 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Trajectory Scoring for End-to-end Multimodal Planning
Jun 07, 2025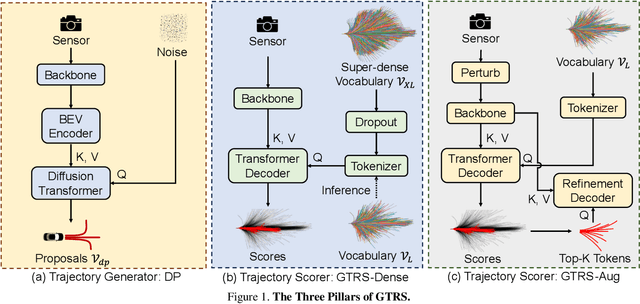

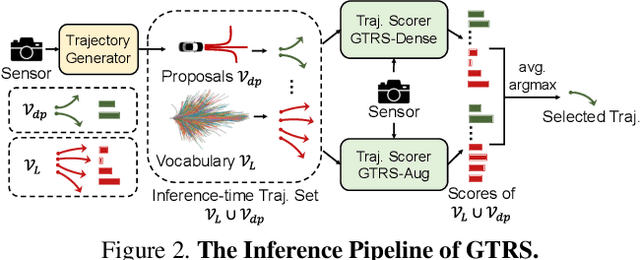
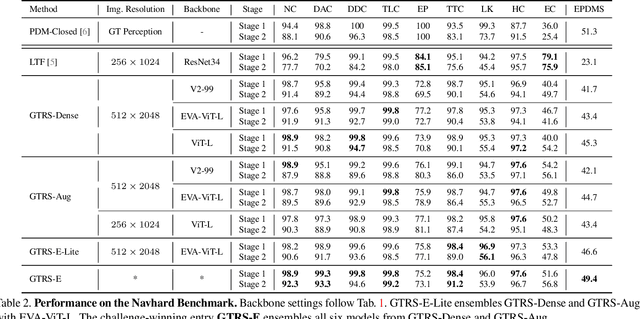
End-to-end multi-modal planning is a promising paradigm in autonomous driving, enabling decision-making with diverse trajectory candidates. A key component is a robust trajectory scorer capable of selecting the optimal trajectory from these candidates. While recent trajectory scorers focus on scoring either large sets of static trajectories or small sets of dynamically generated ones, both approaches face significant limitations in generalization. Static vocabularies provide effective coarse discretization but struggle to make fine-grained adaptation, while dynamic proposals offer detailed precision but fail to capture broader trajectory distributions. To overcome these challenges, we propose GTRS (Generalized Trajectory Scoring), a unified framework for end-to-end multi-modal planning that combines coarse and fine-grained trajectory evaluation. GTRS consists of three complementary innovations: (1) a diffusion-based trajectory generator that produces diverse fine-grained proposals; (2) a vocabulary generalization technique that trains a scorer on super-dense trajectory sets with dropout regularization, enabling its robust inference on smaller subsets; and (3) a sensor augmentation strategy that enhances out-of-domain generalization while incorporating refinement training for critical trajectory discrimination. As the winning solution of the Navsim v2 Challenge, GTRS demonstrates superior performance even with sub-optimal sensor inputs, approaching privileged methods that rely on ground-truth perception. Code will be available at https://github.com/NVlabs/GTRS.
OmniDrive: A Holistic Vision-Language Dataset for Autonomous Driving with Counterfactual Reasoning
Apr 06, 2025
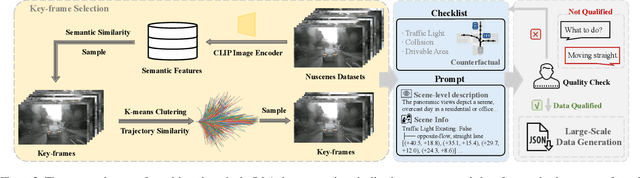
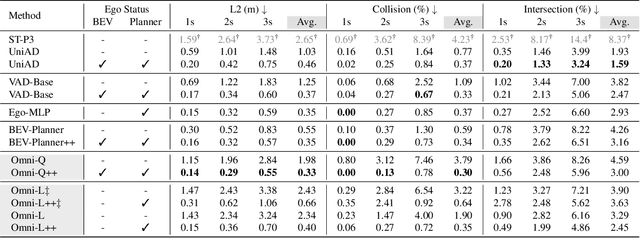
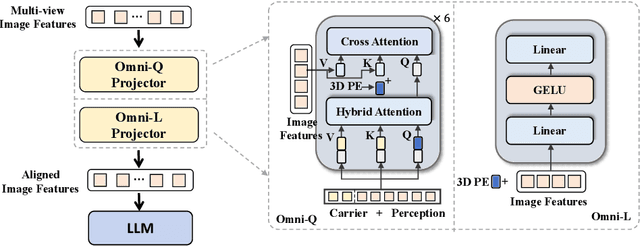
The advances in vision-language models (VLMs) have led to a growing interest in autonomous driving to leverage their strong reasoning capabilities. However, extending these capabilities from 2D to full 3D understanding is crucial for real-world applications. To address this challenge, we propose OmniDrive, a holistic vision-language dataset that aligns agent models with 3D driving tasks through counterfactual reasoning. This approach enhances decision-making by evaluating potential scenarios and their outcomes, similar to human drivers considering alternative actions. Our counterfactual-based synthetic data annotation process generates large-scale, high-quality datasets, providing denser supervision signals that bridge planning trajectories and language-based reasoning. Futher, we explore two advanced OmniDrive-Agent frameworks, namely Omni-L and Omni-Q, to assess the importance of vision-language alignment versus 3D perception, revealing critical insights into designing effective LLM-agents. Significant improvements on the DriveLM Q\&A benchmark and nuScenes open-loop planning demonstrate the effectiveness of our dataset and methods.
Enhancing Autonomous Driving Safety with Collision Scenario Integration
Mar 05, 2025Autonomous vehicle safety is crucial for the successful deployment of self-driving cars. However, most existing planning methods rely heavily on imitation learning, which limits their ability to leverage collision data effectively. Moreover, collecting collision or near-collision data is inherently challenging, as it involves risks and raises ethical and practical concerns. In this paper, we propose SafeFusion, a training framework to learn from collision data. Instead of over-relying on imitation learning, SafeFusion integrates safety-oriented metrics during training to enable collision avoidance learning. In addition, to address the scarcity of collision data, we propose CollisionGen, a scalable data generation pipeline to generate diverse, high-quality scenarios using natural language prompts, generative models, and rule-based filtering. Experimental results show that our approach improves planning performance in collision-prone scenarios by 56\% over previous state-of-the-art planners while maintaining effectiveness in regular driving situations. Our work provides a scalable and effective solution for advancing the safety of autonomous driving systems.
SSE: Multimodal Semantic Data Selection and Enrichment for Industrial-scale Data Assimilation
Sep 20, 2024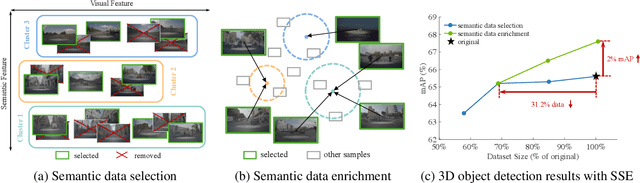


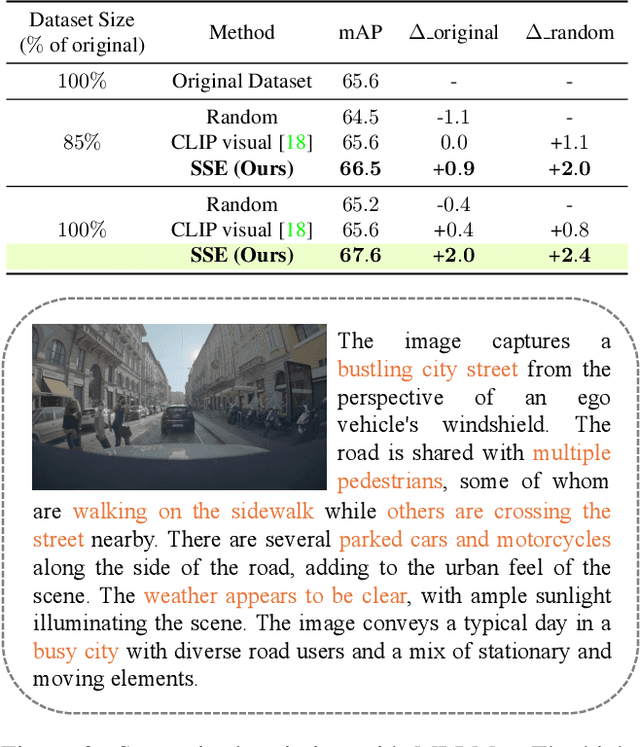
In recent years, the data collected for artificial intelligence has grown to an unmanageable amount. Particularly within industrial applications, such as autonomous vehicles, model training computation budgets are being exceeded while model performance is saturating -- and yet more data continues to pour in. To navigate the flood of data, we propose a framework to select the most semantically diverse and important dataset portion. Then, we further semantically enrich it by discovering meaningful new data from a massive unlabeled data pool. Importantly, we can provide explainability by leveraging foundation models to generate semantics for every data point. We quantitatively show that our Semantic Selection and Enrichment framework (SSE) can a) successfully maintain model performance with a smaller training dataset and b) improve model performance by enriching the smaller dataset without exceeding the original dataset size. Consequently, we demonstrate that semantic diversity is imperative for optimal data selection and model performance.
OmniDrive: A Holistic LLM-Agent Framework for Autonomous Driving with 3D Perception, Reasoning and Planning
May 02, 2024
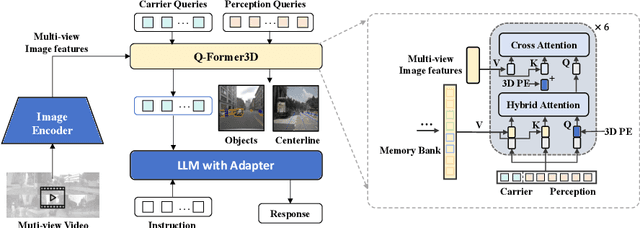
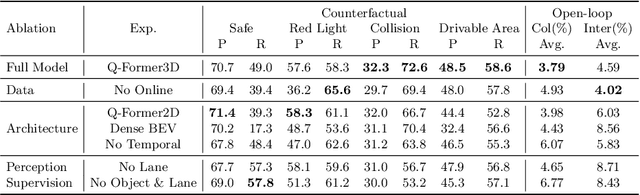

The advances in multimodal large language models (MLLMs) have led to growing interests in LLM-based autonomous driving agents to leverage their strong reasoning capabilities. However, capitalizing on MLLMs' strong reasoning capabilities for improved planning behavior is challenging since planning requires full 3D situational awareness beyond 2D reasoning. To address this challenge, our work proposes a holistic framework for strong alignment between agent models and 3D driving tasks. Our framework starts with a novel 3D MLLM architecture that uses sparse queries to lift and compress visual representations into 3D before feeding them into an LLM. This query-based representation allows us to jointly encode dynamic objects and static map elements (e.g., traffic lanes), providing a condensed world model for perception-action alignment in 3D. We further propose OmniDrive-nuScenes, a new visual question-answering dataset challenging the true 3D situational awareness of a model with comprehensive visual question-answering (VQA) tasks, including scene description, traffic regulation, 3D grounding, counterfactual reasoning, decision making and planning. Extensive studies show the effectiveness of the proposed architecture as well as the importance of the VQA tasks for reasoning and planning in complex 3D scenes.
Thinking Like an Annotator: Generation of Dataset Labeling Instructions
Jun 24, 2023Large-scale datasets are essential to modern day deep learning. Advocates argue that understanding these methods requires dataset transparency (e.g. "dataset curation, motivation, composition, collection process, etc..."). However, almost no one has suggested the release of the detailed definitions and visual category examples provided to annotators - information critical to understanding the structure of the annotations present in each dataset. These labels are at the heart of public datasets, yet few datasets include the instructions that were used to generate them. We introduce a new task, Labeling Instruction Generation, to address missing publicly available labeling instructions. In Labeling Instruction Generation, we take a reasonably annotated dataset and: 1) generate a set of examples that are visually representative of each category in the dataset; 2) provide a text label that corresponds to each of the examples. We introduce a framework that requires no model training to solve this task and includes a newly created rapid retrieval system that leverages a large, pre-trained vision and language model. This framework acts as a proxy to human annotators that can help to both generate a final labeling instruction set and evaluate its quality. Our framework generates multiple diverse visual and text representations of dataset categories. The optimized instruction set outperforms our strongest baseline across 5 folds by 7.06 mAP for NuImages and 12.9 mAP for COCO.
Image-Level or Object-Level? A Tale of Two Resampling Strategies for Long-Tailed Detection
Apr 12, 2021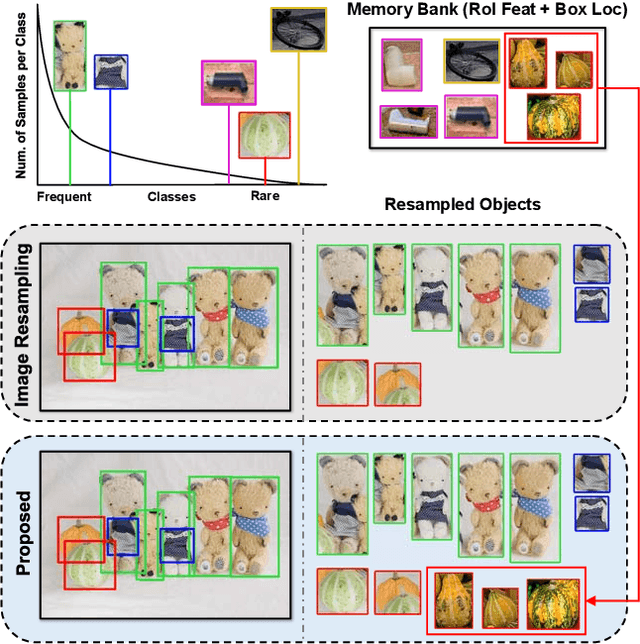
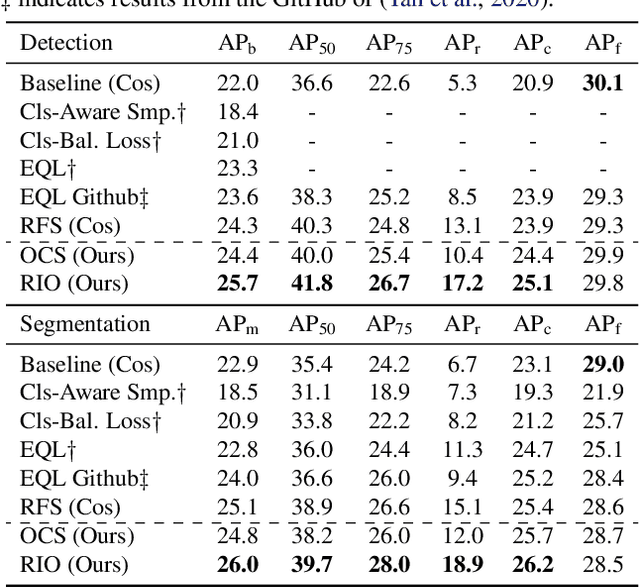

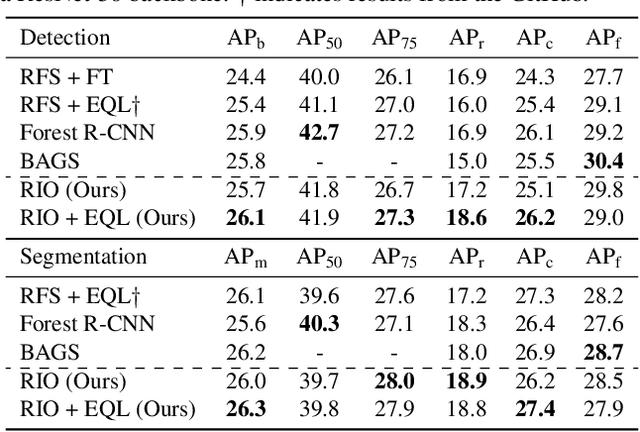
Training on datasets with long-tailed distributions has been challenging for major recognition tasks such as classification and detection. To deal with this challenge, image resampling is typically introduced as a simple but effective approach. However, we observe that long-tailed detection differs from classification since multiple classes may be present in one image. As a result, image resampling alone is not enough to yield a sufficiently balanced distribution at the object level. We address object-level resampling by introducing an object-centric memory replay strategy based on dynamic, episodic memory banks. Our proposed strategy has two benefits: 1) convenient object-level resampling without significant extra computation, and 2) implicit feature-level augmentation from model updates. We show that image-level and object-level resamplings are both important, and thus unify them with a joint resampling strategy (RIO). Our method outperforms state-of-the-art long-tailed detection and segmentation methods on LVIS v0.5 across various backbones.
Alpha Net: Adaptation with Composition in Classifier Space
Aug 17, 2020
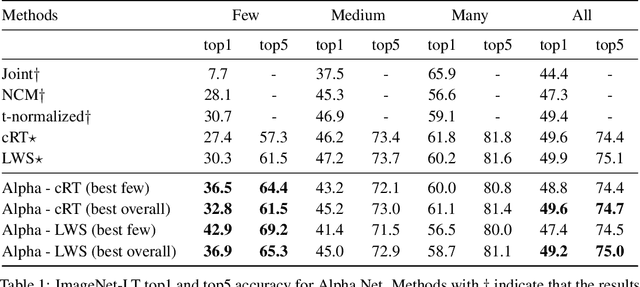
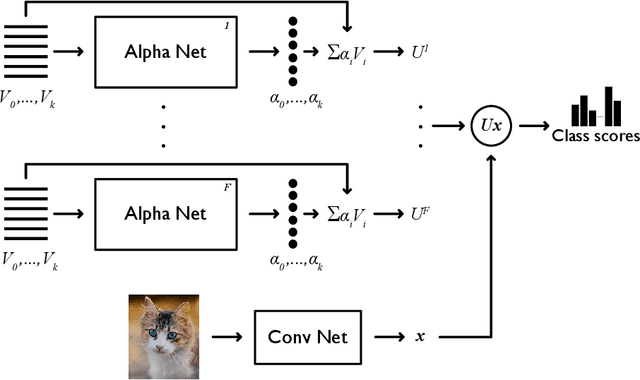
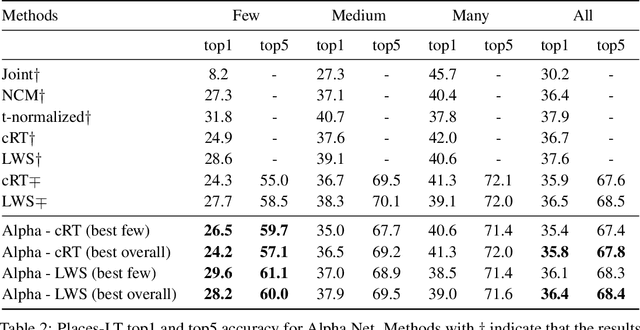
Deep learning classification models typically train poorly on classes with small numbers of examples. Motivated by the human ability to solve this task, models have been developed that transfer knowledge from classes with many examples to learn classes with few examples. Critically, the majority of these models transfer knowledge within model feature space. In this work, we demonstrate that transferring knowledge within classified space is more effective and efficient. Specifically, by linearly combining strong nearest neighbor classifiers along with a weak classifier, we are able to compose a stronger classifier. Uniquely, our model can be implemented on top of any existing classification model that includes a classifier layer. We showcase the success of our approach in the task of long-tailed recognition, whereby the classes with few examples, otherwise known as the "tail" classes, suffer the most in performance and are the most challenging classes to learn. Using classifier-level knowledge transfer, we are able to drastically improve - by a margin as high as 12.6% - the state-of-the-art performance on the "tail" categories.
BOLD5000: A public fMRI dataset of 5000 images
Sep 05, 2018
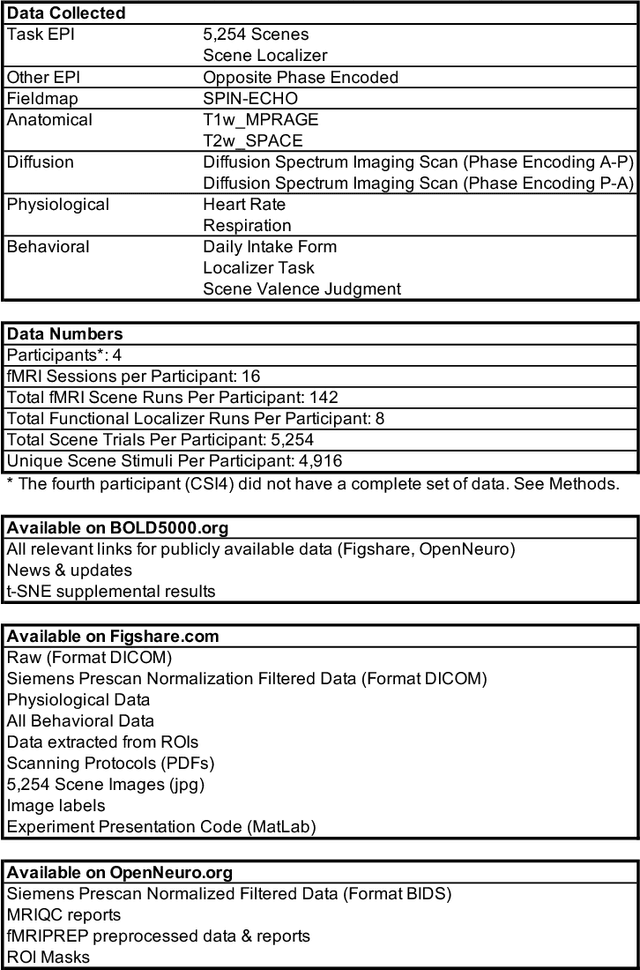
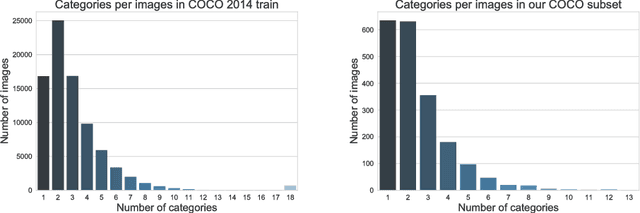

Vision science, particularly machine vision, has been revolutionized by introducing large-scale image datasets and statistical learning approaches. Yet, human neuroimaging studies of visual perception still rely on small numbers of images (around 100) due to time-constrained experimental procedures. To apply statistical learning approaches that integrate neuroscience, the number of images used in neuroimaging must be significantly increased. We present BOLD5000, a human functional MRI (fMRI) study that includes almost 5,000 distinct images depicting real-world scenes. Beyond dramatically increasing image dataset size relative to prior fMRI studies, BOLD5000 also accounts for image diversity, overlapping with standard computer vision datasets by incorporating images from the Scene UNderstanding (SUN), Common Objects in Context (COCO), and ImageNet datasets. The scale and diversity of these image datasets, combined with a slow event-related fMRI design, enable fine-grained exploration into the neural representation of a wide range of visual features, categories, and semantics. Concurrently, BOLD5000 brings us closer to realizing Marr's dream of a singular vision science - the intertwined study of biological and computer vision.