 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveSuprim: Towards Precise Trajectory Selection for End-to-End Planning
Jun 07, 2025In complex driving environments, autonomous vehicles must navigate safely. Relying on a single predicted path, as in regression-based approaches, usually does not explicitly assess the safety of the predicted trajectory. Selection-based methods address this by generating and scoring multiple trajectory candidates and predicting the safety score for each, but face optimization challenges in precisely selecting the best option from thousands of possibilities and distinguishing subtle but safety-critical differences, especially in rare or underrepresented scenarios. We propose DriveSuprim to overcome these challenges and advance the selection-based paradigm through a coarse-to-fine paradigm for progressive candidate filtering, a rotation-based augmentation method to improve robustness in out-of-distribution scenarios, and a self-distillation framework to stabilize training. DriveSuprim achieves state-of-the-art performance, reaching 93.5% PDMS in NAVSIM v1 and 87.1% EPDMS in NAVSIM v2 without extra data, demonstrating superior safetycritical capabilities, including collision avoidance and compliance with rules, while maintaining high trajectory quality in various driving scenarios.
Generalized Trajectory Scoring for End-to-end Multimodal Planning
Jun 07, 2025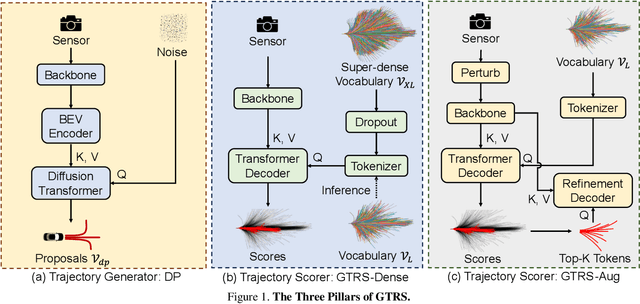

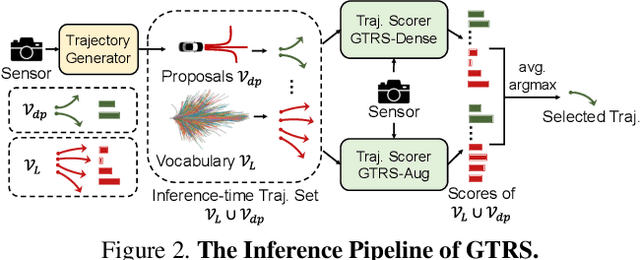
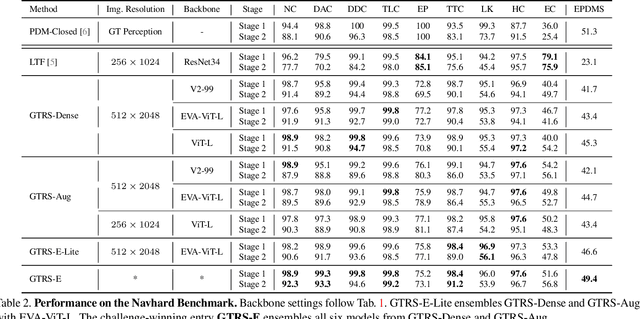
End-to-end multi-modal planning is a promising paradigm in autonomous driving, enabling decision-making with diverse trajectory candidates. A key component is a robust trajectory scorer capable of selecting the optimal trajectory from these candidates. While recent trajectory scorers focus on scoring either large sets of static trajectories or small sets of dynamically generated ones, both approaches face significant limitations in generalization. Static vocabularies provide effective coarse discretization but struggle to make fine-grained adaptation, while dynamic proposals offer detailed precision but fail to capture broader trajectory distributions. To overcome these challenges, we propose GTRS (Generalized Trajectory Scoring), a unified framework for end-to-end multi-modal planning that combines coarse and fine-grained trajectory evaluation. GTRS consists of three complementary innovations: (1) a diffusion-based trajectory generator that produces diverse fine-grained proposals; (2) a vocabulary generalization technique that trains a scorer on super-dense trajectory sets with dropout regularization, enabling its robust inference on smaller subsets; and (3) a sensor augmentation strategy that enhances out-of-domain generalization while incorporating refinement training for critical trajectory discrimination. As the winning solution of the Navsim v2 Challenge, GTRS demonstrates superior performance even with sub-optimal sensor inputs, approaching privileged methods that rely on ground-truth perception. Code will be available at https://github.com/NVlabs/GTRS.
Comprehensive Multi-Modal Prototypes are Simple and Effective Classifiers for Vast-Vocabulary Object Detection
Dec 23, 2024
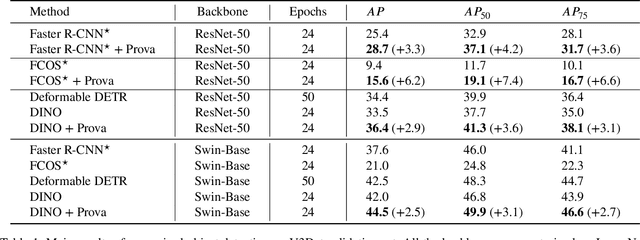
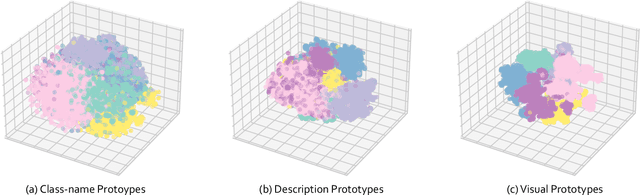

Enabling models to recognize vast open-world categories has been a longstanding pursuit in object detection. By leveraging the generalization capabilities of vision-language models, current open-world detectors can recognize a broader range of vocabularies, despite being trained on limited categories. However, when the scale of the category vocabularies during training expands to a real-world level, previous classifiers aligned with coarse class names significantly reduce the recognition performance of these detectors. In this paper, we introduce Prova, a multi-modal prototype classifier for vast-vocabulary object detection. Prova extracts comprehensive multi-modal prototypes as initialization of alignment classifiers to tackle the vast-vocabulary object recognition failure problem. On V3Det, this simple method greatly enhances the performance among one-stage, two-stage, and DETR-based detectors with only additional projection layers in both supervised and open-vocabulary settings. In particular, Prova improves Faster R-CNN, FCOS, and DINO by 3.3, 6.2, and 2.9 AP respectively in the supervised setting of V3Det. For the open-vocabulary setting, Prova achieves a new state-of-the-art performance with 32.8 base AP and 11.0 novel AP, which is of 2.6 and 4.3 gain over the previous methods.
V3Det Challenge 2024 on Vast Vocabulary and Open Vocabulary Object Detection: Methods and Results
Jun 17, 2024


Detecting objects in real-world scenes is a complex task due to various challenges, including the vast range of object categories, and potential encounters with previously unknown or unseen objects. The challenges necessitate the development of public benchmarks and challenges to advance the field of object detection. Inspired by the success of previous COCO and LVIS Challenges, we organize the V3Det Challenge 2024 in conjunction with the 4th Open World Vision Workshop: Visual Perception via Learning in an Open World (VPLOW) at CVPR 2024, Seattle, US. This challenge aims to push the boundaries of object detection research and encourage innovation in this field. The V3Det Challenge 2024 consists of two tracks: 1) Vast Vocabulary Object Detection: This track focuses on detecting objects from a large set of 13204 categories, testing the detection algorithm's ability to recognize and locate diverse objects. 2) Open Vocabulary Object Detection: This track goes a step further, requiring algorithms to detect objects from an open set of categories, including unknown objects. In the following sections, we will provide a comprehensive summary and analysis of the solutions submitted by participants. By analyzing the methods and solutions presented, we aim to inspire future research directions in vast vocabulary and open-vocabulary object detection, driving progress in this field. Challenge homepage: https://v3det.openxlab.org.cn/challenge