 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
Understanding Scaling Laws for Recommendation Models
Aug 17, 2022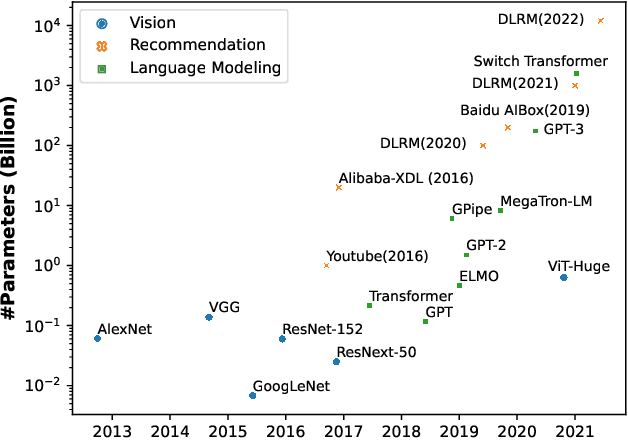

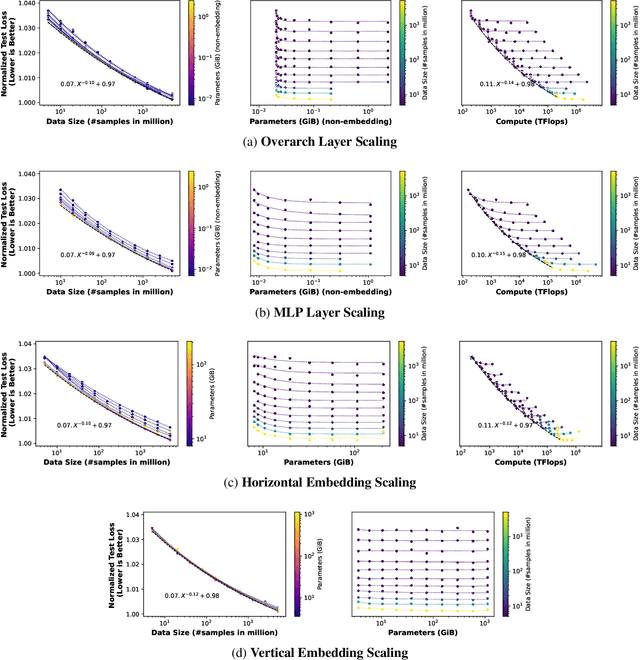
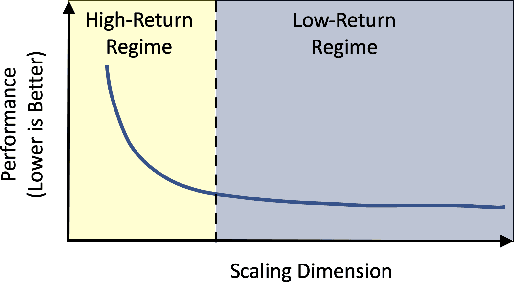
Scale has been a major driving force in improving machine learning performance, and understanding scaling laws is essential for strategic planning for a sustainable model quality performance growth, long-term resource planning and developing efficient system infrastructures to support large-scale models. In this paper, we study empirical scaling laws for DLRM style recommendation models, in particular Click-Through Rate (CTR). We observe that model quality scales with power law plus constant in model size, data size and amount of compute used for training. We characterize scaling efficiency along three different resource dimensions, namely data, parameters and compute by comparing the different scaling schemes along these axes. We show that parameter scaling is out of steam for the model architecture under study, and until a higher-performing model architecture emerges, data scaling is the path forward. The key research questions addressed by this study include: Does a recommendation model scale sustainably as predicted by the scaling laws? Or are we far off from the scaling law predictions? What are the limits of scaling? What are the implications of the scaling laws on long-term hardware/system development?
DHEN: A Deep and Hierarchical Ensemble Network for Large-Scale Click-Through Rate Prediction
Mar 11, 2022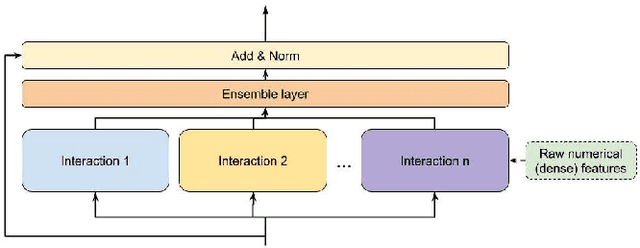
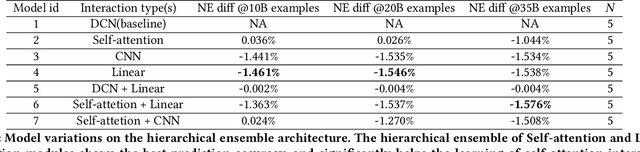
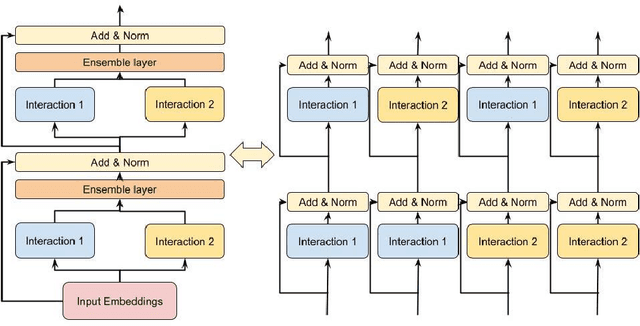

Learning feature interactions is important to the model performance of online advertising services. As a result, extensive efforts have been devoted to designing effective architectures to learn feature interactions. However, we observe that the practical performance of those designs can vary from dataset to dataset, even when the order of interactions claimed to be captured is the same. That indicates different designs may have different advantages and the interactions captured by them have non-overlapping information. Motivated by this observation, we propose DHEN - a deep and hierarchical ensemble architecture that can leverage strengths of heterogeneous interaction modules and learn a hierarchy of the interactions under different orders. To overcome the challenge brought by DHEN's deeper and multi-layer structure in training, we propose a novel co-designed training system that can further improve the training efficiency of DHEN. Experiments of DHEN on large-scale dataset from CTR prediction tasks attained 0.27\% improvement on the Normalized Entropy (NE) of prediction and 1.2x better training throughput than state-of-the-art baseline, demonstrating their effectiveness in practice.
Adaptive Dense-to-Sparse Paradigm for Pruning Online Recommendation System with Non-Stationary Data
Oct 21, 2020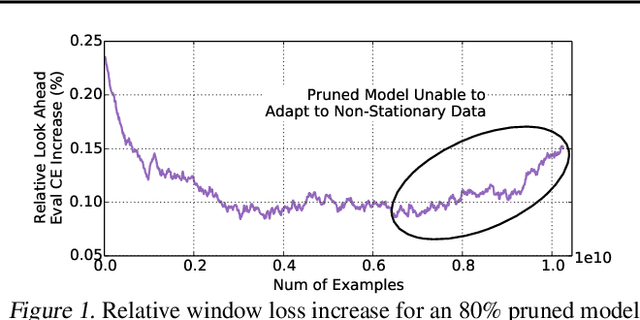
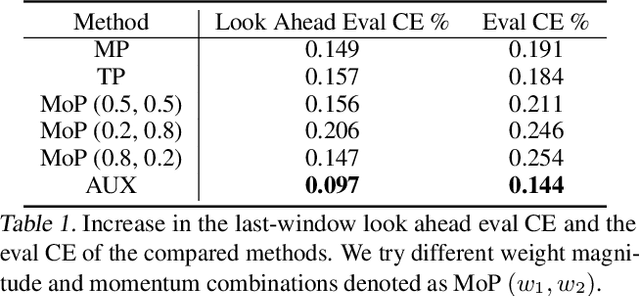
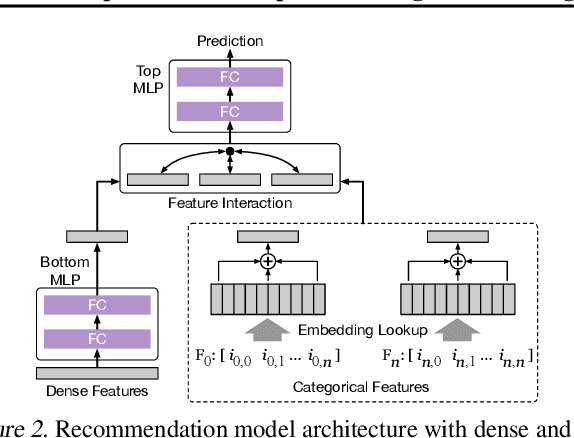
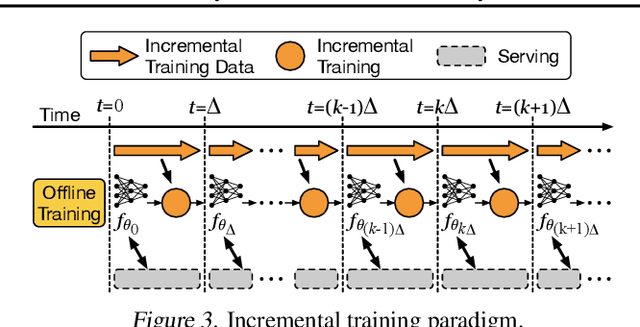
Large scale deep learning provides a tremendous opportunity to improve the quality of content recommendation systems by employing both wider and deeper models, but this comes at great infrastructural cost and carbon footprint in modern data centers. Pruning is an effective technique that reduces both memory and compute demand for model inference. However, pruning for online recommendation systems is challenging due to the continuous data distribution shift (a.k.a non-stationary data). Although incremental training on the full model is able to adapt to the non-stationary data, directly applying it on the pruned model leads to accuracy loss. This is because the sparsity pattern after pruning requires adjustment to learn new patterns. To the best of our knowledge, this is the first work to provide in-depth analysis and discussion of applying pruning to online recommendation systems with non-stationary data distribution. Overall, this work makes the following contributions: 1) We present an adaptive dense to sparse paradigm equipped with a novel pruning algorithm for pruning a large scale recommendation system with non-stationary data distribution; 2) We design the pruning algorithm to automatically learn the sparsity across layers to avoid repeating hand-tuning, which is critical for pruning the heterogeneous architectures of recommendation systems trained with non-stationary data.