 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Specific Benchmarks for Evaluating Multimodal Large Language Models
Jun 15, 2025Large language models (LLMs) are increasingly being deployed across disciplines due to their advanced reasoning and problem solving capabilities. To measure their effectiveness, various benchmarks have been developed that measure aspects of LLM reasoning, comprehension, and problem-solving. While several surveys address LLM evaluation and benchmarks, a domain-specific analysis remains underexplored in the literature. This paper introduces a taxonomy of seven key disciplines, encompassing various domains and application areas where LLMs are extensively utilized. Additionally, we provide a comprehensive review of LLM benchmarks and survey papers within each domain, highlighting the unique capabilities of LLMs and the challenges faced in their application. Finally, we compile and categorize these benchmarks by domain to create an accessible resource for researchers, aiming to pave the way for advancements toward artificial general intelligence (AGI)
WeedNet: A Foundation Model-Based Global-to-Local AI Approach for Real-Time Weed Species Identification and Classification
May 25, 2025
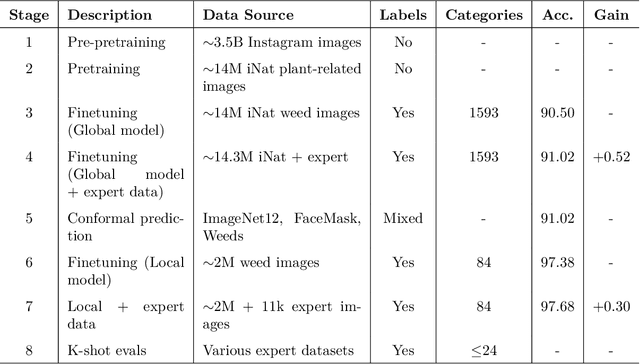


Early identification of weeds is essential for effective management and control, and there is growing interest in automating the process using computer vision techniques coupled with AI methods. However, challenges associated with training AI-based weed identification models, such as limited expert-verified data and complexity and variability in morphological features, have hindered progress. To address these issues, we present WeedNet, the first global-scale weed identification model capable of recognizing an extensive set of weed species, including noxious and invasive plant species. WeedNet is an end-to-end real-time weed identification pipeline and uses self-supervised learning, fine-tuning, and enhanced trustworthiness strategies. WeedNet achieved 91.02% accuracy across 1,593 weed species, with 41% species achieving 100% accuracy. Using a fine-tuning strategy and a Global-to-Local approach, the local Iowa WeedNet model achieved an overall accuracy of 97.38% for 85 Iowa weeds, most classes exceeded a 90% mean accuracy per class. Testing across intra-species dissimilarity (developmental stages) and inter-species similarity (look-alike species) suggests that diversity in the images collected, spanning all the growth stages and distinguishable plant characteristics, is crucial in driving model performance. The generalizability and adaptability of the Global WeedNet model enable it to function as a foundational model, with the Global-to-Local strategy allowing fine-tuning for region-specific weed communities. Additional validation of drone- and ground-rover-based images highlights the potential of WeedNet for integration into robotic platforms. Furthermore, integration with AI for conversational use provides intelligent agricultural and ecological conservation consulting tools for farmers, agronomists, researchers, land managers, and government agencies across diverse landscapes.
From Predictive Importance to Causality: Which Machine Learning Model Reflects Reality?
Sep 01, 2024



This study analyzes the Ames Housing Dataset using CatBoost and LightGBM models to explore feature importance and causal relationships in housing price prediction. We examine the correlation between SHAP values and EconML predictions, achieving high accuracy in price forecasting. Our analysis reveals a moderate Spearman rank correlation of 0.48 between SHAP-based feature importance and causally significant features, highlighting the complexity of aligning predictive modeling with causal understanding in housing market analysis. Through extensive causal analysis, including heterogeneity exploration and policy tree interpretation, we provide insights into how specific features like porches impact housing prices across various scenarios. This work underscores the need for integrated approaches that combine predictive power with causal insights in real estate valuation, offering valuable guidance for stakeholders in the industry.
AgEval: A Benchmark for Zero-Shot and Few-Shot Plant Stress Phenotyping with Multimodal LLMs
Jul 29, 2024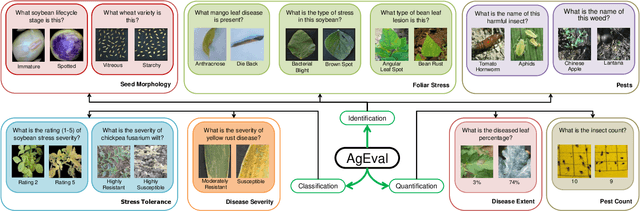
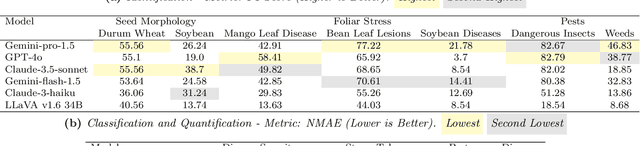
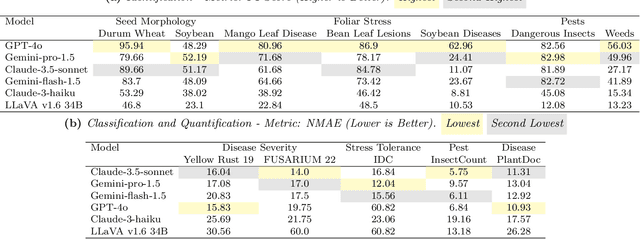
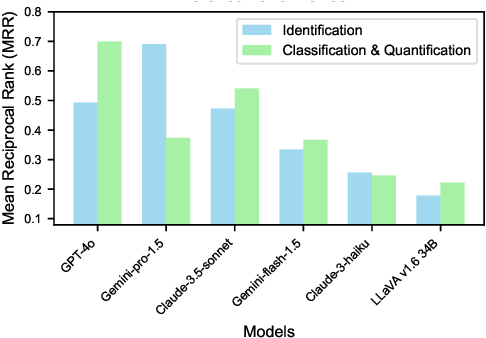
Plant stress phenotyping traditionally relies on expert assessments and specialized models, limiting scalability in agriculture. Recent advances in multimodal large language models (LLMs) offer potential solutions to this challenge. We present AgEval, a benchmark comprising 12 diverse plant stress phenotyping tasks, to evaluate these models' capabilities. Our study assesses zero-shot and few-shot in-context learning performance of state-of-the-art models, including Claude, GPT, Gemini, and LLaVA. Results show significant performance improvements with few-shot learning, with F1 scores increasing from 46.24% to 73.37% in 8-shot identification for the best-performing model. Few-shot examples from other classes in the dataset have negligible or negative impacts, although having the exact category example helps to increase performance by 15.38%. We also quantify the consistency of model performance across different classes within each task, finding that the coefficient of variance (CV) ranges from 26.02% to 58.03% across models, implying that subject matter expertise is needed - of 'difficult' classes - to achieve reliability in performance. AgEval establishes baseline metrics for multimodal LLMs in agricultural applications, offering insights into their promise for enhancing plant stress phenotyping at scale. Benchmark and code can be accessed at: https://anonymous.4open.science/r/AgEval/
Evaluating NeRFs for 3D Plant Geometry Reconstruction in Field Conditions
Feb 15, 2024We evaluate different Neural Radiance Fields (NeRFs) techniques for reconstructing (3D) plants in varied environments, from indoor settings to outdoor fields. Traditional techniques often struggle to capture the complex details of plants, which is crucial for botanical and agricultural understanding. We evaluate three scenarios with increasing complexity and compare the results with the point cloud obtained using LiDAR as ground truth data. In the most realistic field scenario, the NeRF models achieve a 74.65% F1 score with 30 minutes of training on the GPU, highlighting the efficiency and accuracy of NeRFs in challenging environments. These findings not only demonstrate the potential of NeRF in detailed and realistic 3D plant modeling but also suggest practical approaches for enhancing the speed and efficiency of the 3D reconstruction process.
Mutation-based Fault Localization of Deep Neural Networks
Sep 10, 2023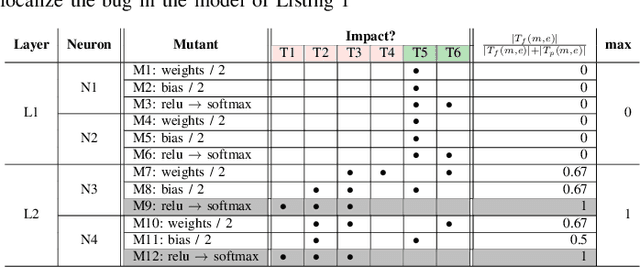
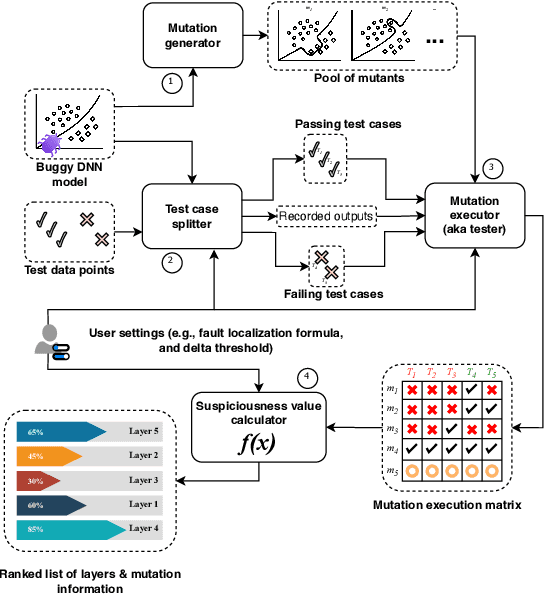

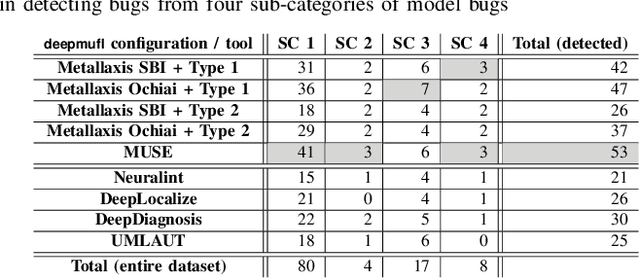
Deep neural networks (DNNs) are susceptible to bugs, just like other types of software systems. A significant uptick in using DNN, and its applications in wide-ranging areas, including safety-critical systems, warrant extensive research on software engineering tools for improving the reliability of DNN-based systems. One such tool that has gained significant attention in the recent years is DNN fault localization. This paper revisits mutation-based fault localization in the context of DNN models and proposes a novel technique, named deepmufl, applicable to a wide range of DNN models. We have implemented deepmufl and have evaluated its effectiveness using 109 bugs obtained from StackOverflow. Our results show that deepmufl detects 53/109 of the bugs by ranking the buggy layer in top-1 position, outperforming state-of-the-art static and dynamic DNN fault localization systems that are also designed to target the class of bugs supported by deepmufl. Moreover, we observed that we can halve the fault localization time for a pre-trained model using mutation selection, yet losing only 7.55% of the bugs localized in top-1 position.
The Power Of Simplicity: Why Simple Linear Models Outperform Complex Machine Learning Techniques -- Case Of Breast Cancer Diagnosis
Jun 04, 2023This research paper investigates the effectiveness of simple linear models versus complex machine learning techniques in breast cancer diagnosis, emphasizing the importance of interpretability and computational efficiency in the medical domain. We focus on Logistic Regression (LR), Decision Trees (DT), and Support Vector Machines (SVM) and optimize their performance using the UCI Machine Learning Repository dataset. Our findings demonstrate that the simpler linear model, LR, outperforms the more complex DT and SVM techniques, with a test score mean of 97.28%, a standard deviation of 1.62%, and a computation time of 35.56 ms. In comparison, DT achieved a test score mean of 93.73%, and SVM had a test score mean of 96.44%. The superior performance of LR can be attributed to its simplicity and interpretability, which provide a clear understanding of the relationship between input features and the outcome. This is particularly valuable in the medical domain, where interpretability is crucial for decision-making. Moreover, the computational efficiency of LR offers advantages in terms of scalability and real-world applicability. The results of this study highlight the power of simplicity in the context of breast cancer diagnosis and suggest that simpler linear models like LR can be more effective, interpretable, and computationally efficient than their complex counterparts, making them a more suitable choice for medical applications.