 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLighting-aware Unified Model for Instance Segmentation
May 19, 2026Foundation models like the Segment Anything Model (SAM) demonstrate impressive zero-shot generalization but frequently degrade under diverse real-world illumination, particularly for instance segmentation. In this work, we address this limitation by developing \textit{Lighting Convolutional-Attention (\lca{})}, an adapter module that enhances segmentation robustness without fine-tuning the heavy backbone. \lca{} employs a dual-branch architecture to process RGB features alongside contrast maps, enabling physically motivated sensitivity to structural changes rather than illumination artifacts. We optimize \lca{} through a pairwise training strategy, introducing a targeted loss term that explicitly penalizes discrepancies between clean images and their corresponding illumination variants. To evaluate and support this architecture, we conduct a comprehensive empirical study across multiple existing benchmarks and present a novel Unity-based synthetic dataset specifically designed to accurately replicate complex real-world lighting conditions. Extensive experimental results demonstrate that our approach successfully bridges the domain gap, delivering superior lighting-robust segmentation.
HS-3D-NeRF: 3D Surface and Hyperspectral Reconstruction From Stationary Hyperspectral Images Using Multi-Channel NeRFs
Feb 18, 2026Advances in hyperspectral imaging (HSI) and 3D reconstruction have enabled accurate, high-throughput characterization of agricultural produce quality and plant phenotypes, both essential for advancing agricultural sustainability and breeding programs. HSI captures detailed biochemical features of produce, while 3D geometric data substantially improves morphological analysis. However, integrating these two modalities at scale remains challenging, as conventional approaches involve complex hardware setups incompatible with automated phenotyping systems. Recent advances in neural radiance fields (NeRF) offer computationally efficient 3D reconstruction but typically require moving-camera setups, limiting throughput and reproducibility in standard indoor agricultural environments. To address these challenges, we introduce HSI-SC-NeRF, a stationary-camera multi-channel NeRF framework for high-throughput hyperspectral 3D reconstruction targeting postharvest inspection of agricultural produce. Multi-view hyperspectral data is captured using a stationary camera while the object rotates within a custom-built Teflon imaging chamber providing diffuse, uniform illumination. Object poses are estimated via ArUco calibration markers and transformed to the camera frame of reference through simulated pose transformations, enabling standard NeRF training on stationary-camera data. A multi-channel NeRF formulation optimizes reconstruction across all hyperspectral bands jointly using a composite spectral loss, supported by a two-stage training protocol that decouples geometric initialization from radiometric refinement. Experiments on three agricultural produce samples demonstrate high spatial reconstruction accuracy and strong spectral fidelity across the visible and near-infrared spectrum, confirming the suitability of HSI-SC-NeRF for integration into automated agricultural workflows.
Artifact Removal and Image Restoration in AFM:A Structured Mask-Guided Directional Inpainting Approach
Feb 03, 2026Atomic Force Microscopy (AFM) enables high-resolution surface imaging at the nanoscale, yet the output is often degraded by artifacts introduced by environmental noise, scanning imperfections, and tip-sample interactions. To address this challenge, a lightweight and fully automated framework for artifact detection and restoration in AFM image analysis is presented. The pipeline begins with a classification model that determines whether an AFM image contains artifacts. If necessary, a lightweight semantic segmentation network, custom-designed and trained on AFM data, is applied to generate precise artifact masks. These masks are adaptively expanded based on their structural orientation and then inpainted using a directional neighbor-based interpolation strategy to preserve 3D surface continuity. A localized Gaussian smoothing operation is then applied for seamless restoration. The system is integrated into a user-friendly GUI that supports real-time parameter adjustments and batch processing. Experimental results demonstrate the effective artifact removal while preserving nanoscale structural details, providing a robust, geometry-aware solution for high-fidelity AFM data interpretation.
FloraForge: LLM-Assisted Procedural Generation of Editable and Analysis-Ready 3D Plant Geometric Models For Agricultural Applications
Dec 11, 2025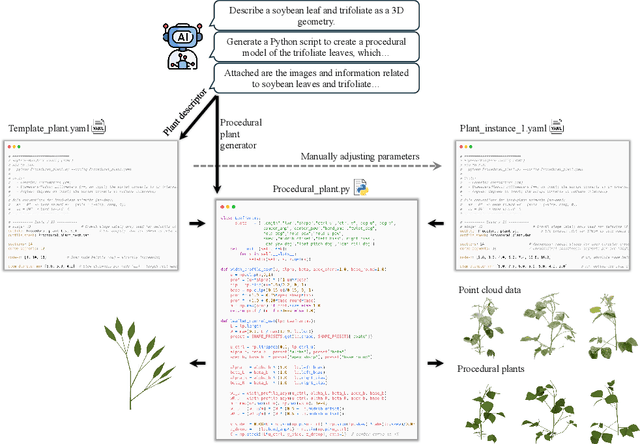
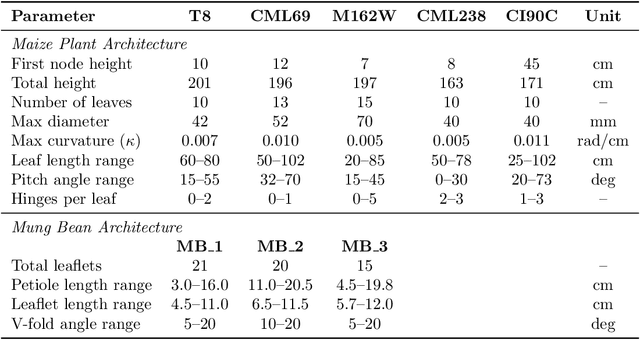
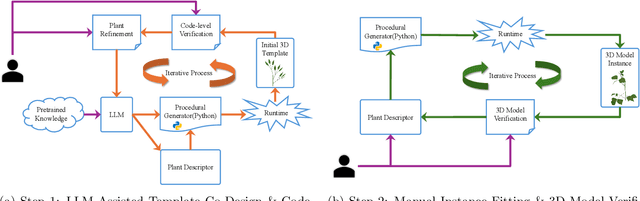
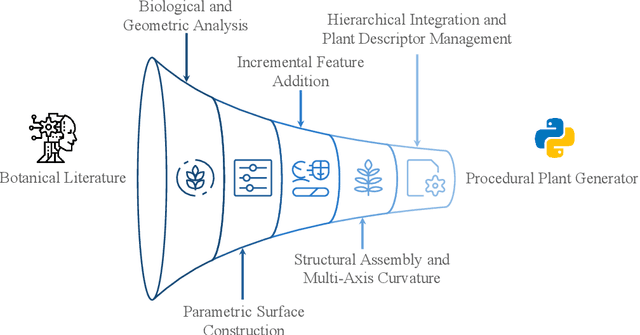
Accurate 3D plant models are crucial for computational phenotyping and physics-based simulation; however, current approaches face significant limitations. Learning-based reconstruction methods require extensive species-specific training data and lack editability. Procedural modeling offers parametric control but demands specialized expertise in geometric modeling and an in-depth understanding of complex procedural rules, making it inaccessible to domain scientists. We present FloraForge, an LLM-assisted framework that enables domain experts to generate biologically accurate, fully parametric 3D plant models through iterative natural language Plant Refinements (PR), minimizing programming expertise. Our framework leverages LLM-enabled co-design to refine Python scripts that generate parameterized plant geometries as hierarchical B-spline surface representations with botanical constraints with explicit control points and parametric deformation functions. This representation can be easily tessellated into polygonal meshes with arbitrary precision, ensuring compatibility with functional structural plant analysis workflows such as light simulation, computational fluid dynamics, and finite element analysis. We demonstrate the framework on maize, soybean, and mung bean, fitting procedural models to empirical point cloud data through manual refinement of the Plant Descriptor (PD), human-readable files. The pipeline generates dual outputs: triangular meshes for visualization and triangular meshes with additional parametric metadata for quantitative analysis. This approach uniquely combines LLM-assisted template creation, mathematically continuous representations enabling both phenotyping and rendering, and direct parametric control through PD. The framework democratizes sophisticated geometric modeling for plant science while maintaining mathematical rigor.
Trustworthy LLM-Mediated Communication: Evaluating Information Fidelity in LLM as a Communicator (LAAC) Framework in Multiple Application Domains
Nov 06, 2025The proliferation of AI-generated content has created an absurd communication theater where senders use LLMs to inflate simple ideas into verbose content, recipients use LLMs to compress them back into summaries, and as a consequence neither party engage with authentic content. LAAC (LLM as a Communicator) proposes a paradigm shift - positioning LLMs as intelligent communication intermediaries that capture the sender's intent through structured dialogue and facilitate genuine knowledge exchange with recipients. Rather than perpetuating cycles of AI-generated inflation and compression, LAAC enables authentic communication across diverse contexts including academic papers, proposals, professional emails, and cross-platform content generation. However, deploying LLMs as trusted communication intermediaries raises critical questions about information fidelity, consistency, and reliability. This position paper systematically evaluates the trustworthiness requirements for LAAC's deployment across multiple communication domains. We investigate three fundamental dimensions: (1) Information Capture Fidelity - accuracy of intent extraction during sender interviews across different communication types, (2) Reproducibility - consistency of structured knowledge across multiple interaction instances, and (3) Query Response Integrity - reliability of recipient-facing responses without hallucination, source conflation, or fabrication. Through controlled experiments spanning multiple LAAC use cases, we assess these trust dimensions using LAAC's multi-agent architecture. Preliminary findings reveal measurable trust gaps that must be addressed before LAAC can be reliably deployed in high-stakes communication scenarios.
ProFusion: 3D Reconstruction of Protein Complex Structures from Multi-view AFM Images
Sep 17, 2025



AI-based in silico methods have improved protein structure prediction but often struggle with large protein complexes (PCs) involving multiple interacting proteins due to missing 3D spatial cues. Experimental techniques like Cryo-EM are accurate but costly and time-consuming. We present ProFusion, a hybrid framework that integrates a deep learning model with Atomic Force Microscopy (AFM), which provides high-resolution height maps from random orientations, naturally yielding multi-view data for 3D reconstruction. However, generating a large-scale AFM imaging data set sufficient to train deep learning models is impractical. Therefore, we developed a virtual AFM framework that simulates the imaging process and generated a dataset of ~542,000 proteins with multi-view synthetic AFM images. We train a conditional diffusion model to synthesize novel views from unposed inputs and an instance-specific Neural Radiance Field (NeRF) model to reconstruct 3D structures. Our reconstructed 3D protein structures achieve an average Chamfer Distance within the AFM imaging resolution, reflecting high structural fidelity. Our method is extensively validated on experimental AFM images of various PCs, demonstrating strong potential for accurate, cost-effective protein complex structure prediction and rapid iterative validation using AFM experiments.
Towards Large Reasoning Models for Agriculture
May 25, 2025Agricultural decision-making involves complex, context-specific reasoning, where choices about crops, practices, and interventions depend heavily on geographic, climatic, and economic conditions. Traditional large language models (LLMs) often fall short in navigating this nuanced problem due to limited reasoning capacity. We hypothesize that recent advances in large reasoning models (LRMs) can better handle such structured, domain-specific inference. To investigate this, we introduce AgReason, the first expert-curated open-ended science benchmark with 100 questions for agricultural reasoning. Evaluations across thirteen open-source and proprietary models reveal that LRMs outperform conventional ones, though notable challenges persist, with the strongest Gemini-based baseline achieving 36% accuracy. We also present AgThoughts, a large-scale dataset of 44.6K question-answer pairs generated with human oversight and equipped with synthetically generated reasoning traces. Using AgThoughts, we develop AgThinker, a suite of small reasoning models that can be run on consumer-grade GPUs, and show that our dataset can be effective in unlocking agricultural reasoning abilities in LLMs. Our project page is here: https://baskargroup.github.io/Ag_reasoning/
NeRF-based Point Cloud Reconstruction using a Stationary Camera for Agricultural Applications
Mar 27, 2025



This paper presents a NeRF-based framework for point cloud (PCD) reconstruction, specifically designed for indoor high-throughput plant phenotyping facilities. Traditional NeRF-based reconstruction methods require cameras to move around stationary objects, but this approach is impractical for high-throughput environments where objects are rapidly imaged while moving on conveyors or rotating pedestals. To address this limitation, we develop a variant of NeRF-based PCD reconstruction that uses a single stationary camera to capture images as the object rotates on a pedestal. Our workflow comprises COLMAP-based pose estimation, a straightforward pose transformation to simulate camera movement, and subsequent standard NeRF training. A defined Region of Interest (ROI) excludes irrelevant scene data, enabling the generation of high-resolution point clouds (10M points). Experimental results demonstrate excellent reconstruction fidelity, with precision-recall analyses yielding an F-score close to 100.00 across all evaluated plant objects. Although pose estimation remains computationally intensive with a stationary camera setup, overall training and reconstruction times are competitive, validating the method's feasibility for practical high-throughput indoor phenotyping applications. Our findings indicate that high-quality NeRF-based 3D reconstructions are achievable using a stationary camera, eliminating the need for complex camera motion or costly imaging equipment. This approach is especially beneficial when employing expensive and delicate instruments, such as hyperspectral cameras, for 3D plant phenotyping. Future work will focus on optimizing pose estimation techniques and further streamlining the methodology to facilitate seamless integration into automated, high-throughput 3D phenotyping pipelines.
3D Neural Operator-Based Flow Surrogates around 3D geometries: Signed Distance Functions and Derivative Constraints
Mar 21, 2025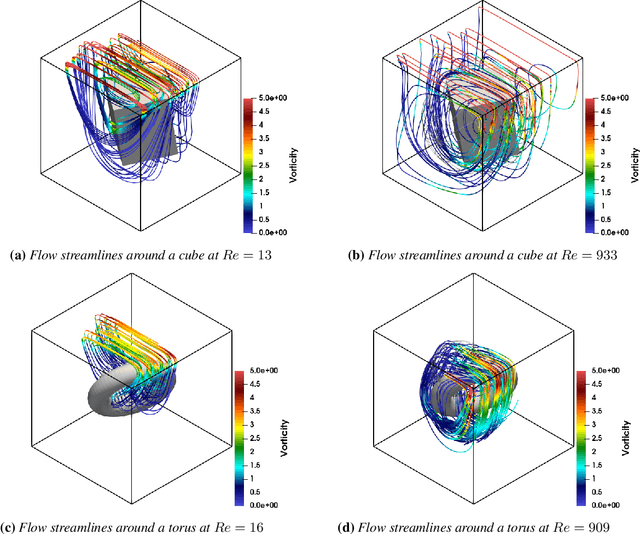
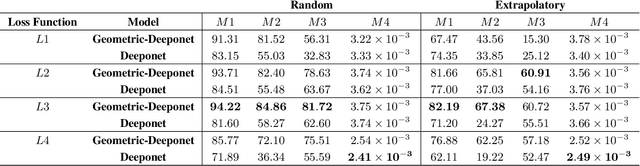
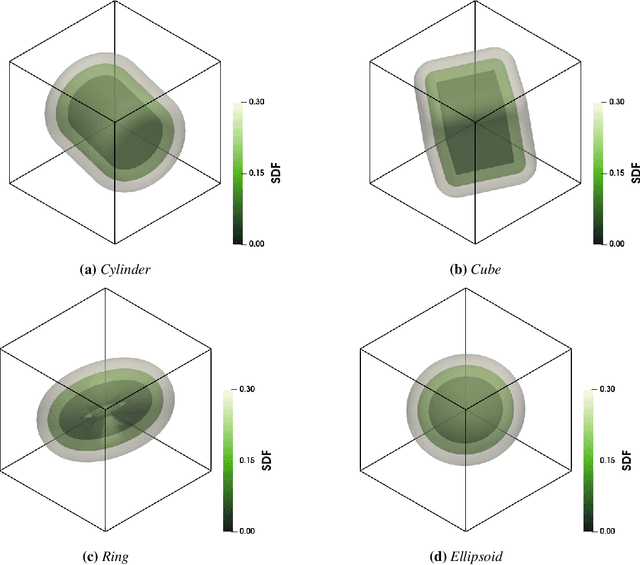
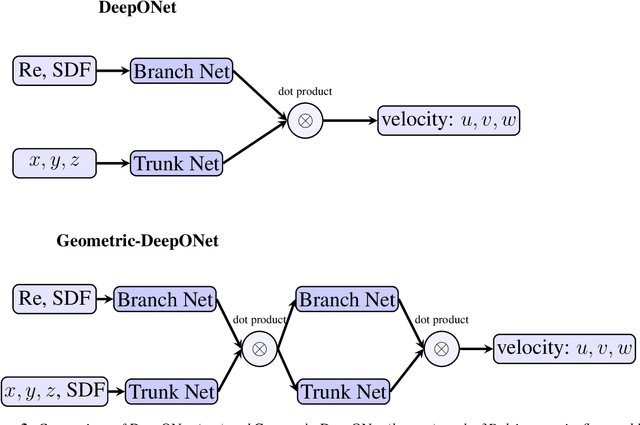
Accurate modeling of fluid dynamics around complex geometries is critical for applications such as aerodynamic optimization and biomedical device design. While advancements in numerical methods and high-performance computing have improved simulation capabilities, the computational cost of high-fidelity 3D flow simulations remains a significant challenge. Scientific machine learning (SciML) offers an efficient alternative, enabling rapid and reliable flow predictions. In this study, we evaluate Deep Operator Networks (DeepONet) and Geometric-DeepONet, a variant that incorporates geometry information via signed distance functions (SDFs), on steady-state 3D flow over complex objects. Our dataset consists of 1,000 high-fidelity simulations spanning Reynolds numbers from 10 to 1,000, enabling comprehensive training and evaluation across a range of flow regimes. To assess model generalization, we test our models on a random and extrapolatory train-test splitting. Additionally, we explore a derivative-informed training strategy that augments standard loss functions with velocity gradient penalties and incompressibility constraints, improving physics consistency in 3D flow prediction. Our results show that Geometric-DeepONet improves boundary-layer accuracy by up to 32% compared to standard DeepONet. Moreover, incorporating derivative constraints enhances gradient accuracy by 25% in interpolation tasks and up to 45% in extrapolatory test scenarios, suggesting significant improvement in generalization capabilities to unseen 3D Reynolds numbers.
Accessing the Effect of Phyllotaxy and Planting Density on Light Use Efficiency in Field-Grown Maize using 3D Reconstructions
Mar 10, 2025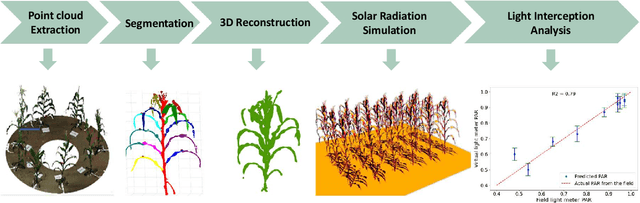
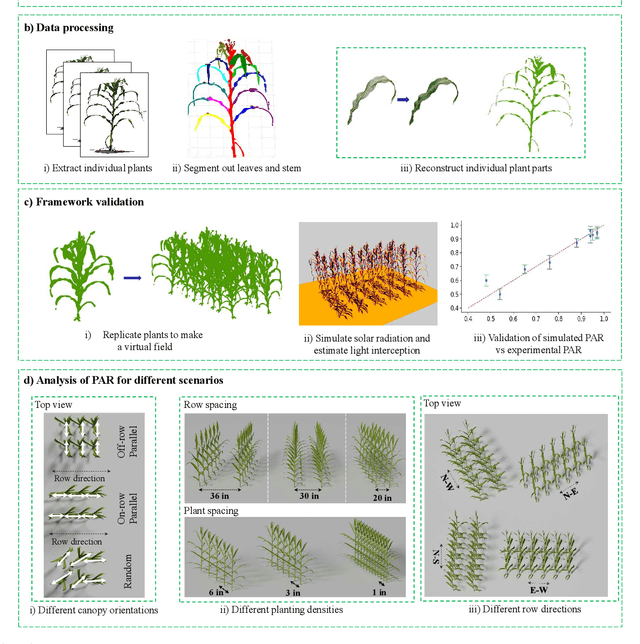
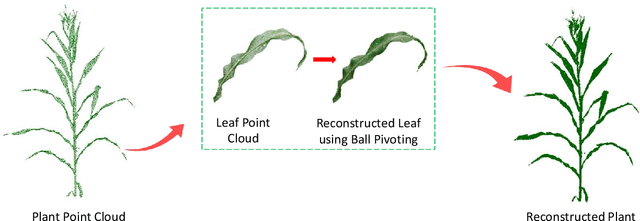
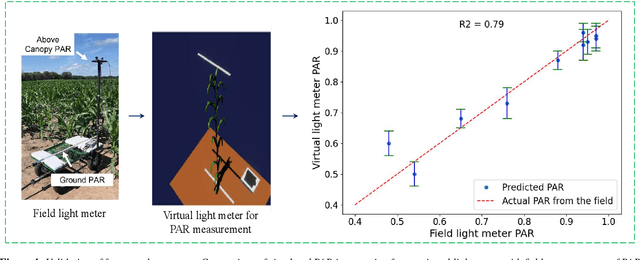
High-density planting is a widely adopted strategy to enhance maize productivity, yet it introduces challenges such as increased interplant competition and shading, which can limit light capture and overall yield potential. In response, some maize plants naturally reorient their canopies to optimize light capture, a process known as canopy reorientation. Understanding this adaptive response and its impact on light capture is crucial for maximizing agricultural yield potential. This study introduces an end-to-end framework that integrates realistic 3D reconstructions of field-grown maize with photosynthetically active radiation (PAR) modeling to assess the effects of phyllotaxy and planting density on light interception. In particular, using 3D point clouds derived from field data, virtual fields for a diverse set of maize genotypes were constructed and validated against field PAR measurements. Using this framework, we present detailed analyses of the impact of canopy orientations, plant and row spacings, and planting row directions on PAR interception throughout a typical growing season. Our findings highlight significant variations in light interception efficiency across different planting densities and canopy orientations. By elucidating the relationship between canopy architecture and light capture, this study offers valuable guidance for optimizing maize breeding and cultivation strategies across diverse agricultural settings.