 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTorchBench: Benchmarking PyTorch with High API Surface Coverage
Apr 28, 2023Deep learning (DL) has been a revolutionary technique in various domains. To facilitate the model development and deployment, many deep learning frameworks are proposed, among which PyTorch is one of the most popular solutions. The performance of ecosystem around PyTorch is critically important, which saves the costs of training models and reduces the response time of model inferences. In this paper, we propose TorchBench, a novel benchmark suite to study the performance of PyTorch software stack. Unlike existing benchmark suites, TorchBench encloses many representative models, covering a large PyTorch API surface. TorchBench is able to comprehensively characterize the performance of the PyTorch software stack, guiding the performance optimization across models, PyTorch framework, and GPU libraries. We show two practical use cases of TorchBench. (1) We profile TorchBench to identify GPU performance inefficiencies in PyTorch. We are able to optimize many performance bugs and upstream patches to the official PyTorch repository. (2) We integrate TorchBench into PyTorch continuous integration system. We are able to identify performance regression in multiple daily code checkins to prevent PyTorch repository from introducing performance bugs. TorchBench is open source and keeps evolving.
Understanding Scaling Laws for Recommendation Models
Aug 17, 2022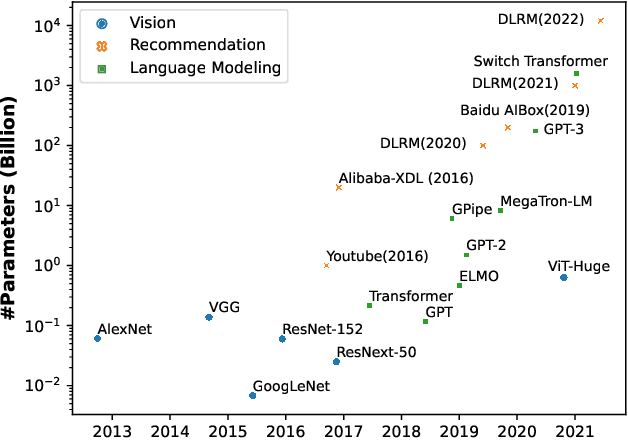

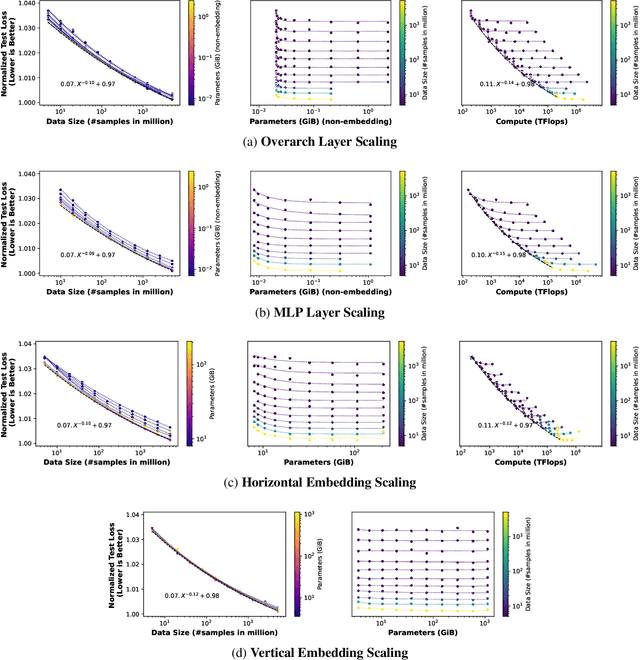
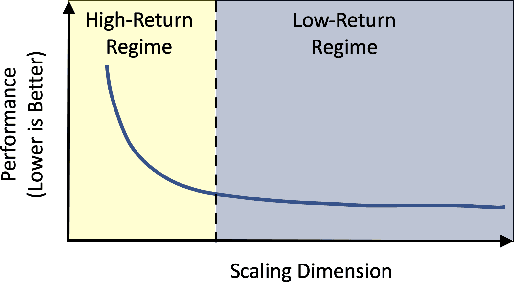
Scale has been a major driving force in improving machine learning performance, and understanding scaling laws is essential for strategic planning for a sustainable model quality performance growth, long-term resource planning and developing efficient system infrastructures to support large-scale models. In this paper, we study empirical scaling laws for DLRM style recommendation models, in particular Click-Through Rate (CTR). We observe that model quality scales with power law plus constant in model size, data size and amount of compute used for training. We characterize scaling efficiency along three different resource dimensions, namely data, parameters and compute by comparing the different scaling schemes along these axes. We show that parameter scaling is out of steam for the model architecture under study, and until a higher-performing model architecture emerges, data scaling is the path forward. The key research questions addressed by this study include: Does a recommendation model scale sustainably as predicted by the scaling laws? Or are we far off from the scaling law predictions? What are the limits of scaling? What are the implications of the scaling laws on long-term hardware/system development?