 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Large Reasoning Models for Agriculture
May 25, 2025Agricultural decision-making involves complex, context-specific reasoning, where choices about crops, practices, and interventions depend heavily on geographic, climatic, and economic conditions. Traditional large language models (LLMs) often fall short in navigating this nuanced problem due to limited reasoning capacity. We hypothesize that recent advances in large reasoning models (LRMs) can better handle such structured, domain-specific inference. To investigate this, we introduce AgReason, the first expert-curated open-ended science benchmark with 100 questions for agricultural reasoning. Evaluations across thirteen open-source and proprietary models reveal that LRMs outperform conventional ones, though notable challenges persist, with the strongest Gemini-based baseline achieving 36% accuracy. We also present AgThoughts, a large-scale dataset of 44.6K question-answer pairs generated with human oversight and equipped with synthetically generated reasoning traces. Using AgThoughts, we develop AgThinker, a suite of small reasoning models that can be run on consumer-grade GPUs, and show that our dataset can be effective in unlocking agricultural reasoning abilities in LLMs. Our project page is here: https://baskargroup.github.io/Ag_reasoning/
WeedNet: A Foundation Model-Based Global-to-Local AI Approach for Real-Time Weed Species Identification and Classification
May 25, 2025
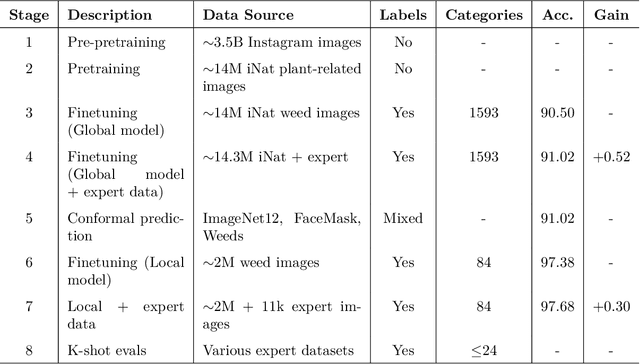


Early identification of weeds is essential for effective management and control, and there is growing interest in automating the process using computer vision techniques coupled with AI methods. However, challenges associated with training AI-based weed identification models, such as limited expert-verified data and complexity and variability in morphological features, have hindered progress. To address these issues, we present WeedNet, the first global-scale weed identification model capable of recognizing an extensive set of weed species, including noxious and invasive plant species. WeedNet is an end-to-end real-time weed identification pipeline and uses self-supervised learning, fine-tuning, and enhanced trustworthiness strategies. WeedNet achieved 91.02% accuracy across 1,593 weed species, with 41% species achieving 100% accuracy. Using a fine-tuning strategy and a Global-to-Local approach, the local Iowa WeedNet model achieved an overall accuracy of 97.38% for 85 Iowa weeds, most classes exceeded a 90% mean accuracy per class. Testing across intra-species dissimilarity (developmental stages) and inter-species similarity (look-alike species) suggests that diversity in the images collected, spanning all the growth stages and distinguishable plant characteristics, is crucial in driving model performance. The generalizability and adaptability of the Global WeedNet model enable it to function as a foundational model, with the Global-to-Local strategy allowing fine-tuning for region-specific weed communities. Additional validation of drone- and ground-rover-based images highlights the potential of WeedNet for integration into robotic platforms. Furthermore, integration with AI for conversational use provides intelligent agricultural and ecological conservation consulting tools for farmers, agronomists, researchers, land managers, and government agencies across diverse landscapes.
Robust soybean seed yield estimation using high-throughput ground robot videos
Dec 03, 2024
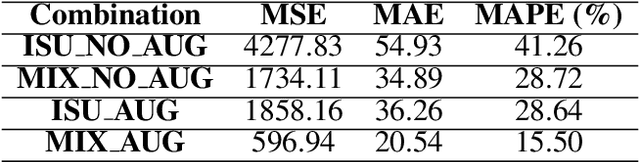


We present a novel method for soybean (Glycine max (L.) Merr.) yield estimation leveraging high throughput seed counting via computer vision and deep learning techniques. Traditional methods for collecting yield data are labor-intensive, costly, prone to equipment failures at critical data collection times, and require transportation of equipment across field sites. Computer vision, the field of teaching computers to interpret visual data, allows us to extract detailed yield information directly from images. By treating it as a computer vision task, we report a more efficient alternative, employing a ground robot equipped with fisheye cameras to capture comprehensive videos of soybean plots from which images are extracted in a variety of development programs. These images are processed through the P2PNet-Yield model, a deep learning framework where we combined a Feature Extraction Module (the backbone of the P2PNet-Soy) and a Yield Regression Module to estimate seed yields of soybean plots. Our results are built on three years of yield testing plot data - 8500 in 2021, 2275 in 2022, and 650 in 2023. With these datasets, our approach incorporates several innovations to further improve the accuracy and generalizability of the seed counting and yield estimation architecture, such as the fisheye image correction and data augmentation with random sensor effects. The P2PNet-Yield model achieved a genotype ranking accuracy score of up to 83%. It demonstrates up to a 32% reduction in time to collect yield data as well as costs associated with traditional yield estimation, offering a scalable solution for breeding programs and agricultural productivity enhancement.
Arboretum: A Large Multimodal Dataset Enabling AI for Biodiversity
Jun 25, 2024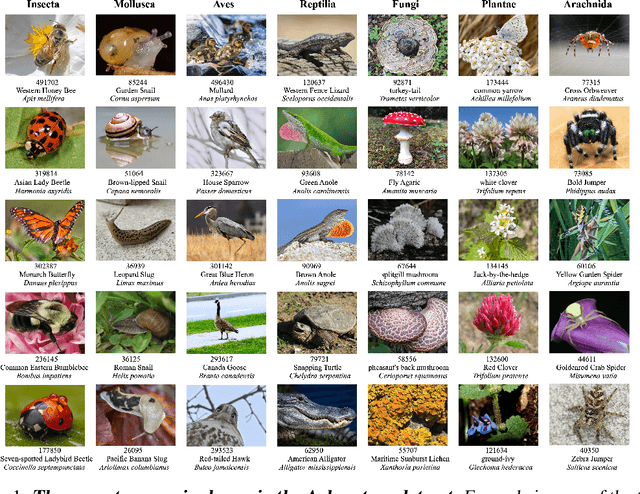

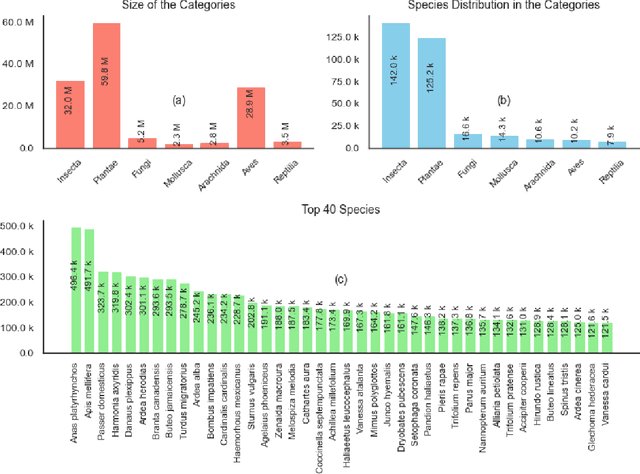

We introduce Arboretum, the largest publicly accessible dataset designed to advance AI for biodiversity applications. This dataset, curated from the iNaturalist community science platform and vetted by domain experts to ensure accuracy, includes 134.6 million images, surpassing existing datasets in scale by an order of magnitude. The dataset encompasses image-language paired data for a diverse set of species from birds (Aves), spiders/ticks/mites (Arachnida), insects (Insecta), plants (Plantae), fungus/mushrooms (Fungi), snails (Mollusca), and snakes/lizards (Reptilia), making it a valuable resource for multimodal vision-language AI models for biodiversity assessment and agriculture research. Each image is annotated with scientific names, taxonomic details, and common names, enhancing the robustness of AI model training. We showcase the value of Arboretum by releasing a suite of CLIP models trained using a subset of 40 million captioned images. We introduce several new benchmarks for rigorous assessment, report accuracy for zero-shot learning, and evaluations across life stages, rare species, confounding species, and various levels of the taxonomic hierarchy. We anticipate that Arboretum will spur the development of AI models that can enable a variety of digital tools ranging from pest control strategies, crop monitoring, and worldwide biodiversity assessment and environmental conservation. These advancements are critical for ensuring food security, preserving ecosystems, and mitigating the impacts of climate change. Arboretum is publicly available, easily accessible, and ready for immediate use. Please see the \href{https://baskargroup.github.io/Arboretum/}{project website} for links to our data, models, and code.
Deep learning powered real-time identification of insects using citizen science data
Jun 04, 2023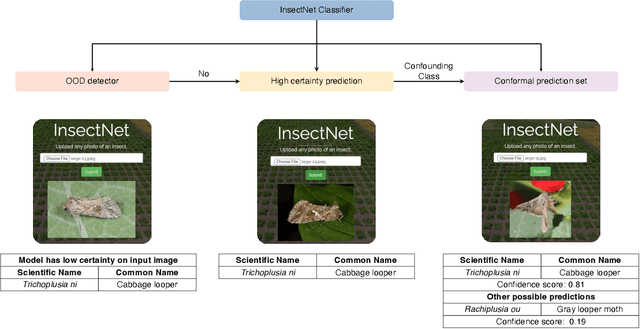
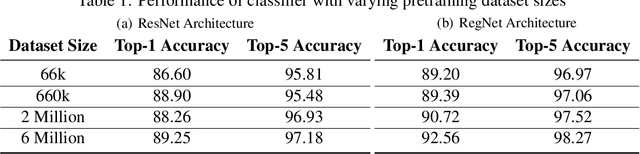
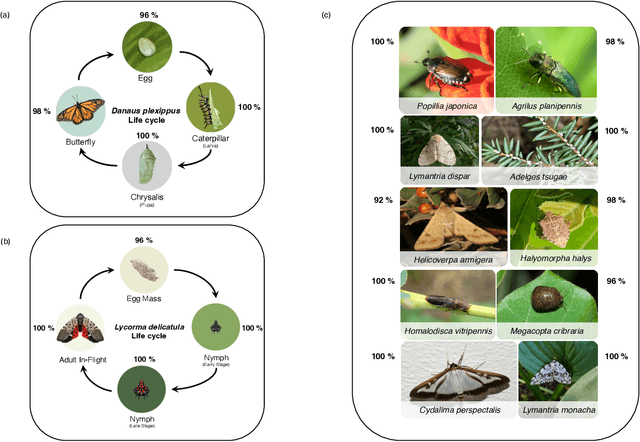
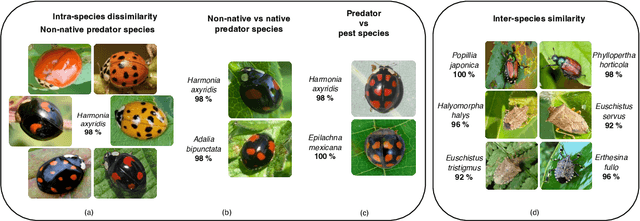
Insect-pests significantly impact global agricultural productivity and quality. Effective management involves identifying the full insect community, including beneficial insects and harmful pests, to develop and implement integrated pest management strategies. Automated identification of insects under real-world conditions presents several challenges, including differentiating similar-looking species, intra-species dissimilarity and inter-species similarity, several life cycle stages, camouflage, diverse imaging conditions, and variability in insect orientation. A deep-learning model, InsectNet, is proposed to address these challenges. InsectNet is endowed with five key features: (a) utilization of a large dataset of insect images collected through citizen science; (b) label-free self-supervised learning for large models; (c) improving prediction accuracy for species with a small sample size; (d) enhancing model trustworthiness; and (e) democratizing access through streamlined MLOps. This approach allows accurate identification (>96% accuracy) of over 2500 insect species, including pollinator (e.g., butterflies, bees), parasitoid (e.g., some wasps and flies), predator species (e.g., lady beetles, mantises, dragonflies) and harmful pest species (e.g., armyworms, cutworms, grasshoppers, stink bugs). InsectNet can identify invasive species, provide fine-grained insect species identification, and work effectively in challenging backgrounds. It also can abstain from making predictions when uncertain, facilitating seamless human intervention and making it a practical and trustworthy tool. InsectNet can guide citizen science data collection, especially for invasive species where early detection is crucial. Similar approaches may transform other agricultural challenges like disease detection and underscore the importance of data collection, particularly through citizen science efforts..
Out-of-distribution detection algorithms for robust insect classification
May 02, 2023Deep learning-based approaches have produced models with good insect classification accuracy; Most of these models are conducive for application in controlled environmental conditions. One of the primary emphasis of researchers is to implement identification and classification models in the real agriculture fields, which is challenging because input images that are wildly out of the distribution (e.g., images like vehicles, animals, humans, or a blurred image of an insect or insect class that is not yet trained on) can produce an incorrect insect classification. Out-of-distribution (OOD) detection algorithms provide an exciting avenue to overcome these challenge as it ensures that a model abstains from making incorrect classification prediction of non-insect and/or untrained insect class images. We generate and evaluate the performance of state-of-the-art OOD algorithms on insect detection classifiers. These algorithms represent a diversity of methods for addressing an OOD problem. Specifically, we focus on extrusive algorithms, i.e., algorithms that wrap around a well-trained classifier without the need for additional co-training. We compared three OOD detection algorithms: (i) Maximum Softmax Probability, which uses the softmax value as a confidence score, (ii) Mahalanobis distance-based algorithm, which uses a generative classification approach; and (iii) Energy-Based algorithm that maps the input data to a scalar value, called energy. We performed an extensive series of evaluations of these OOD algorithms across three performance axes: (a) \textit{Base model accuracy}: How does the accuracy of the classifier impact OOD performance? (b) How does the \textit{level of dissimilarity to the domain} impact OOD performance? and (c) \textit{Data imbalance}: How sensitive is OOD performance to the imbalance in per-class sample size?