for inference and labeling, (2) they rely on power-hungry GPUs, unsuitable for battery-operated autonomous systems, and (3) they are located on a remote centralized server, intended for multi-tenant scenarios, again unsuitable for autonomous systems due to privacy, network availability, and latency concerns. We propose a hardware-algorithm co-designed solution for continuous learning, DaCapo, that enables autonomous systems to perform concurrent executions of inference, labeling, and training in a performant and energy-efficient manner. DaCapo comprises (1) a spatially-partitionable and precision-flexible accelerator enabling parallel execution of kernels on sub-accelerators at their respective precisions, and (2) a spatiotemporal resource allocation algorithm that strategically navigates the resource-accuracy tradeoff space, facilitating optimal decisions for resource allocation to achieve maximal accuracy. Our evaluation shows that DaCapo achieves 6.5% and 5.5% higher accuracy than a state-of-the-art GPU-based continuous learning systems, Ekya and EOMU, respectively, while consuming 254x less power.
Accelerating String-Key Learned Index Structures via Memoization-based Incremental Training
Mar 18, 2024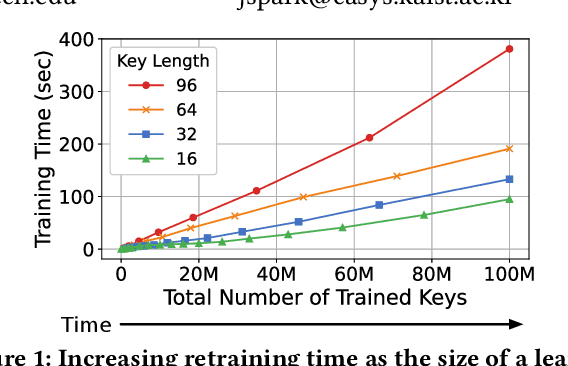
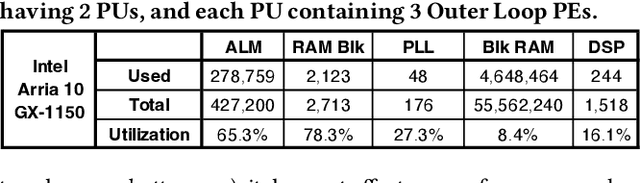
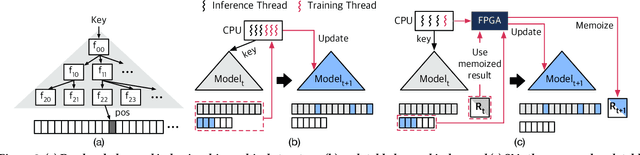
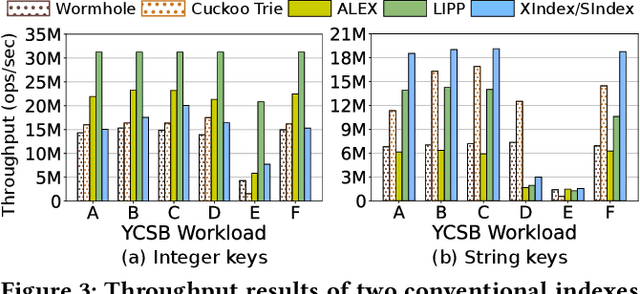
Learned indexes use machine learning models to learn the mappings between keys and their corresponding positions in key-value indexes. These indexes use the mapping information as training data. Learned indexes require frequent retrainings of their models to incorporate the changes introduced by update queries. To efficiently retrain the models, existing learned index systems often harness a linear algebraic QR factorization technique that performs matrix decomposition. This factorization approach processes all key-position pairs during each retraining, resulting in compute operations that grow linearly with the total number of keys and their lengths. Consequently, the retrainings create a severe performance bottleneck, especially for variable-length string keys, while the retrainings are crucial for maintaining high prediction accuracy and in turn, ensuring low query service latency. To address this performance problem, we develop an algorithm-hardware co-designed string-key learned index system, dubbed SIA. In designing SIA, we leverage a unique algorithmic property of the matrix decomposition-based training method. Exploiting the property, we develop a memoization-based incremental training scheme, which only requires computation over updated keys, while decomposition results of non-updated keys from previous computations can be reused. We further enhance SIA to offload a portion of this training process to an FPGA accelerator to not only relieve CPU resources for serving index queries (i.e., inference), but also accelerate the training itself. Our evaluation shows that compared to ALEX, LIPP, and SIndex, a state-of-the-art learned index systems, SIA-accelerated learned indexes offer 2.6x and 3.4x higher throughput on the two real-world benchmark suites, YCSB and Twitter cache trace, respectively.