 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos-Transfer1: Conditional World Generation with Adaptive Multimodal Control
Mar 18, 2025We introduce Cosmos-Transfer, a conditional world generation model that can generate world simulations based on multiple spatial control inputs of various modalities such as segmentation, depth, and edge. In the design, the spatial conditional scheme is adaptive and customizable. It allows weighting different conditional inputs differently at different spatial locations. This enables highly controllable world generation and finds use in various world-to-world transfer use cases, including Sim2Real. We conduct extensive evaluations to analyze the proposed model and demonstrate its applications for Physical AI, including robotics Sim2Real and autonomous vehicle data enrichment. We further demonstrate an inference scaling strategy to achieve real-time world generation with an NVIDIA GB200 NVL72 rack. To help accelerate research development in the field, we open-source our models and code at https://github.com/nvidia-cosmos/cosmos-transfer1.
Multi-Dimensional Pruning: Joint Channel, Layer and Block Pruning with Latency Constraint
Jun 17, 2024As we push the boundaries of performance in various vision tasks, the models grow in size correspondingly. To keep up with this growth, we need very aggressive pruning techniques for efficient inference and deployment on edge devices. Existing pruning approaches are limited to channel pruning and struggle with aggressive parameter reductions. In this paper, we propose a novel multi-dimensional pruning framework that jointly optimizes pruning across channels, layers, and blocks while adhering to latency constraints. We develop a latency modeling technique that accurately captures model-wide latency variations during pruning, which is crucial for achieving an optimal latency-accuracy trade-offs at high pruning ratio. We reformulate pruning as a Mixed-Integer Nonlinear Program (MINLP) to efficiently determine the optimal pruned structure with only a single pass. Our extensive results demonstrate substantial improvements over previous methods, particularly at large pruning ratios. In classification, our method significantly outperforms prior art HALP with a Top-1 accuracy of 70.0(v.s. 68.6) and an FPS of 5262 im/s(v.s. 4101 im/s). In 3D object detection, we establish a new state-of-the-art by pruning StreamPETR at a 45% pruning ratio, achieving higher FPS (37.3 vs. 31.7) and mAP (0.451 vs. 0.449) than the dense baseline.
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
FocalFormer3D : Focusing on Hard Instance for 3D Object Detection
Aug 08, 2023



False negatives (FN) in 3D object detection, {\em e.g.}, missing predictions of pedestrians, vehicles, or other obstacles, can lead to potentially dangerous situations in autonomous driving. While being fatal, this issue is understudied in many current 3D detection methods. In this work, we propose Hard Instance Probing (HIP), a general pipeline that identifies \textit{FN} in a multi-stage manner and guides the models to focus on excavating difficult instances. For 3D object detection, we instantiate this method as FocalFormer3D, a simple yet effective detector that excels at excavating difficult objects and improving prediction recall. FocalFormer3D features a multi-stage query generation to discover hard objects and a box-level transformer decoder to efficiently distinguish objects from massive object candidates. Experimental results on the nuScenes and Waymo datasets validate the superior performance of FocalFormer3D. The advantage leads to strong performance on both detection and tracking, in both LiDAR and multi-modal settings. Notably, FocalFormer3D achieves a 70.5 mAP and 73.9 NDS on nuScenes detection benchmark, while the nuScenes tracking benchmark shows 72.1 AMOTA, both ranking 1st place on the nuScenes LiDAR leaderboard. Our code is available at \url{https://github.com/NVlabs/FocalFormer3D}.
Adaptive Sharpness-Aware Pruning for Robust Sparse Networks
Jun 25, 2023Robustness and compactness are two essential components of deep learning models that are deployed in the real world. The seemingly conflicting aims of (i) generalization across domains as in robustness, and (ii) specificity to one domain as in compression, are why the overall design goal of achieving robust compact models, despite being highly important, is still a challenging open problem. We introduce Adaptive Sharpness-Aware Pruning, or AdaSAP, a method that yields robust sparse networks. The central tenet of our approach is to optimize the loss landscape so that the model is primed for pruning via adaptive weight perturbation, and is also consistently regularized toward flatter regions for improved robustness. This unifies both goals through the lens of network sharpness. AdaSAP achieves strong performance in a comprehensive set of experiments. For classification on ImageNet and object detection on Pascal VOC datasets, AdaSAP improves the robust accuracy of pruned models by +6% on ImageNet C, +4% on ImageNet V2, and +4% on corrupted VOC datasets, over a wide range of compression ratios, saliency criteria, and network architectures, outperforming recent pruning art by large margins.
AdaViT: Adaptive Tokens for Efficient Vision Transformer
Dec 14, 2021
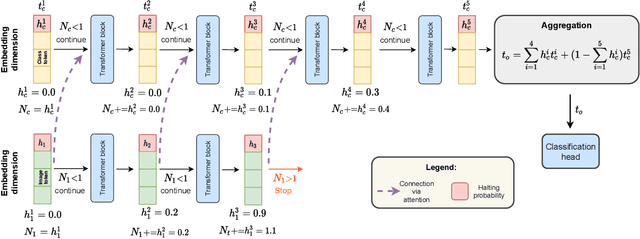
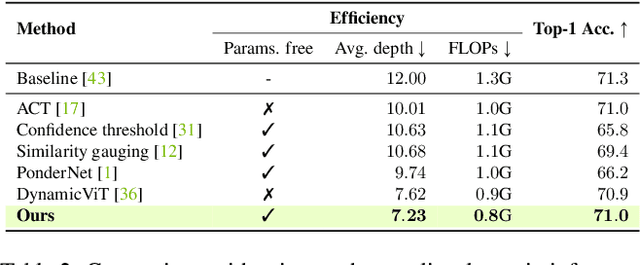

We introduce AdaViT, a method that adaptively adjusts the inference cost of vision transformer (ViT) for images of different complexity. AdaViT achieves this by automatically reducing the number of tokens in vision transformers that are processed in the network as inference proceeds. We reformulate Adaptive Computation Time (ACT) for this task, extending halting to discard redundant spatial tokens. The appealing architectural properties of vision transformers enables our adaptive token reduction mechanism to speed up inference without modifying the network architecture or inference hardware. We demonstrate that AdaViT requires no extra parameters or sub-network for halting, as we base the learning of adaptive halting on the original network parameters. We further introduce distributional prior regularization that stabilizes training compared to prior ACT approaches. On the image classification task (ImageNet1K), we show that our proposed AdaViT yields high efficacy in filtering informative spatial features and cutting down on the overall compute. The proposed method improves the throughput of DeiT-Tiny by 62% and DeiT-Small by 38% with only 0.3% accuracy drop, outperforming prior art by a large margin.
DecomposeMe: Simplifying ConvNets for End-to-End Learning
Jun 17, 2016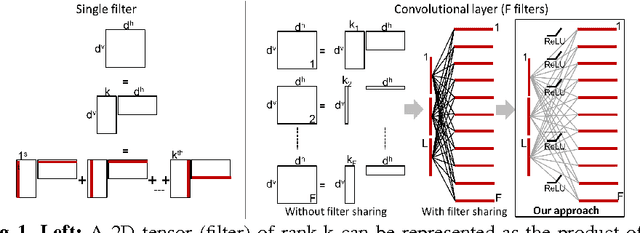
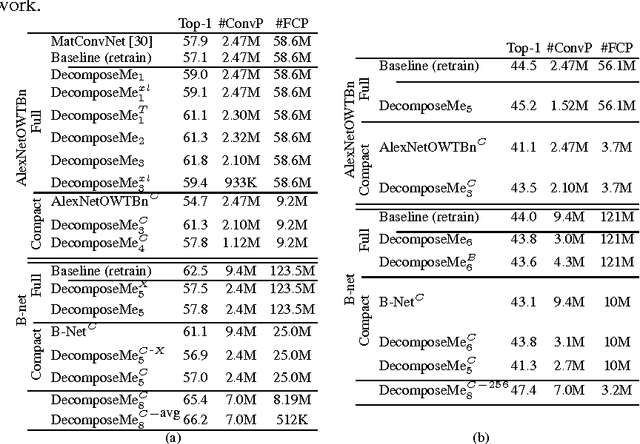
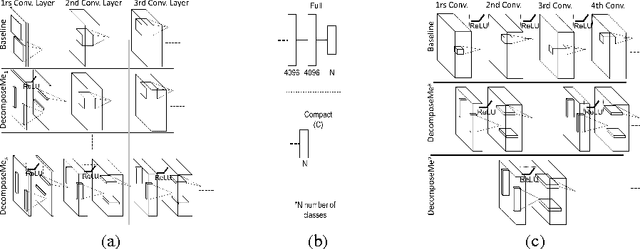

Deep learning and convolutional neural networks (ConvNets) have been successfully applied to most relevant tasks in the computer vision community. However, these networks are computationally demanding and not suitable for embedded devices where memory and time consumption are relevant. In this paper, we propose DecomposeMe, a simple but effective technique to learn features using 1D convolutions. The proposed architecture enables both simplicity and filter sharing leading to increased learning capacity. A comprehensive set of large-scale experiments on ImageNet and Places2 demonstrates the ability of our method to improve performance while significantly reducing the number of parameters required. Notably, on Places2, we obtain an improvement in relative top-1 classification accuracy of 7.7\% with an architecture that requires 92% fewer parameters compared to VGG-B. The proposed network is also demonstrated to generalize to other tasks by converting existing networks.
Motion Estimation via Robust Decomposition with Constrained Rank
Oct 22, 2014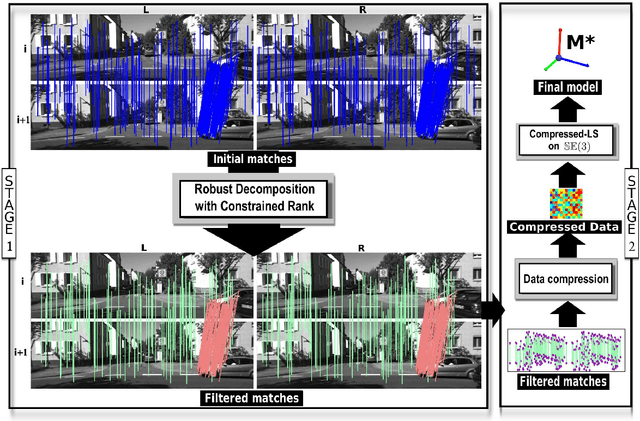

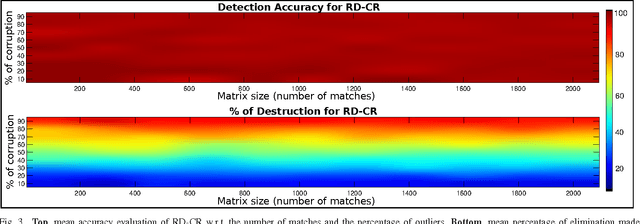
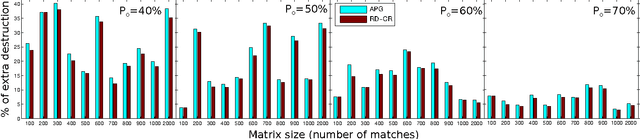
In this work, we address the problem of outlier detection for robust motion estimation by using modern sparse-low-rank decompositions, i.e., Robust PCA-like methods, to impose global rank constraints. Robust decompositions have shown to be good at splitting a corrupted matrix into an uncorrupted low-rank matrix and a sparse matrix, containing outliers. However, this process only works when matrices have relatively low rank with respect to their ambient space, a property not met in motion estimation problems. As a solution, we propose to exploit the partial information present in the decomposition to decide which matches are outliers. We provide evidences showing that even when it is not possible to recover an uncorrupted low-rank matrix, the resulting information can be exploited for outlier detection. To this end we propose the Robust Decomposition with Constrained Rank (RD-CR), a proximal gradient based method that enforces the rank constraints inherent to motion estimation. We also present a general framework to perform robust estimation for stereo Visual Odometry, based on our RD-CR and a simple but effective compressed optimization method that achieves high performance. Our evaluation on synthetic data and on the KITTI dataset demonstrates the applicability of our approach in complex scenarios and it yields state-of-the-art performance.