 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarthSight: A Distributed Framework for Low-Latency Satellite Intelligence
Nov 13, 2025Low-latency delivery of satellite imagery is essential for time-critical applications such as disaster response, intelligence, and infrastructure monitoring. However, traditional pipelines rely on downlinking all captured images before analysis, introducing delays of hours to days due to restricted communication bandwidth. To address these bottlenecks, emerging systems perform onboard machine learning to prioritize which images to transmit. However, these solutions typically treat each satellite as an isolated compute node, limiting scalability and efficiency. Redundant inference across satellites and tasks further strains onboard power and compute costs, constraining mission scope and responsiveness. We present EarthSight, a distributed runtime framework that redefines satellite image intelligence as a distributed decision problem between orbit and ground. EarthSight introduces three core innovations: (1) multi-task inference on satellites using shared backbones to amortize computation across multiple vision tasks; (2) a ground-station query scheduler that aggregates user requests, predicts priorities, and assigns compute budgets to incoming imagery; and (3) dynamic filter ordering, which integrates model selectivity, accuracy, and execution cost to reject low-value images early and conserve resources. EarthSight leverages global context from ground stations and resource-aware adaptive decisions in orbit to enable constellations to perform scalable, low-latency image analysis within strict downlink bandwidth and onboard power budgets. Evaluations using a prior established satellite simulator show that EarthSight reduces average compute time per image by 1.9x and lowers 90th percentile end-to-end latency from first contact to delivery from 51 to 21 minutes compared to the state-of-the-art baseline.
Carbon Aware Transformers Through Joint Model-Hardware Optimization
May 02, 2025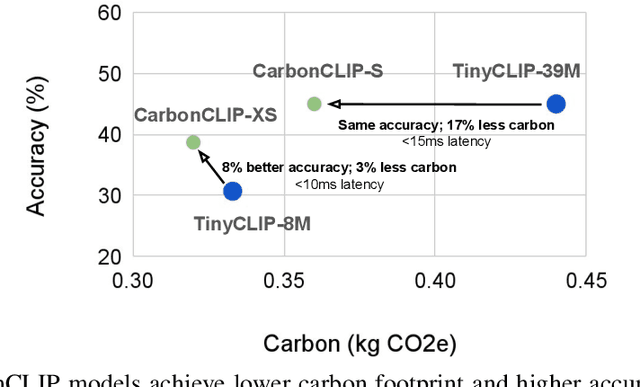
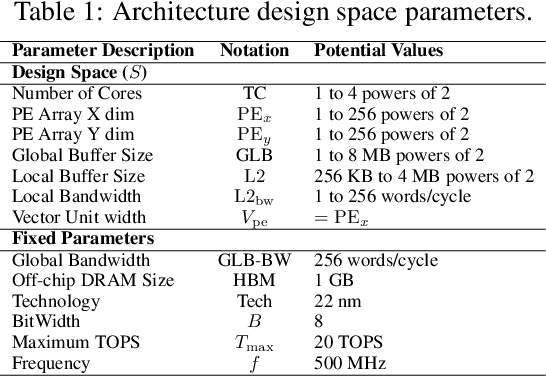
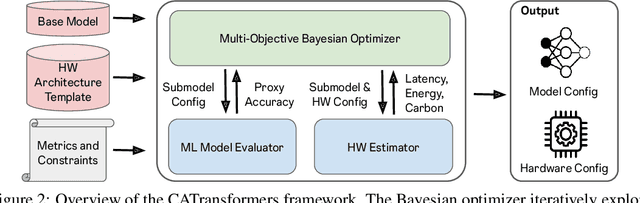
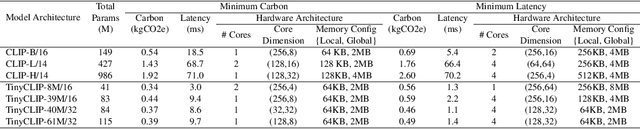
The rapid growth of machine learning (ML) systems necessitates a more comprehensive evaluation of their environmental impact, particularly their carbon footprint, which comprises operational carbon from training and inference execution and embodied carbon from hardware manufacturing and its entire life-cycle. Despite the increasing importance of embodied emissions, there is a lack of tools and frameworks to holistically quantify and optimize the total carbon footprint of ML systems. To address this, we propose CATransformers, a carbon-aware architecture search framework that enables sustainability-driven co-optimization of ML models and hardware architectures. By incorporating both operational and embodied carbon metrics into early design space exploration of domain-specific hardware accelerators, CATransformers demonstrates that optimizing for carbon yields design choices distinct from those optimized solely for latency or energy efficiency. We apply our framework to multi-modal CLIP-based models, producing CarbonCLIP, a family of CLIP models achieving up to 17% reduction in total carbon emissions while maintaining accuracy and latency compared to state-of-the-art edge small CLIP baselines. This work underscores the need for holistic optimization methods to design high-performance, environmentally sustainable AI systems.
An Adaptive Vector Index Partitioning Scheme for Low-Latency RAG Pipeline
Apr 11, 2025Retrieval Augmented Generation (RAG) systems enhance response quality by integrating Large Language Models (LLMs) with vector databases, enabling external knowledge retrieval to support language model reasoning. While RAG enables efficient question answering with smaller LLMs, existing optimizations for vector search and LLM serving have largely been developed in isolation. As a result, their integration often leads to suboptimal end-to-end performance. ... This paper introduces VectorLiteRAG, an optimized vector index partitioning mechanism designed for RAG systems that enhances the responsiveness of the system by jointly optimizing vector search and LLM serving across CPU and GPU system. A key challenge is to determine which indices and how much of the vector index should reside on the GPU and adjusting LLM batch sizes to balance the pipeline for lower Time-To-First-Token (TTFT) and meeting user-defined Service-Level Objectives (SLOs). To address this, we leverage the insight that cluster access in vector databases exhibits access skew, where a subset of clusters are queried significantly more frequently than others. VectorLiteRAG exploits this property through an optimized memory distribution strategy, dynamically allocating the minimum number of vector indices corresponding to frequently accessed clusters onto the GPU HBM to ensure a balanced pipeline with the LLM for high responsiveness. This adaptive partitioning scheme is guided by a statistical model that informs memory allocation and workload distribution. Our evaluation demonstrates that VectorLiteRAG improves vector search responsiveness by 2x, significantly reduces end-to-end TTFT in RAG systems by intelligently balancing memory resources between vector search and LLM execution.
MoETuner: Optimized Mixture of Expert Serving with Balanced Expert Placement and Token Routing
Feb 10, 2025Mixture-of-Experts (MoE) model architecture has emerged as a promising solution for scaling transformer models efficiently, offering sparse activation that reduces computational costs while increasing model capacity. However, as MoE models scale, they need to be distributed across GPU devices, thus face critical performance bottlenecks due to their large memory footprint. Expert parallelism distributes experts across GPUs, however, faces key challenges including an unbalanced token routing and expert activation, resulting in communication tail latency and processing inefficiencies. While existing solutions address some of these issues, they fail to resolve the dual challenges of load imbalance and communication skew. The imbalance in token processing load across experts causes uneven processing times on different GPUs, while communication skew between GPUs leads to unbalanced inter-GPU data transfers. These factors degrade the performance of MoE models by increasing tail latency and reducing overall throughput. To address these limitations, we propose an Integer Linear Programming (ILP) formulation to optimize expert placement by jointly considering token load, communication, and computation costs. We exploit the property that there is a token routing dependency across layers, where tokens routed to a specific expert in one layer are likely to be routed to a limited set of experts in the subsequent layer. Our solution, MoETuner, offers an optimal expert-to-GPU assignment that minimizes inter-GPU token routing costs and balances token processing across devices, thereby reducing tail latency and end-to-end execution time. Experimental results demonstrate 9.3% and 17.5% of end-to-end speedups for single-node and multi-node inference respectively, showcasing the potential of our ILP-based optimization for offering expert parallel solutions for next-generation MoEs.
Integrated Hardware Architecture and Device Placement Search
Jul 18, 2024



Distributed execution of deep learning training involves a dynamic interplay between hardware accelerator architecture and device placement strategy. This is the first work to explore the co-optimization of determining the optimal architecture and device placement strategy through novel algorithms, improving the balance of computational resources, memory usage, and data distribution. Our architecture search leverages tensor and vector units, determining their quantity and dimensionality, and on-chip and off-chip memory configurations. It also determines the microbatch size and decides whether to recompute or stash activations, balancing the memory footprint of training and storage size. For each explored architecture configuration, we use an Integer Linear Program (ILP) to find the optimal schedule for executing operators on the accelerator. The ILP results then integrate with a dynamic programming solution to identify the most effective device placement strategy, combining data, pipeline, and tensor model parallelism across multiple accelerators. Our approach achieves higher throughput on large language models compared to the state-of-the-art TPUv4 and the Spotlight accelerator search framework. The entire source code of PHAZE is available at https://github.com/msr-fiddle/phaze.
Data-driven Forecasting of Deep Learning Performance on GPUs
Jul 18, 2024Deep learning kernels exhibit predictable memory accesses and compute patterns, making GPUs' parallel architecture well-suited for their execution. Software and runtime systems for GPUs are optimized to better utilize the stream multiprocessors, on-chip cache, and off-chip high-bandwidth memory. As deep learning models and GPUs evolve, access to newer GPUs is often limited, raising questions about the performance of new model architectures on existing GPUs, existing models on new GPUs, and new model architectures on new GPUs. To address these questions, we introduce NeuSight, a framework to predict the performance of various deep learning models, for both training and inference, on unseen GPUs without requiring actual execution. The framework leverages both GPU hardware behavior and software library optimizations to estimate end-to-end performance. Previous work uses regression models that capture linear trends or multilayer perceptrons to predict the overall latency of deep learning kernels on GPUs. These approaches suffer from higher error percentages when forecasting performance on unseen models and new GPUs. Instead, NeuSight decomposes the prediction problem into smaller problems, bounding the prediction through fundamental performance laws. NeuSight decomposes a single deep learning kernel prediction into smaller working sets called tiles, which are executed independently on the GPU. Tile-granularity predictions are determined using a machine learning approach and aggregated to estimate end-to-end latency. NeuSight outperforms prior work across various deep learning workloads and the latest GPUs. It reduces the percentage error from 198% and 19.7% to 3.8% in predicting the latency of GPT3 model for training and inference on H100, compared to state-of-the-art prior works, where both GPT3 and H100 were not used to train the framework.
Accelerating Recommender Model Training by Dynamically Skipping Stale Embeddings
Mar 22, 2024Training recommendation models pose significant challenges regarding resource utilization and performance. Prior research has proposed an approach that categorizes embeddings into popular and non-popular classes to reduce the training time for recommendation models. We observe that, even among the popular embeddings, certain embeddings undergo rapid training and exhibit minimal subsequent variation, resulting in saturation. Consequently, updates to these embeddings lack any contribution to model quality. This paper presents Slipstream, a software framework that identifies stale embeddings on the fly and skips their updates to enhance performance. This capability enables Slipstream to achieve substantial speedup, optimize CPU-GPU bandwidth usage, and eliminate unnecessary memory access. SlipStream showcases training time reductions of 2x, 2.4x, 1.2x, and 1.175x across real-world datasets and configurations, compared to Baseline XDL, Intel-optimized DRLM, FAE, and Hotline, respectively.
Accelerating String-Key Learned Index Structures via Memoization-based Incremental Training
Mar 18, 2024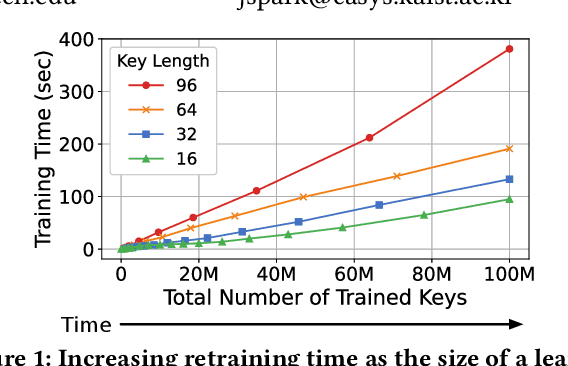
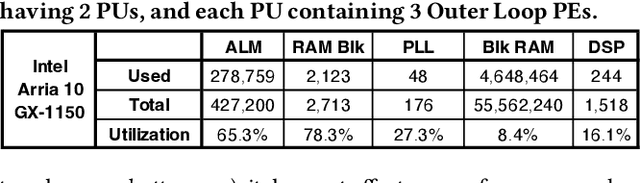
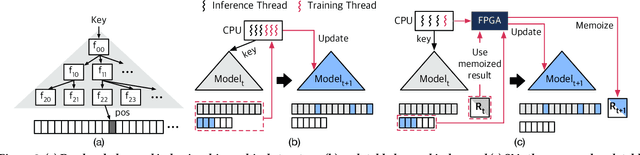
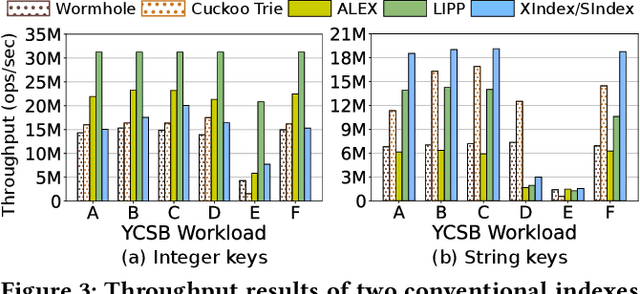
Learned indexes use machine learning models to learn the mappings between keys and their corresponding positions in key-value indexes. These indexes use the mapping information as training data. Learned indexes require frequent retrainings of their models to incorporate the changes introduced by update queries. To efficiently retrain the models, existing learned index systems often harness a linear algebraic QR factorization technique that performs matrix decomposition. This factorization approach processes all key-position pairs during each retraining, resulting in compute operations that grow linearly with the total number of keys and their lengths. Consequently, the retrainings create a severe performance bottleneck, especially for variable-length string keys, while the retrainings are crucial for maintaining high prediction accuracy and in turn, ensuring low query service latency. To address this performance problem, we develop an algorithm-hardware co-designed string-key learned index system, dubbed SIA. In designing SIA, we leverage a unique algorithmic property of the matrix decomposition-based training method. Exploiting the property, we develop a memoization-based incremental training scheme, which only requires computation over updated keys, while decomposition results of non-updated keys from previous computations can be reused. We further enhance SIA to offload a portion of this training process to an FPGA accelerator to not only relieve CPU resources for serving index queries (i.e., inference), but also accelerate the training itself. Our evaluation shows that compared to ALEX, LIPP, and SIndex, a state-of-the-art learned index systems, SIA-accelerated learned indexes offer 2.6x and 3.4x higher throughput on the two real-world benchmark suites, YCSB and Twitter cache trace, respectively.
Ad-Rec: Advanced Feature Interactions to Address Covariate-Shifts in Recommendation Networks
Aug 28, 2023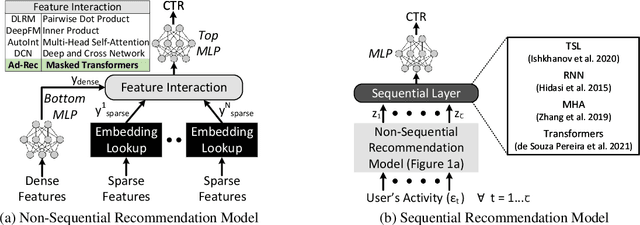
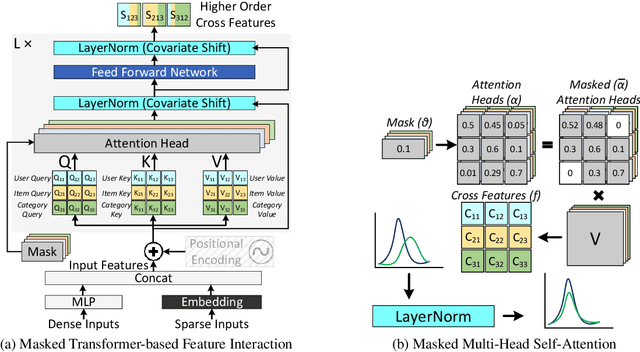

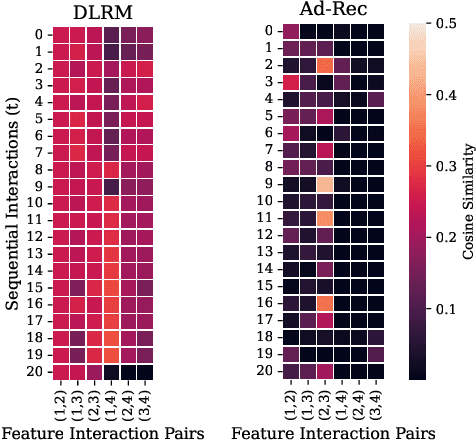
Recommendation models are vital in delivering personalized user experiences by leveraging the correlation between multiple input features. However, deep learning-based recommendation models often face challenges due to evolving user behaviour and item features, leading to covariate shifts. Effective cross-feature learning is crucial to handle data distribution drift and adapting to changing user behaviour. Traditional feature interaction techniques have limitations in achieving optimal performance in this context. This work introduces Ad-Rec, an advanced network that leverages feature interaction techniques to address covariate shifts. This helps eliminate irrelevant interactions in recommendation tasks. Ad-Rec leverages masked transformers to enable the learning of higher-order cross-features while mitigating the impact of data distribution drift. Our approach improves model quality, accelerates convergence, and reduces training time, as measured by the Area Under Curve (AUC) metric. We demonstrate the scalability of Ad-Rec and its ability to achieve superior model quality through comprehensive ablation studies.
FLuID: Mitigating Stragglers in Federated Learning using Invariant Dropout
Jul 10, 2023Federated Learning (FL) allows machine learning models to train locally on individual mobile devices, synchronizing model updates via a shared server. This approach safeguards user privacy; however, it also generates a heterogeneous training environment due to the varying performance capabilities across devices. As a result, straggler devices with lower performance often dictate the overall training time in FL. In this work, we aim to alleviate this performance bottleneck due to stragglers by dynamically balancing the training load across the system. We introduce Invariant Dropout, a method that extracts a sub-model based on the weight update threshold, thereby minimizing potential impacts on accuracy. Building on this dropout technique, we develop an adaptive training framework, Federated Learning using Invariant Dropout (FLuID). FLuID offers a lightweight sub-model extraction to regulate computational intensity, thereby reducing the load on straggler devices without affecting model quality. Our method leverages neuron updates from non-straggler devices to construct a tailored sub-model for each straggler based on client performance profiling. Furthermore, FLuID can dynamically adapt to changes in stragglers as runtime conditions shift. We evaluate FLuID using five real-world mobile clients. The evaluations show that Invariant Dropout maintains baseline model efficiency while alleviating the performance bottleneck of stragglers through a dynamic, runtime approach.