 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape-morphing programming of soft materials on complex geometries via neural operator
Jan 16, 2026Shape-morphing soft materials can enable diverse target morphologies through voxel-level material distribution design, offering significant potential for various applications. Despite progress in basic shape-morphing design with simple geometries, achieving advanced applications such as conformal implant deployment or aerodynamic morphing requires accurate and diverse morphing designs on complex geometries, which remains challenging. Here, we present a Spectral and Spatial Neural Operator (S2NO), which enables high-fidelity morphing prediction on complex geometries. S2NO effectively captures global and local morphing behaviours on irregular computational domains by integrating Laplacian eigenfunction encoding and spatial convolutions. Combining S2NO with evolutionary algorithms enables voxel-level optimisation of material distributions for shape morphing programming on various complex geometries, including irregular-boundary shapes, porous structures, and thin-walled structures. Furthermore, the neural operator's discretisation-invariant property enables super-resolution material distribution design, further expanding the diversity and complexity of morphing design. These advancements significantly improve the efficiency and capability of programming complex shape morphing.
Meta-Backscatter: Long-Distance Battery-Free Metamaterial-Backscatter Sensing and Communication
Jan 13, 2026Battery-free Internet of Things (BF-IoT) enabled by backscatter communication is a rapidly evolving technology offering advantages of low cost, ultra-low power consumption, and robustness. However, the practical deployment of BF-IoT is significantly constrained by the limited communication range of common backscatter tags, which typically operate with a range of merely a few meters due to inherent round-trip path loss. Meta-backscatter systems that utilize metamaterial tags present a promising solution, retaining the inherent advantages of BF-IoT while breaking the critical communication range barrier. By leveraging densely paved sub-wavelength units to concentrate the reflected signal power, metamaterial tags enable a significant communication range extension over existing BF-IoT tags that employ omni-directional antennas. In this paper, we synthesize the principles and paradigms of metamaterial sensing to establish a unified design framework and a forward-looking research roadmap. Specifically, we first provide an overview of backscatter communication, encompassing its development history, working principles, and tag classification. We then introduce the design methodology for both metamaterial tags and their compatible transceivers. Moreover, we present the implementation of a meta-backscatter system prototype and report the experimental results based on it. Finally, we conclude by highlighting key challenges and outlining potential avenues for future research.
Learning Geometric Invariance for Gait Recognition
Jan 09, 2026The goal of gait recognition is to extract identity-invariant features of an individual under various gait conditions, e.g., cross-view and cross-clothing. Most gait models strive to implicitly learn the common traits across different gait conditions in a data-driven manner to pull different gait conditions closer for recognition. However, relatively few studies have explicitly explored the inherent relations between different gait conditions. For this purpose, we attempt to establish connections among different gait conditions and propose a new perspective to achieve gait recognition: variations in different gait conditions can be approximately viewed as a combination of geometric transformations. In this case, all we need is to determine the types of geometric transformations and achieve geometric invariance, then identity invariance naturally follows. As an initial attempt, we explore three common geometric transformations (i.e., Reflect, Rotate, and Scale) and design a $\mathcal{R}$eflect-$\mathcal{R}$otate-$\mathcal{S}$cale invariance learning framework, named ${\mathcal{RRS}}$-Gait. Specifically, it first flexibly adjusts the convolution kernel based on the specific geometric transformations to achieve approximate feature equivariance. Then these three equivariant-aware features are respectively fed into a global pooling operation for final invariance-aware learning. Extensive experiments on four popular gait datasets (Gait3D, GREW, CCPG, SUSTech1K) show superior performance across various gait conditions.
IndoorUAV: Benchmarking Vision-Language UAV Navigation in Continuous Indoor Environments
Dec 22, 2025Vision-Language Navigation (VLN) enables agents to navigate in complex environments by following natural language instructions grounded in visual observations. Although most existing work has focused on ground-based robots or outdoor Unmanned Aerial Vehicles (UAVs), indoor UAV-based VLN remains underexplored, despite its relevance to real-world applications such as inspection, delivery, and search-and-rescue in confined spaces. To bridge this gap, we introduce \textbf{IndoorUAV}, a novel benchmark and method specifically tailored for VLN with indoor UAVs. We begin by curating over 1,000 diverse and structurally rich 3D indoor scenes from the Habitat simulator. Within these environments, we simulate realistic UAV flight dynamics to collect diverse 3D navigation trajectories manually, further enriched through data augmentation techniques. Furthermore, we design an automated annotation pipeline to generate natural language instructions of varying granularity for each trajectory. This process yields over 16,000 high-quality trajectories, comprising the \textbf{IndoorUAV-VLN} subset, which focuses on long-horizon VLN. To support short-horizon planning, we segment long trajectories into sub-trajectories by selecting semantically salient keyframes and regenerating concise instructions, forming the \textbf{IndoorUAV-VLA} subset. Finally, we introduce \textbf{IndoorUAV-Agent}, a novel navigation model designed for our benchmark, leveraging task decomposition and multimodal reasoning. We hope IndoorUAV serves as a valuable resource to advance research on vision-language embodied AI in the indoor aerial navigation domain.
Semantic-Metric Bayesian Risk Fields: Learning Robot Safety from Human Videos with a VLM Prior
Dec 09, 2025Humans interpret safety not as a binary signal but as a continuous, context- and spatially-dependent notion of risk. While risk is subjective, humans form rational mental models that guide action selection in dynamic environments. This work proposes a framework for extracting implicit human risk models by introducing a novel, semantically-conditioned and spatially-varying parametrization of risk, supervised directly from safe human demonstration videos and VLM common sense. Notably, we define risk through a Bayesian formulation. The prior is furnished by a pretrained vision-language model. In order to encourage the risk estimate to be more human aligned, a likelihood function modulates the prior to produce a relative metric of risk. Specifically, the likelihood is a learned ViT that maps pretrained features, to pixel-aligned risk values. Our pipeline ingests RGB images and a query object string, producing pixel-dense risk images. These images that can then be used as value-predictors in robot planning tasks or be projected into 3D for use in conventional trajectory optimization to produce human-like motion. This learned mapping enables generalization to novel objects and contexts, and has the potential to scale to much larger training datasets. In particular, the Bayesian framework that is introduced enables fast adaptation of our model to additional observations or common sense rules. We demonstrate that our proposed framework produces contextual risk that aligns with human preferences. Additionally, we illustrate several downstream applications of the model; as a value learner for visuomotor planners or in conjunction with a classical trajectory optimization algorithm. Our results suggest that our framework is a significant step toward enabling autonomous systems to internalize human-like risk. Code and results can be found at https://riskbayesian.github.io/bayesian_risk/.
A Closer Look at Knowledge Distillation in Spiking Neural Network Training
Nov 14, 2025Spiking Neural Networks (SNNs) become popular due to excellent energy efficiency, yet facing challenges for effective model training. Recent works improve this by introducing knowledge distillation (KD) techniques, with the pre-trained artificial neural networks (ANNs) used as teachers and the target SNNs as students. This is commonly accomplished through a straightforward element-wise alignment of intermediate features and prediction logits from ANNs and SNNs, often neglecting the intrinsic differences between their architectures. Specifically, ANN's outputs exhibit a continuous distribution, whereas SNN's outputs are characterized by sparsity and discreteness. To mitigate this issue, we introduce two innovative KD strategies. Firstly, we propose the Saliency-scaled Activation Map Distillation (SAMD), which aligns the spike activation map of the student SNN with the class-aware activation map of the teacher ANN. Rather than performing KD directly on the raw %and distinct features of ANN and SNN, our SAMD directs the student to learn from saliency activation maps that exhibit greater semantic and distribution consistency. Additionally, we propose a Noise-smoothed Logits Distillation (NLD), which utilizes Gaussian noise to smooth the sparse logits of student SNN, facilitating the alignment with continuous logits from teacher ANN. Extensive experiments on multiple datasets demonstrate the effectiveness of our methods. Code is available~\footnote{https://github.com/SinoLeu/CKDSNN.git}.
Moirai 2.0: When Less Is More for Time Series Forecasting
Nov 12, 2025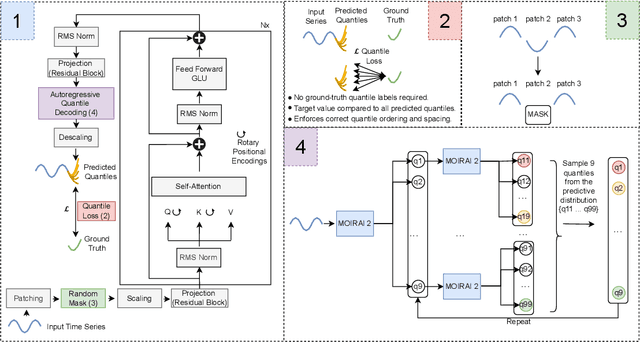
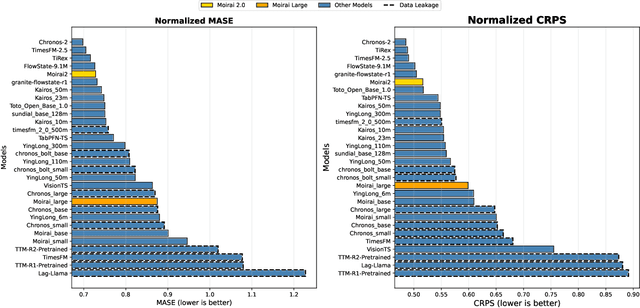

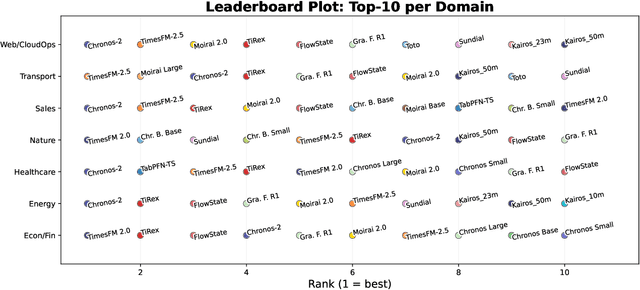
We introduce Moirai 2.0, a decoder-only time-series foundation model trained on a new corpus of 36M series. The model adopts quantile forecasting and multi-token prediction, improving both probabilistic accuracy and inference efficiency. On the Gift-Eval benchmark, it ranks among the top pretrained models while achieving a strong trade-off between accuracy, speed, and model size. Compared to Moirai 1.0, Moirai 2.0 replaces masked-encoder training, multi-patch inputs, and mixture-distribution outputs with a simpler decoder-only architecture, single patch, and quantile loss. Ablation studies isolate these changes -- showing that the decoder-only backbone along with recursive multi-quantile decoding contribute most to the gains. Additional experiments show that Moirai 2.0 outperforms larger models from the same family and exhibits robust domain-level results. In terms of efficiency and model size, Moirai 2.0 is twice as fast and thirty times smaller than its prior best version, Moirai 1.0-Large, while also performing better. Model performance plateaus with increasing parameter count and declines at longer horizons, motivating future work on data scaling and long-horizon modeling. We release code and evaluation details to support further research.
Dynamic Residual Encoding with Slide-Level Contrastive Learning for End-to-End Whole Slide Image Representation
Nov 07, 2025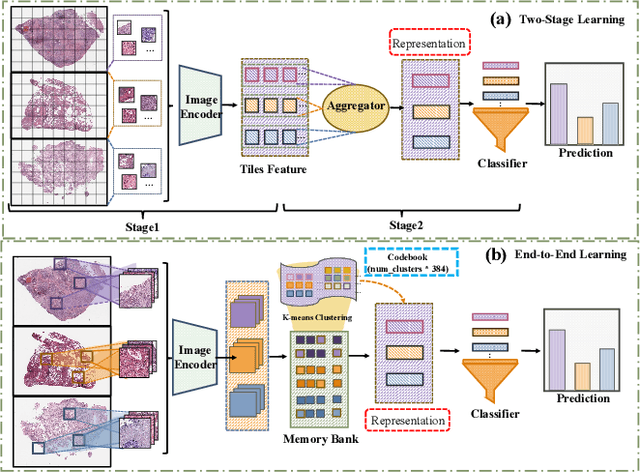

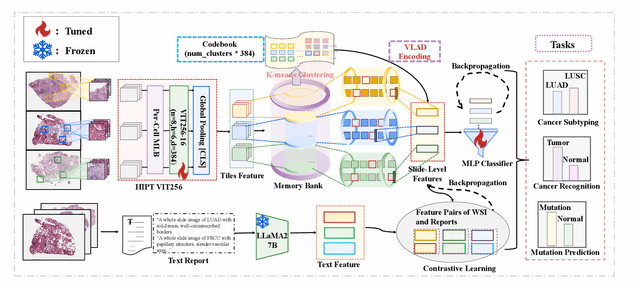
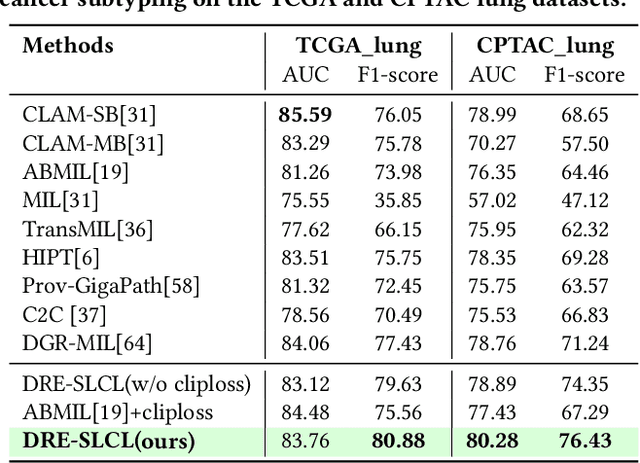
Whole Slide Image (WSI) representation is critical for cancer subtyping, cancer recognition and mutation prediction.Training an end-to-end WSI representation model poses significant challenges, as a standard gigapixel slide can contain tens of thousands of image tiles, making it difficult to compute gradients of all tiles in a single mini-batch due to current GPU limitations. To address this challenge, we propose a method of dynamic residual encoding with slide-level contrastive learning (DRE-SLCL) for end-to-end WSI representation. Our approach utilizes a memory bank to store the features of tiles across all WSIs in the dataset. During training, a mini-batch usually contains multiple WSIs. For each WSI in the batch, a subset of tiles is randomly sampled and their features are computed using a tile encoder. Then, additional tile features from the same WSI are selected from the memory bank. The representation of each individual WSI is generated using a residual encoding technique that incorporates both the sampled features and those retrieved from the memory bank. Finally, the slide-level contrastive loss is computed based on the representations and histopathology reports ofthe WSIs within the mini-batch. Experiments conducted over cancer subtyping, cancer recognition, and mutation prediction tasks proved the effectiveness of the proposed DRE-SLCL method.
* 8pages, 3figures, published to ACM Digital Library
FlowNet: Modeling Dynamic Spatio-Temporal Systems via Flow Propagation
Nov 05, 2025Accurately modeling complex dynamic spatio-temporal systems requires capturing flow-mediated interdependencies and context-sensitive interaction dynamics. Existing methods, predominantly graph-based or attention-driven, rely on similarity-driven connectivity assumptions, neglecting asymmetric flow exchanges that govern system evolution. We propose Spatio-Temporal Flow, a physics-inspired paradigm that explicitly models dynamic node couplings through quantifiable flow transfers governed by conservation principles. Building on this, we design FlowNet, a novel architecture leveraging flow tokens as information carriers to simulate source-to-destination transfers via Flow Allocation Modules, ensuring state redistribution aligns with conservation laws. FlowNet dynamically adjusts the interaction radius through an Adaptive Spatial Masking module, suppressing irrelevant noise while enabling context-aware propagation. A cascaded architecture enhances scalability and nonlinear representation capacity. Experiments demonstrate that FlowNet significantly outperforms existing state-of-the-art approaches on seven metrics in the modeling of three real-world systems, validating its efficiency and physical interpretability. We establish a principled methodology for modeling complex systems through spatio-temporal flow interactions.
Foresight in Motion: Reinforcing Trajectory Prediction with Reward Heuristics
Jul 16, 2025



Motion forecasting for on-road traffic agents presents both a significant challenge and a critical necessity for ensuring safety in autonomous driving systems. In contrast to most existing data-driven approaches that directly predict future trajectories, we rethink this task from a planning perspective, advocating a "First Reasoning, Then Forecasting" strategy that explicitly incorporates behavior intentions as spatial guidance for trajectory prediction. To achieve this, we introduce an interpretable, reward-driven intention reasoner grounded in a novel query-centric Inverse Reinforcement Learning (IRL) scheme. Our method first encodes traffic agents and scene elements into a unified vectorized representation, then aggregates contextual features through a query-centric paradigm. This enables the derivation of a reward distribution, a compact yet informative representation of the target agent's behavior within the given scene context via IRL. Guided by this reward heuristic, we perform policy rollouts to reason about multiple plausible intentions, providing valuable priors for subsequent trajectory generation. Finally, we develop a hierarchical DETR-like decoder integrated with bidirectional selective state space models to produce accurate future trajectories along with their associated probabilities. Extensive experiments on the large-scale Argoverse and nuScenes motion forecasting datasets demonstrate that our approach significantly enhances trajectory prediction confidence, achieving highly competitive performance relative to state-of-the-art methods.