 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Trajectory Scoring for End-to-end Multimodal Planning
Jun 07, 2025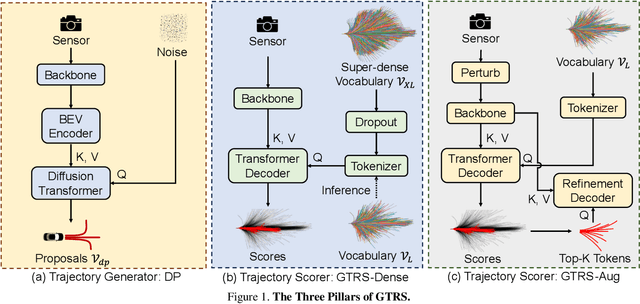

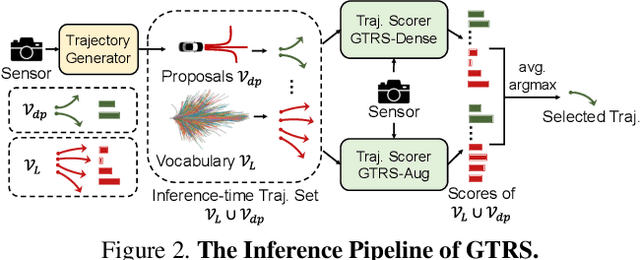
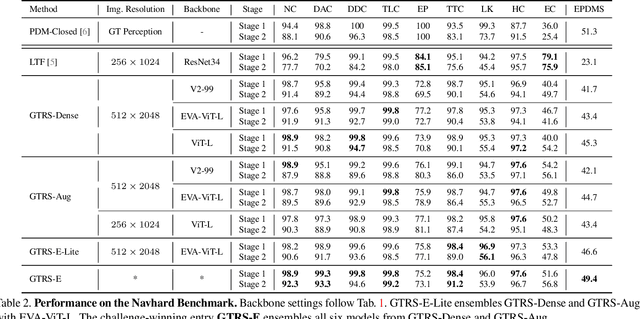
End-to-end multi-modal planning is a promising paradigm in autonomous driving, enabling decision-making with diverse trajectory candidates. A key component is a robust trajectory scorer capable of selecting the optimal trajectory from these candidates. While recent trajectory scorers focus on scoring either large sets of static trajectories or small sets of dynamically generated ones, both approaches face significant limitations in generalization. Static vocabularies provide effective coarse discretization but struggle to make fine-grained adaptation, while dynamic proposals offer detailed precision but fail to capture broader trajectory distributions. To overcome these challenges, we propose GTRS (Generalized Trajectory Scoring), a unified framework for end-to-end multi-modal planning that combines coarse and fine-grained trajectory evaluation. GTRS consists of three complementary innovations: (1) a diffusion-based trajectory generator that produces diverse fine-grained proposals; (2) a vocabulary generalization technique that trains a scorer on super-dense trajectory sets with dropout regularization, enabling its robust inference on smaller subsets; and (3) a sensor augmentation strategy that enhances out-of-domain generalization while incorporating refinement training for critical trajectory discrimination. As the winning solution of the Navsim v2 Challenge, GTRS demonstrates superior performance even with sub-optimal sensor inputs, approaching privileged methods that rely on ground-truth perception. Code will be available at https://github.com/NVlabs/GTRS.
Cosmos-Transfer1: Conditional World Generation with Adaptive Multimodal Control
Mar 18, 2025We introduce Cosmos-Transfer, a conditional world generation model that can generate world simulations based on multiple spatial control inputs of various modalities such as segmentation, depth, and edge. In the design, the spatial conditional scheme is adaptive and customizable. It allows weighting different conditional inputs differently at different spatial locations. This enables highly controllable world generation and finds use in various world-to-world transfer use cases, including Sim2Real. We conduct extensive evaluations to analyze the proposed model and demonstrate its applications for Physical AI, including robotics Sim2Real and autonomous vehicle data enrichment. We further demonstrate an inference scaling strategy to achieve real-time world generation with an NVIDIA GB200 NVL72 rack. To help accelerate research development in the field, we open-source our models and code at https://github.com/nvidia-cosmos/cosmos-transfer1.
LazyDINO: Fast, scalable, and efficiently amortized Bayesian inversion via structure-exploiting and surrogate-driven measure transport
Nov 19, 2024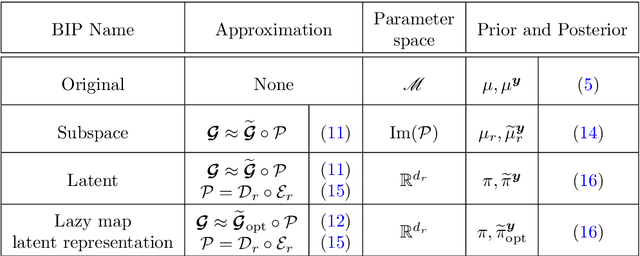
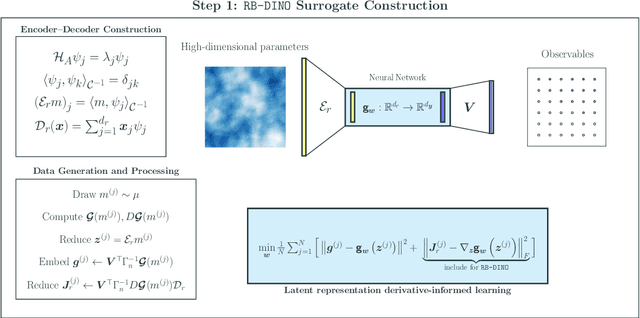
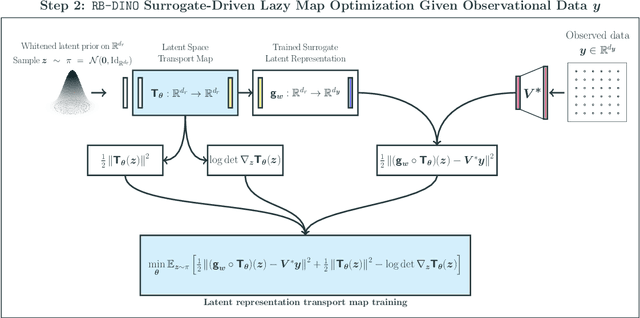
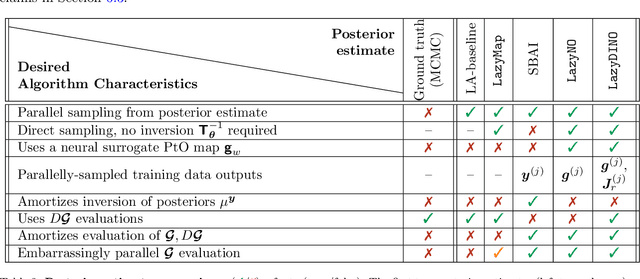
We present LazyDINO, a transport map variational inference method for fast, scalable, and efficiently amortized solutions of high-dimensional nonlinear Bayesian inverse problems with expensive parameter-to-observable (PtO) maps. Our method consists of an offline phase in which we construct a derivative-informed neural surrogate of the PtO map using joint samples of the PtO map and its Jacobian. During the online phase, when given observational data, we seek rapid posterior approximation using surrogate-driven training of a lazy map [Brennan et al., NeurIPS, (2020)], i.e., a structure-exploiting transport map with low-dimensional nonlinearity. The trained lazy map then produces approximate posterior samples or density evaluations. Our surrogate construction is optimized for amortized Bayesian inversion using lazy map variational inference. We show that (i) the derivative-based reduced basis architecture [O'Leary-Roseberry et al., Comput. Methods Appl. Mech. Eng., 388 (2022)] minimizes the upper bound on the expected error in surrogate posterior approximation, and (ii) the derivative-informed training formulation [O'Leary-Roseberry et al., J. Comput. Phys., 496 (2024)] minimizes the expected error due to surrogate-driven transport map optimization. Our numerical results demonstrate that LazyDINO is highly efficient in cost amortization for Bayesian inversion. We observe one to two orders of magnitude reduction of offline cost for accurate posterior approximation, compared to simulation-based amortized inference via conditional transport and conventional surrogate-driven transport. In particular, LazyDINO outperforms Laplace approximation consistently using fewer than 1000 offline samples, while other amortized inference methods struggle and sometimes fail at 16,000 offline samples.
Exploring Camera Encoder Designs for Autonomous Driving Perception
Jul 09, 2024The cornerstone of autonomous vehicles (AV) is a solid perception system, where camera encoders play a crucial role. Existing works usually leverage pre-trained Convolutional Neural Networks (CNN) or Vision Transformers (ViTs) designed for general vision tasks, such as image classification, segmentation, and 2D detection. Although those well-known architectures have achieved state-of-the-art accuracy in AV-related tasks, e.g., 3D Object Detection, there remains significant potential for improvement in network design due to the nuanced complexities of industrial-level AV dataset. Moreover, existing public AV benchmarks usually contain insufficient data, which might lead to inaccurate evaluation of those architectures.To reveal the AV-specific model insights, we start from a standard general-purpose encoder, ConvNeXt and progressively transform the design. We adjust different design parameters including width and depth of the model, stage compute ratio, attention mechanisms, and input resolution, supported by systematic analysis to each modifications. This customization yields an architecture optimized for AV camera encoder achieving 8.79% mAP improvement over the baseline. We believe our effort could become a sweet cookbook of image encoders for AV and pave the way to the next-level drive system.
Bayesian model calibration for block copolymer self-assembly: Likelihood-free inference and expected information gain computation via measure transport
Jun 22, 2022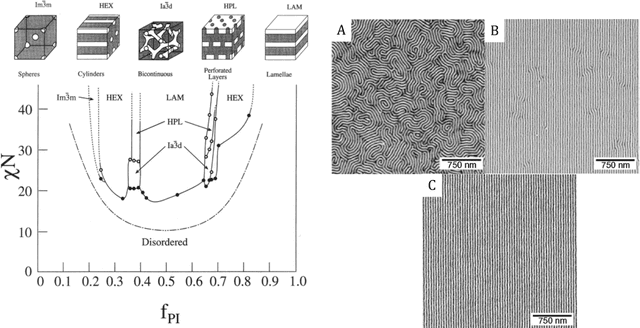
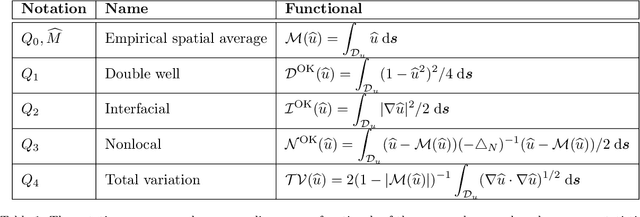
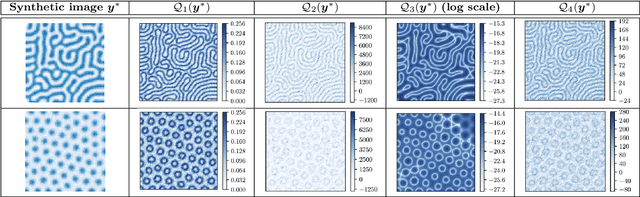
We consider the Bayesian calibration of models describing the phenomenon of block copolymer (BCP) self-assembly using image data produced by microscopy or X-ray scattering techniques. To account for the random long-range disorder in BCP equilibrium structures, we introduce auxiliary variables to represent this aleatory uncertainty. These variables, however, result in an integrated likelihood for high-dimensional image data that is generally intractable to evaluate. We tackle this challenging Bayesian inference problem using a likelihood-free approach based on measure transport together with the construction of summary statistics for the image data. We also show that expected information gains (EIGs) from the observed data about the model parameters can be computed with no significant additional cost. Lastly, we present a numerical case study based on the Ohta--Kawasaki model for diblock copolymer thin film self-assembly and top-down microscopy characterization. For calibration, we introduce several domain-specific energy- and Fourier-based summary statistics, and quantify their informativeness using EIG. We demonstrate the power of the proposed approach to study the effect of data corruptions and experimental designs on the calibration results.
A stochastic Stein Variational Newton method
Apr 19, 2022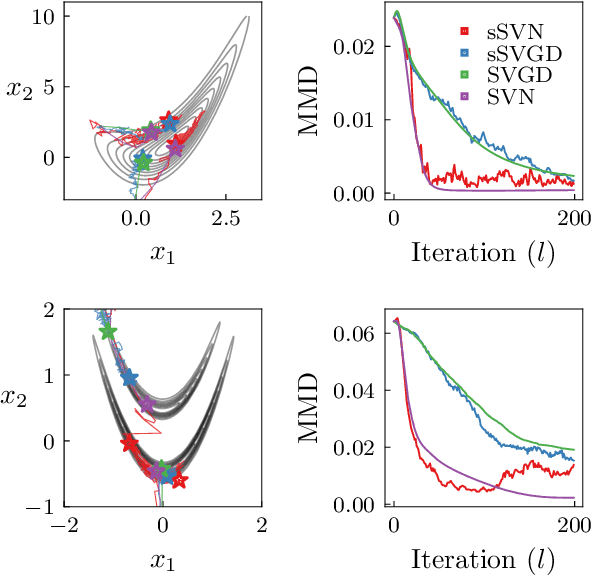
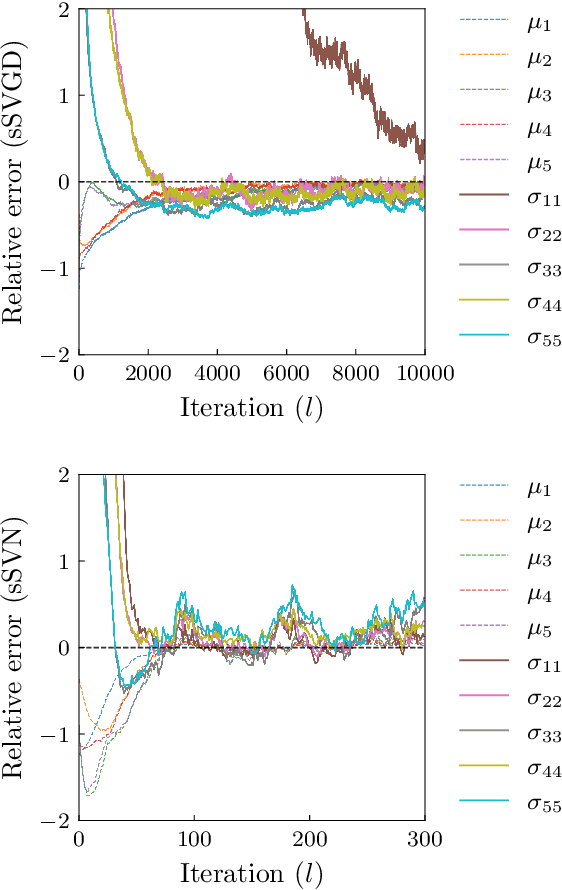
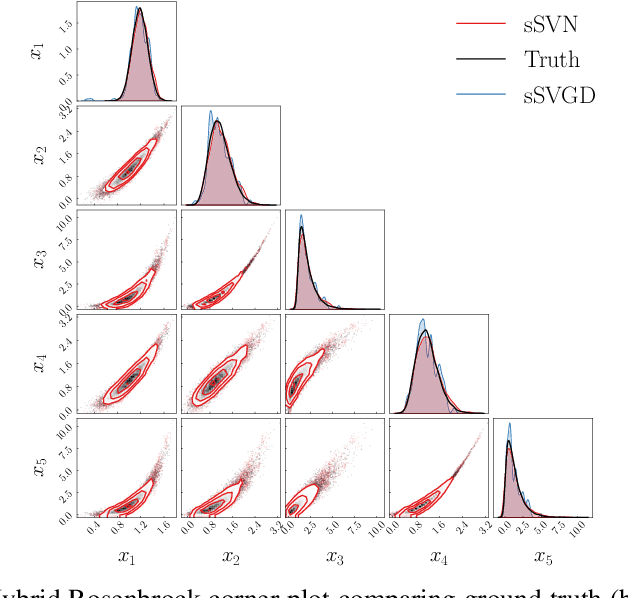
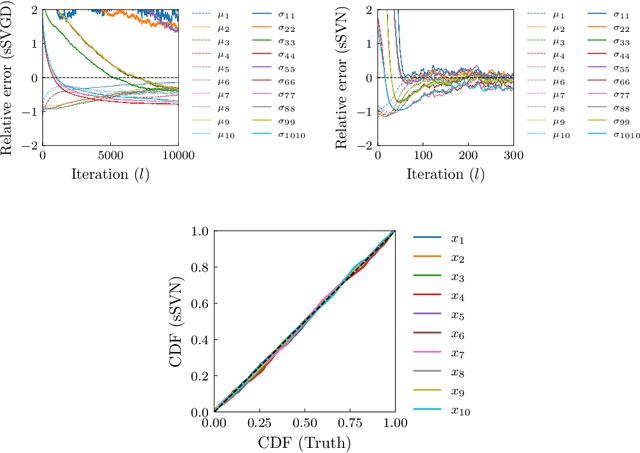
Stein variational gradient descent (SVGD) is a general-purpose optimization-based sampling algorithm that has recently exploded in popularity, but is limited by two issues: it is known to produce biased samples, and it can be slow to converge on complicated distributions. A recently proposed stochastic variant of SVGD (sSVGD) addresses the first issue, producing unbiased samples by incorporating a special noise into the SVGD dynamics such that asymptotic convergence is guaranteed. Meanwhile, Stein variational Newton (SVN), a Newton-like extension of SVGD, dramatically accelerates the convergence of SVGD by incorporating Hessian information into the dynamics, but also produces biased samples. In this paper we derive, and provide a practical implementation of, a stochastic variant of SVN (sSVN) which is both asymptotically correct and converges rapidly. We demonstrate the effectiveness of our algorithm on a difficult class of test problems -- the Hybrid Rosenbrock density -- and show that sSVN converges using three orders of magnitude fewer gradient evaluations of the log likelihood than its stochastic SVGD counterpart. Our results show that sSVN is a promising approach to accelerating high-precision Bayesian inference tasks with modest-dimension, $d\sim\mathcal{O}(10)$.