 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSE: Multimodal Semantic Data Selection and Enrichment for Industrial-scale Data Assimilation
Paper and Code
Sep 20, 2024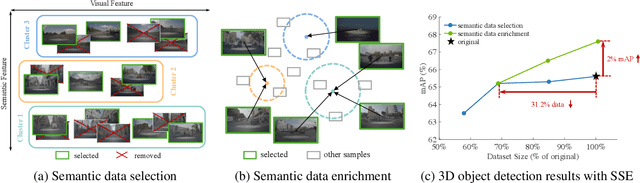


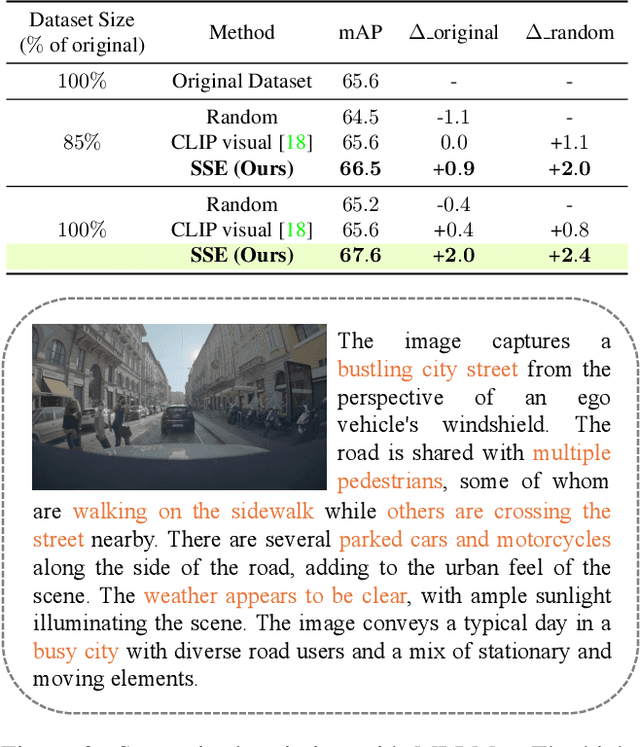
In recent years, the data collected for artificial intelligence has grown to an unmanageable amount. Particularly within industrial applications, such as autonomous vehicles, model training computation budgets are being exceeded while model performance is saturating -- and yet more data continues to pour in. To navigate the flood of data, we propose a framework to select the most semantically diverse and important dataset portion. Then, we further semantically enrich it by discovering meaningful new data from a massive unlabeled data pool. Importantly, we can provide explainability by leveraging foundation models to generate semantics for every data point. We quantitatively show that our Semantic Selection and Enrichment framework (SSE) can a) successfully maintain model performance with a smaller training dataset and b) improve model performance by enriching the smaller dataset without exceeding the original dataset size. Consequently, we demonstrate that semantic diversity is imperative for optimal data selection and model performance.