 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning powered real-time identification of insects using citizen science data
Jun 04, 2023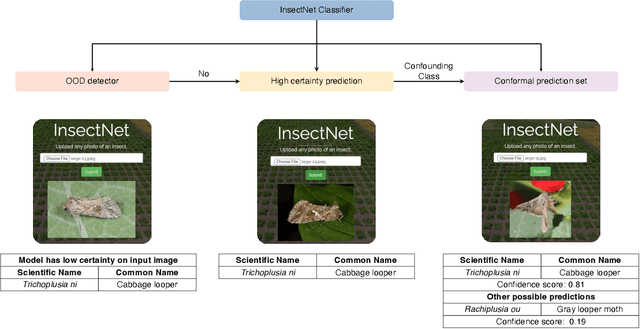
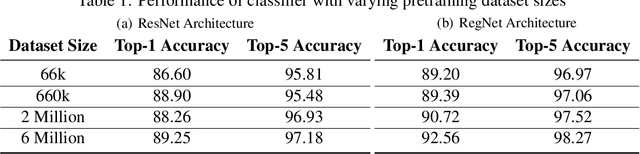
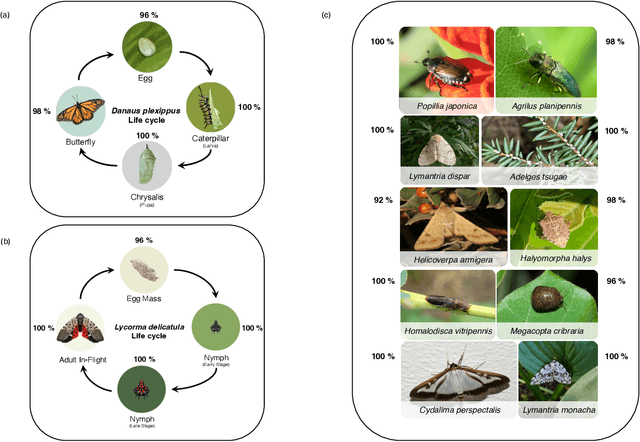
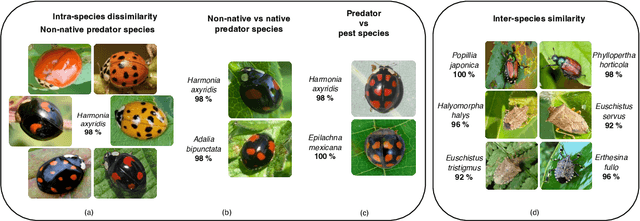
Insect-pests significantly impact global agricultural productivity and quality. Effective management involves identifying the full insect community, including beneficial insects and harmful pests, to develop and implement integrated pest management strategies. Automated identification of insects under real-world conditions presents several challenges, including differentiating similar-looking species, intra-species dissimilarity and inter-species similarity, several life cycle stages, camouflage, diverse imaging conditions, and variability in insect orientation. A deep-learning model, InsectNet, is proposed to address these challenges. InsectNet is endowed with five key features: (a) utilization of a large dataset of insect images collected through citizen science; (b) label-free self-supervised learning for large models; (c) improving prediction accuracy for species with a small sample size; (d) enhancing model trustworthiness; and (e) democratizing access through streamlined MLOps. This approach allows accurate identification (>96% accuracy) of over 2500 insect species, including pollinator (e.g., butterflies, bees), parasitoid (e.g., some wasps and flies), predator species (e.g., lady beetles, mantises, dragonflies) and harmful pest species (e.g., armyworms, cutworms, grasshoppers, stink bugs). InsectNet can identify invasive species, provide fine-grained insect species identification, and work effectively in challenging backgrounds. It also can abstain from making predictions when uncertain, facilitating seamless human intervention and making it a practical and trustworthy tool. InsectNet can guide citizen science data collection, especially for invasive species where early detection is crucial. Similar approaches may transform other agricultural challenges like disease detection and underscore the importance of data collection, particularly through citizen science efforts..
Alpha Net: Adaptation with Composition in Classifier Space
Aug 17, 2020
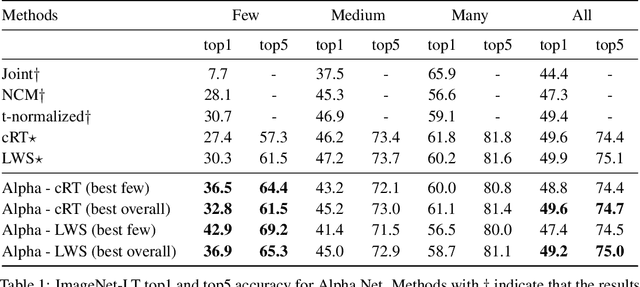
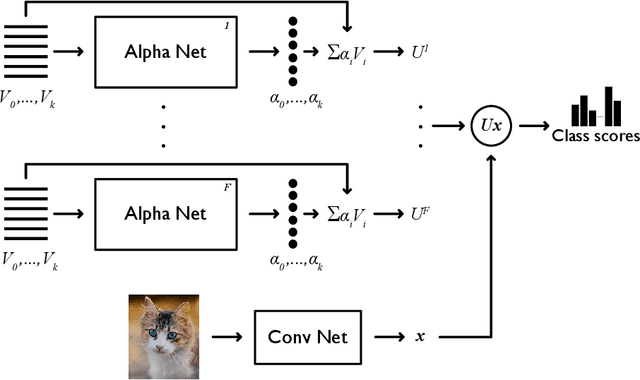
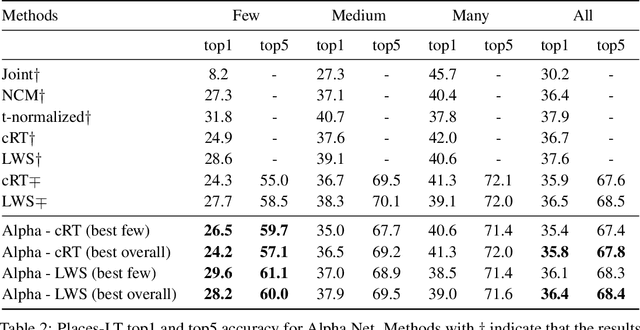
Deep learning classification models typically train poorly on classes with small numbers of examples. Motivated by the human ability to solve this task, models have been developed that transfer knowledge from classes with many examples to learn classes with few examples. Critically, the majority of these models transfer knowledge within model feature space. In this work, we demonstrate that transferring knowledge within classified space is more effective and efficient. Specifically, by linearly combining strong nearest neighbor classifiers along with a weak classifier, we are able to compose a stronger classifier. Uniquely, our model can be implemented on top of any existing classification model that includes a classifier layer. We showcase the success of our approach in the task of long-tailed recognition, whereby the classes with few examples, otherwise known as the "tail" classes, suffer the most in performance and are the most challenging classes to learn. Using classifier-level knowledge transfer, we are able to drastically improve - by a margin as high as 12.6% - the state-of-the-art performance on the "tail" categories.
Eve: A Gradient Based Optimization Method with Locally and Globally Adaptive Learning Rates
Jun 11, 2018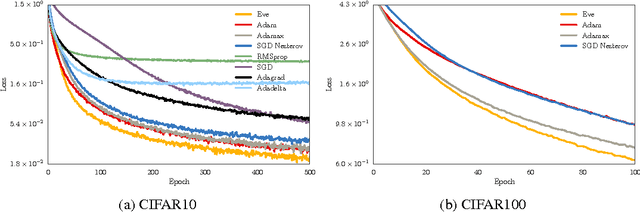
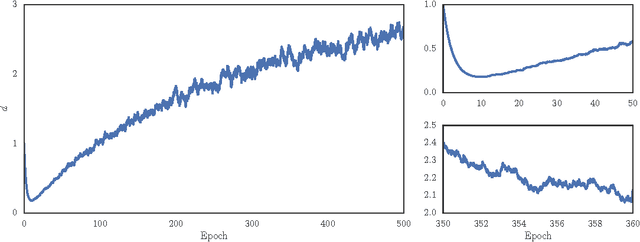
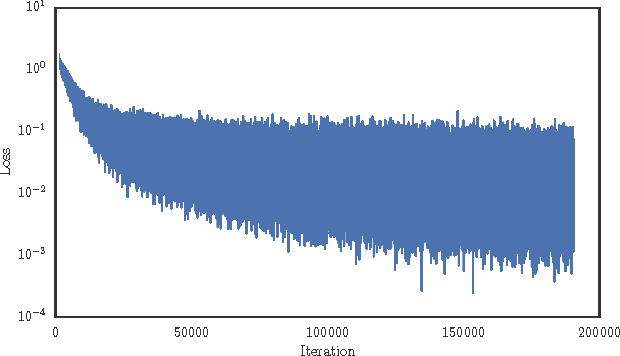
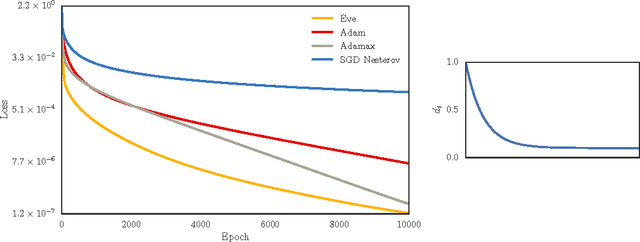
Adaptive gradient methods for stochastic optimization adjust the learning rate for each parameter locally. However, there is also a global learning rate which must be tuned in order to get the best performance. In this paper, we present a new algorithm that adapts the learning rate locally for each parameter separately, and also globally for all parameters together. Specifically, we modify Adam, a popular method for training deep learning models, with a coefficient that captures properties of the objective function. Empirically, we show that our method, which we call Eve, outperforms Adam and other popular methods in training deep neural networks, like convolutional neural networks for image classification, and recurrent neural networks for language tasks.
Hypothesis Transfer Learning via Transformation Functions
Nov 05, 2017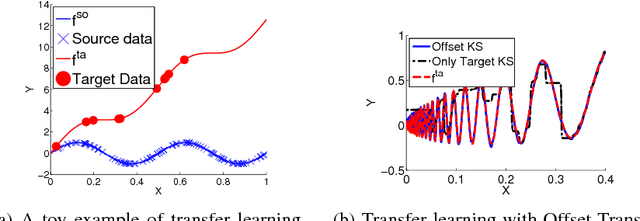
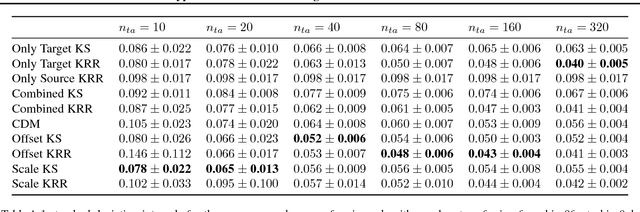
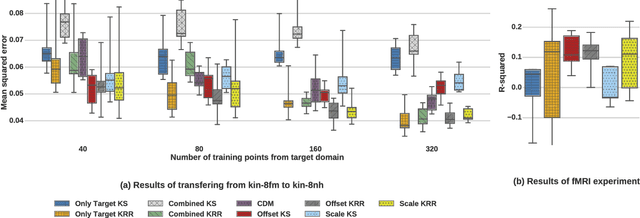
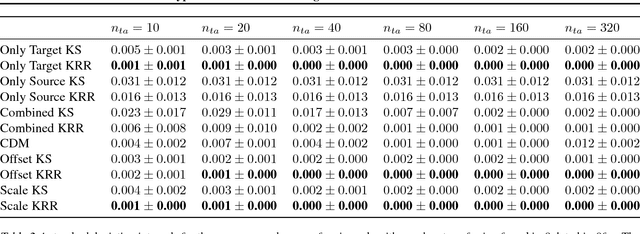
We consider the Hypothesis Transfer Learning (HTL) problem where one incorporates a hypothesis trained on the source domain into the learning procedure of the target domain. Existing theoretical analysis either only studies specific algorithms or only presents upper bounds on the generalization error but not on the excess risk. In this paper, we propose a unified algorithm-dependent framework for HTL through a novel notion of transformation function, which characterizes the relation between the source and the target domains. We conduct a general risk analysis of this framework and in particular, we show for the first time, if two domains are related, HTL enjoys faster convergence rates of excess risks for Kernel Smoothing and Kernel Ridge Regression than those of the classical non-transfer learning settings. Experiments on real world data demonstrate the effectiveness of our framework.