 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Synthetic Data in LLM Pre-training: A Systematic Study of Scaling Laws, Benefits, and Pitfalls
Oct 02, 2025Training data plays a crucial role in Large Language Models (LLM) scaling, yet high quality data is of limited supply. Synthetic data techniques offer a potential path toward sidestepping these limitations. We conduct a large-scale empirical investigation (>1000 LLMs with >100k GPU hours) using a unified protocol and scaling laws, comparing natural web data, diverse synthetic types (rephrased text, generated textbooks), and mixtures of natural and synthetic data. Specifically, we found pre-training on rephrased synthetic data \textit{alone} is not faster than pre-training on natural web texts; while pre-training on 1/3 rephrased synthetic data mixed with 2/3 natural web texts can speed up 5-10x (to reach the same validation loss) at larger data budgets. Pre-training on textbook-style synthetic data \textit{alone} results in notably higher loss on many downstream domains especially at small data budgets. "Good" ratios of synthetic data in training data mixtures depend on the model size and data budget, empirically converging to ~30% for rephrased synthetic data. Larger generator models do not necessarily yield better pre-training data than ~8B-param models. These results contribute mixed evidence on "model collapse" during large-scale single-round (n=1) model training on synthetic data--training on rephrased synthetic data shows no degradation in performance in foreseeable scales whereas training on mixtures of textbook-style pure-generated synthetic data shows patterns predicted by "model collapse". Our work demystifies synthetic data in pre-training, validates its conditional benefits, and offers practical guidance.
Quagmires in SFT-RL Post-Training: When High SFT Scores Mislead and What to Use Instead
Oct 02, 2025In post-training for reasoning Large Language Models (LLMs), the current state of practice trains LLMs in two independent stages: Supervised Fine-Tuning (SFT) and Reinforcement Learning with Verifiable Rewards (RLVR, shortened as ``RL'' below). In this work, we challenge whether high SFT scores translate to improved performance after RL. We provide extensive counter-examples where this is not true. We find high SFT scores can be biased toward simpler or more homogeneous data and are not reliably predictive of subsequent RL gains or scaled-up post-training effectiveness. In some cases, RL training on models with improved SFT performance could lead to substantially worse outcome compared to RL on the base model without SFT. We study alternative metrics and identify generalization loss on held-out reasoning examples and Pass@large k performance to provide strong proxies for the RL outcome. We trained hundreds of models up to 12B-parameter with SFT and RLVR via GRPO and ran extensive evaluations on 7 math benchmarks with up to 256 repetitions, spending $>$1M GPU hours. Experiments include models from Llama3, Mistral-Nemo, Qwen3 and multiple state-of-the-art SFT/RL datasets. Compared to directly predicting from pre-RL performance, prediction based on generalization loss and Pass@large k achieves substantial higher precision, improving $R^2$ coefficient and Spearman's rank correlation coefficient by up to 0.5 (2x). This provides strong utility for broad use cases. For example, in most experiments, we find SFT training on unique examples for a one epoch underperforms training on half examples for two epochs, either after SFT or SFT-then-RL; With the same SFT budget, training only on short examples may lead to better SFT performance, though, it often leads to worse outcome after RL compared to training on examples with varying lengths. Evaluation tool will be open-sourced.
Carbon Aware Transformers Through Joint Model-Hardware Optimization
May 02, 2025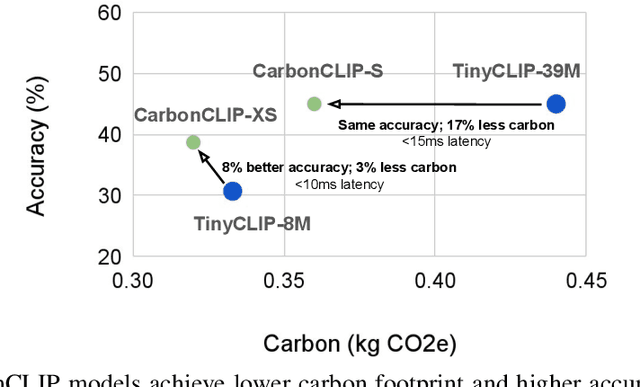
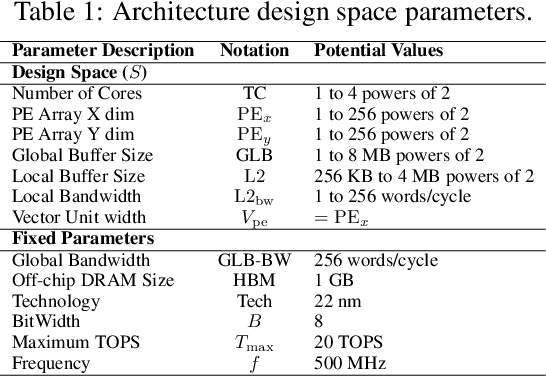
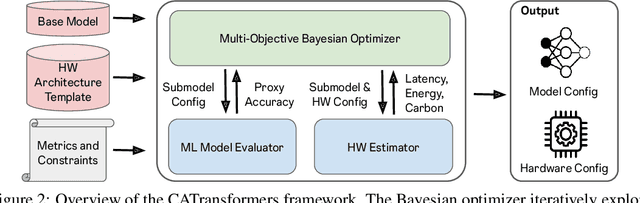
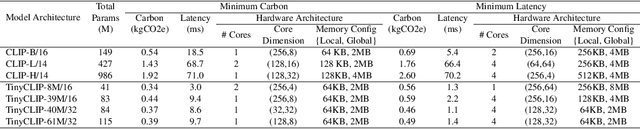
The rapid growth of machine learning (ML) systems necessitates a more comprehensive evaluation of their environmental impact, particularly their carbon footprint, which comprises operational carbon from training and inference execution and embodied carbon from hardware manufacturing and its entire life-cycle. Despite the increasing importance of embodied emissions, there is a lack of tools and frameworks to holistically quantify and optimize the total carbon footprint of ML systems. To address this, we propose CATransformers, a carbon-aware architecture search framework that enables sustainability-driven co-optimization of ML models and hardware architectures. By incorporating both operational and embodied carbon metrics into early design space exploration of domain-specific hardware accelerators, CATransformers demonstrates that optimizing for carbon yields design choices distinct from those optimized solely for latency or energy efficiency. We apply our framework to multi-modal CLIP-based models, producing CarbonCLIP, a family of CLIP models achieving up to 17% reduction in total carbon emissions while maintaining accuracy and latency compared to state-of-the-art edge small CLIP baselines. This work underscores the need for holistic optimization methods to design high-performance, environmentally sustainable AI systems.
Text Quality-Based Pruning for Efficient Training of Language Models
Apr 26, 2024



In recent times training Language Models (LMs) have relied on computationally heavy training over massive datasets which makes this training process extremely laborious. In this paper we propose a novel method for numerically evaluating text quality in large unlabelled NLP datasets in a model agnostic manner to assign the text instances a "quality score". By proposing the text quality metric, the paper establishes a framework to identify and eliminate low-quality text instances, leading to improved training efficiency for LM models. Experimental results over multiple models and datasets demonstrate the efficacy of this approach, showcasing substantial gains in training effectiveness and highlighting the potential for resource-efficient LM training. For example, we observe an absolute accuracy improvement of 0.9% averaged over 14 downstream evaluation tasks for multiple LM models while using 40% lesser data and training 42% faster when training on the OpenWebText dataset and 0.8% average absolute accuracy improvement while using 20% lesser data and training 21% faster on the Wikipedia dataset.
Decoding Data Quality via Synthetic Corruptions: Embedding-guided Pruning of Code Data
Dec 05, 2023Code datasets, often collected from diverse and uncontrolled sources such as GitHub, potentially suffer from quality issues, thereby affecting the performance and training efficiency of Large Language Models (LLMs) optimized for code generation. Previous studies demonstrated the benefit of using embedding spaces for data pruning, but they mainly focused on duplicate removal or increasing variety, and in other modalities, such as images. Our work focuses on using embeddings to identify and remove "low-quality" code data. First, we explore features of "low-quality" code in embedding space, through the use of synthetic corruptions. Armed with this knowledge, we devise novel pruning metrics that operate in embedding space to identify and remove low-quality entries in the Stack dataset. We demonstrate the benefits of this synthetic corruption informed pruning (SCIP) approach on the well-established HumanEval and MBPP benchmarks, outperforming existing embedding-based methods. Importantly, we achieve up to a 3% performance improvement over no pruning, thereby showing the promise of insights from synthetic corruptions for data pruning.
Data Acquisition: A New Frontier in Data-centric AI
Nov 22, 2023



As Machine Learning (ML) systems continue to grow, the demand for relevant and comprehensive datasets becomes imperative. There is limited study on the challenges of data acquisition due to ad-hoc processes and lack of consistent methodologies. We first present an investigation of current data marketplaces, revealing lack of platforms offering detailed information about datasets, transparent pricing, standardized data formats. With the objective of inciting participation from the data-centric AI community, we then introduce the DAM challenge, a benchmark to model the interaction between the data providers and acquirers. The benchmark was released as a part of DataPerf. Our evaluation of the submitted strategies underlines the need for effective data acquisition strategies in ML.
MAD Max Beyond Single-Node: Enabling Large Machine Learning Model Acceleration on Distributed Systems
Oct 18, 2023Training and deploying large machine learning (ML) models is time-consuming and requires significant distributed computing infrastructures. Based on real-world large model training on datacenter-scale infrastructures, we show 14~32% of all GPU hours are spent on communication with no overlapping computation. To minimize the outstanding communication latency, in this work, we develop an agile performance modeling framework to guide parallelization and hardware-software co-design strategies. Using the suite of real-world large ML models on state-of-the-art GPU training hardware, we demonstrate 2.24x and 5.27x throughput improvement potential for pre-training and inference scenarios, respectively.
SIEVE: Multimodal Dataset Pruning Using Image Captioning Models
Oct 03, 2023
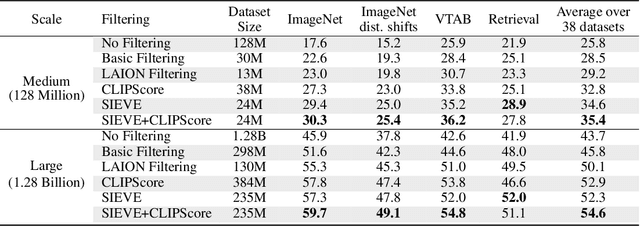
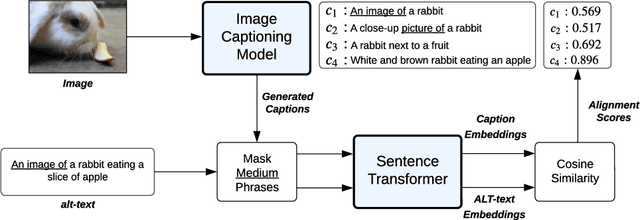
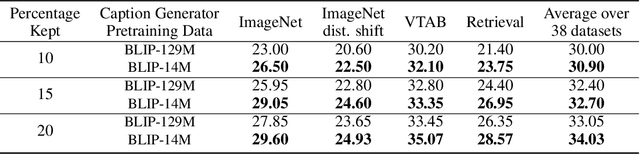
Vision-Language Models (VLMs) are pretrained on large, diverse, and noisy web-crawled datasets. This underscores the critical need for dataset pruning, as the quality of these datasets is strongly correlated with the performance of VLMs on downstream tasks. Using CLIPScore from a pretrained model to only train models using highly-aligned samples is one of the most successful methods for pruning.We argue that this approach suffers from multiple limitations including: 1) false positives due to spurious correlations captured by the pretrained CLIP model, 2) false negatives due to poor discrimination between hard and bad samples, and 3) biased ranking towards samples similar to the pretrained CLIP dataset. We propose a pruning method, SIEVE, that employs synthetic captions generated by image-captioning models pretrained on small, diverse, and well-aligned image-text pairs to evaluate the alignment of noisy image-text pairs. To bridge the gap between the limited diversity of generated captions and the high diversity of alternative text (alt-text), we estimate the semantic textual similarity in the embedding space of a language model pretrained on billions of sentences. Using DataComp, a multimodal dataset filtering benchmark, we achieve state-of-the-art performance on the large scale pool, and competitive results on the medium scale pool, surpassing CLIPScore-based filtering by 1.7% and 2.6% on average, on 38 downstream tasks.
Towards MoE Deployment: Mitigating Inefficiencies in Mixture-of-Expert (MoE) Inference
Mar 10, 2023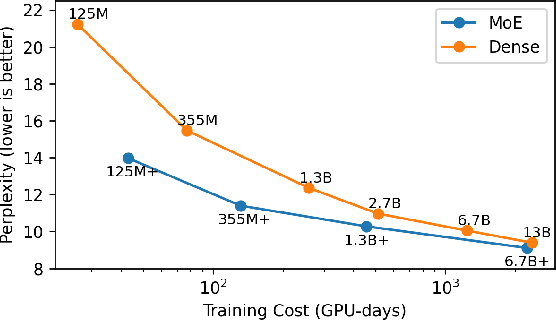
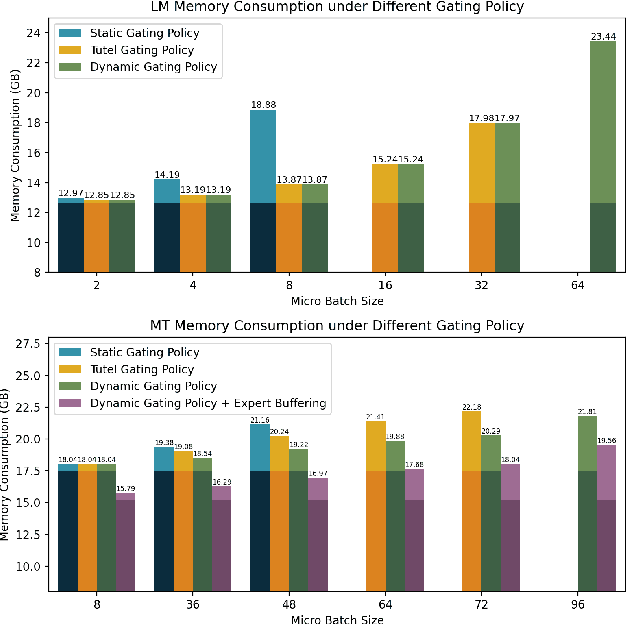
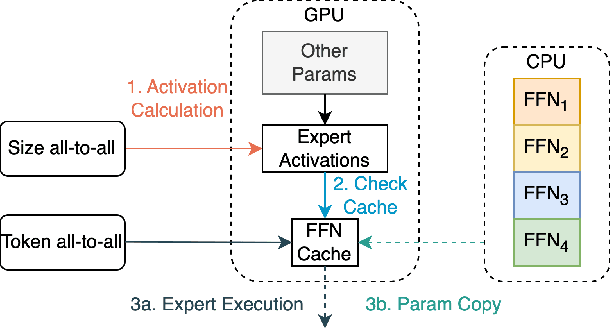
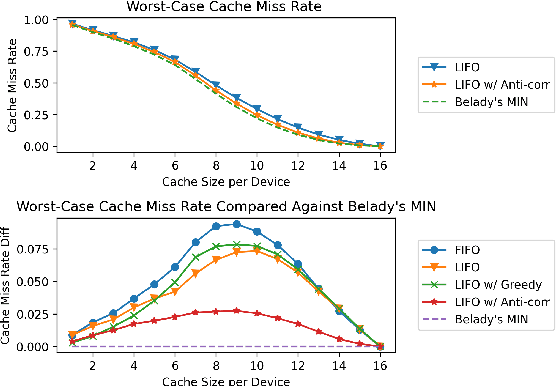
Mixture-of-Experts (MoE) models have recently gained steam in achieving the state-of-the-art performance in a wide range of tasks in computer vision and natural language processing. They effectively expand the model capacity while incurring a minimal increase in computation cost during training. However, deploying such models for inference is difficult due to their large model size and complex communication pattern. In this work, we provide a characterization of two MoE workloads, namely Language Modeling (LM) and Machine Translation (MT) and identify their sources of inefficiencies at deployment. We propose three optimization techniques to mitigate sources of inefficiencies, namely (1) Dynamic gating, (2) Expert Buffering, and (3) Expert load balancing. We show that dynamic gating improves execution time by 1.25-4$\times$ for LM, 2-5$\times$ for MT Encoder and 1.09-1.5$\times$ for MT Decoder. It also reduces memory usage by up to 1.36$\times$ for LM and up to 1.1$\times$ for MT. We further propose Expert Buffering, a new caching mechanism that only keeps hot, active experts in GPU memory while buffering the rest in CPU memory. This reduces static memory allocation by 1.47$\times$. We finally propose a load balancing methodology that provides additional robustness to the workload. The code will be open-sourced upon acceptance.
MP-Rec: Hardware-Software Co-Design to Enable Multi-Path Recommendation
Feb 21, 2023


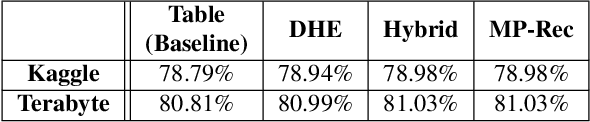
Deep learning recommendation systems serve personalized content under diverse tail-latency targets and input-query loads. In order to do so, state-of-the-art recommendation models rely on terabyte-scale embedding tables to learn user preferences over large bodies of contents. The reliance on a fixed embedding representation of embedding tables not only imposes significant memory capacity and bandwidth requirements but also limits the scope of compatible system solutions. This paper challenges the assumption of fixed embedding representations by showing how synergies between embedding representations and hardware platforms can lead to improvements in both algorithmic- and system performance. Based on our characterization of various embedding representations, we propose a hybrid embedding representation that achieves higher quality embeddings at the cost of increased memory and compute requirements. To address the system performance challenges of the hybrid representation, we propose MP-Rec -- a co-design technique that exploits heterogeneity and dynamic selection of embedding representations and underlying hardware platforms. On real system hardware, we demonstrate how matching custom accelerators, i.e., GPUs, TPUs, and IPUs, with compatible embedding representations can lead to 16.65x performance speedup. Additionally, in query-serving scenarios, MP-Rec achieves 2.49x and 3.76x higher correct prediction throughput and 0.19% and 0.22% better model quality on a CPU-GPU system for the Kaggle and Terabyte datasets, respectively.