 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Investigation on Deep Learning-Based Omnidirectional Image and Video Super-Resolution
Jun 07, 2025Omnidirectional image and video super-resolution is a crucial research topic in low-level vision, playing an essential role in virtual reality and augmented reality applications. Its goal is to reconstruct high-resolution images or video frames from low-resolution inputs, thereby enhancing detail preservation and enabling more accurate scene analysis and interpretation. In recent years, numerous innovative and effective approaches have been proposed, predominantly based on deep learning techniques, involving diverse network architectures, loss functions, projection strategies, and training datasets. This paper presents a systematic review of recent progress in omnidirectional image and video super-resolution, focusing on deep learning-based methods. Given that existing datasets predominantly rely on synthetic degradation and fall short in capturing real-world distortions, we introduce a new dataset, 360Insta, that comprises authentically degraded omnidirectional images and videos collected under diverse conditions, including varying lighting, motion, and exposure settings. This dataset addresses a critical gap in current omnidirectional benchmarks and enables more robust evaluation of the generalization capabilities of omnidirectional super-resolution methods. We conduct comprehensive qualitative and quantitative evaluations of existing methods on both public datasets and our proposed dataset. Furthermore, we provide a systematic overview of the current status of research and discuss promising directions for future exploration. All datasets, methods, and evaluation metrics introduced in this work are publicly available and will be regularly updated. Project page: https://github.com/nqian1/Survey-on-ODISR-and-ODVSR.
PVUW 2025 Challenge Report: Advances in Pixel-level Understanding of Complex Videos in the Wild
Apr 15, 2025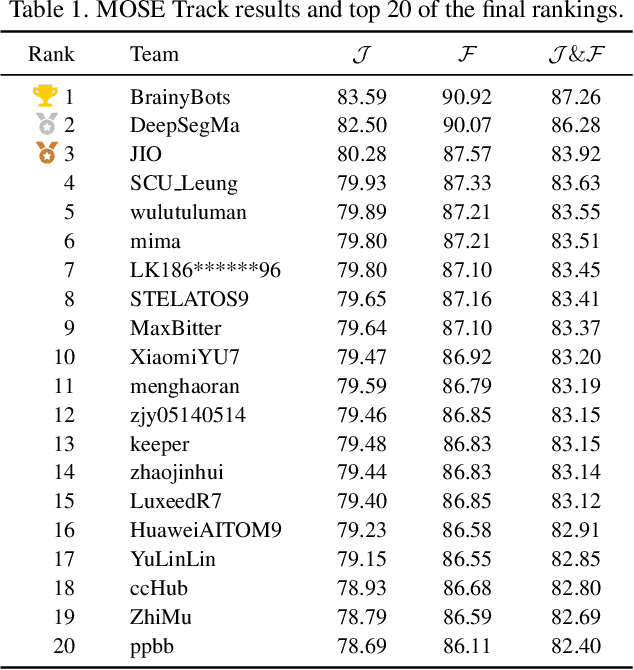
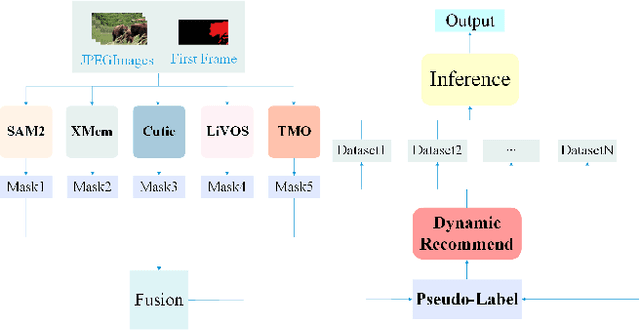
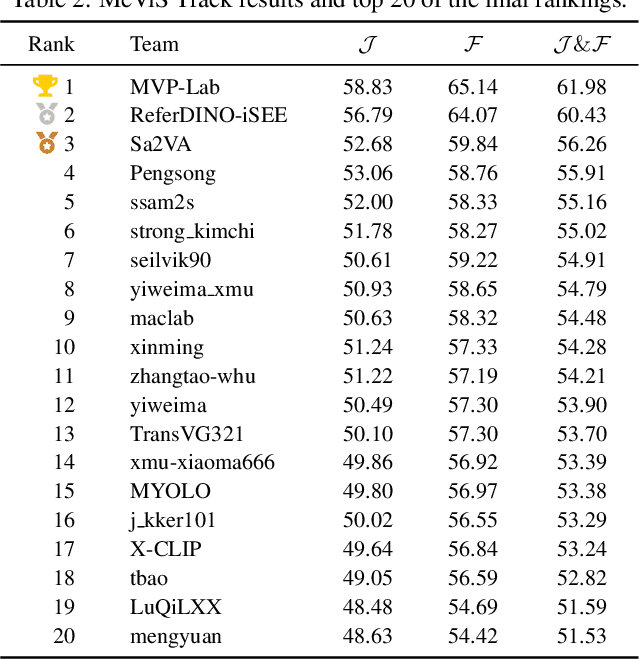
This report provides a comprehensive overview of the 4th Pixel-level Video Understanding in the Wild (PVUW) Challenge, held in conjunction with CVPR 2025. It summarizes the challenge outcomes, participating methodologies, and future research directions. The challenge features two tracks: MOSE, which focuses on complex scene video object segmentation, and MeViS, which targets motion-guided, language-based video segmentation. Both tracks introduce new, more challenging datasets designed to better reflect real-world scenarios. Through detailed evaluation and analysis, the challenge offers valuable insights into the current state-of-the-art and emerging trends in complex video segmentation. More information can be found on the workshop website: https://pvuw.github.io/.
FVOS for MOSE Track of 4th PVUW Challenge: 3rd Place Solution
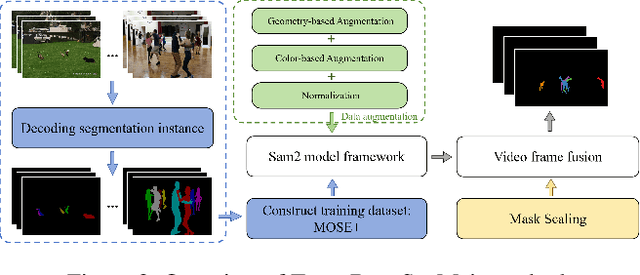
Apr 13, 2025Video Object Segmentation (VOS) is one of the most fundamental and challenging tasks in computer vision and has a wide range of applications. Most existing methods rely on spatiotemporal memory networks to extract frame-level features and have achieved promising results on commonly used datasets. However, these methods often struggle in more complex real-world scenarios. This paper addresses this issue, aiming to achieve accurate segmentation of video objects in challenging scenes. We propose fine-tuning VOS (FVOS), optimizing existing methods for specific datasets through tailored training. Additionally, we introduce a morphological post-processing strategy to address the issue of excessively large gaps between adjacent objects in single-model predictions. Finally, we apply a voting-based fusion method on multi-scale segmentation results to generate the final output. Our approach achieves J&F scores of 76.81% and 83.92% during the validation and testing stages, respectively, securing third place overall in the MOSE Track of the 4th PVUW challenge 2025.
LSVOS Challenge Report: Large-scale Complex and Long Video Object Segmentation
Sep 09, 2024



Despite the promising performance of current video segmentation models on existing benchmarks, these models still struggle with complex scenes. In this paper, we introduce the 6th Large-scale Video Object Segmentation (LSVOS) challenge in conjunction with ECCV 2024 workshop. This year's challenge includes two tasks: Video Object Segmentation (VOS) and Referring Video Object Segmentation (RVOS). In this year, we replace the classic YouTube-VOS and YouTube-RVOS benchmark with latest datasets MOSE, LVOS, and MeViS to assess VOS under more challenging complex environments. This year's challenge attracted 129 registered teams from more than 20 institutes across over 8 countries. This report include the challenge and dataset introduction, and the methods used by top 7 teams in two tracks. More details can be found in our homepage https://lsvos.github.io/.
CSS-Segment: 2nd Place Report of LSVOS Challenge VOS Track
Aug 24, 2024
Video object segmentation is a challenging task that serves as the cornerstone of numerous downstream applications, including video editing and autonomous driving. In this technical report, we briefly introduce the solution of our team "yuanjie" for video object segmentation in the 6-th LSVOS Challenge VOS Track at ECCV 2024. We believe that our proposed CSS-Segment will perform better in videos of complex object motion and long-term presentation. In this report, we successfully validated the effectiveness of the CSS-Segment in video object segmentation. Finally, our method achieved a J\&F score of 80.84 in and test phases, and ultimately ranked 2nd in the 6-th LSVOS Challenge VOS Track at ECCV 2024.
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
The Robust Semantic Segmentation UNCV2023 Challenge Results
Sep 27, 2023



This paper outlines the winning solutions employed in addressing the MUAD uncertainty quantification challenge held at ICCV 2023. The challenge was centered around semantic segmentation in urban environments, with a particular focus on natural adversarial scenarios. The report presents the results of 19 submitted entries, with numerous techniques drawing inspiration from cutting-edge uncertainty quantification methodologies presented at prominent conferences in the fields of computer vision and machine learning and journals over the past few years. Within this document, the challenge is introduced, shedding light on its purpose and objectives, which primarily revolved around enhancing the robustness of semantic segmentation in urban scenes under varying natural adversarial conditions. The report then delves into the top-performing solutions. Moreover, the document aims to provide a comprehensive overview of the diverse solutions deployed by all participants. By doing so, it seeks to offer readers a deeper insight into the array of strategies that can be leveraged to effectively handle the inherent uncertainties associated with autonomous driving and semantic segmentation, especially within urban environments.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.