 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccessing the Effect of Phyllotaxy and Planting Density on Light Use Efficiency in Field-Grown Maize using 3D Reconstructions
Mar 10, 2025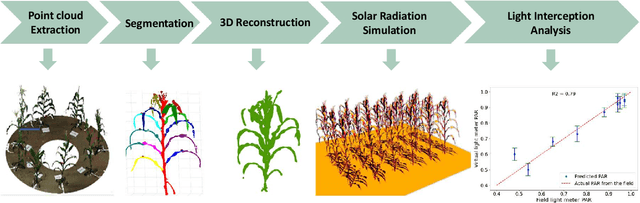
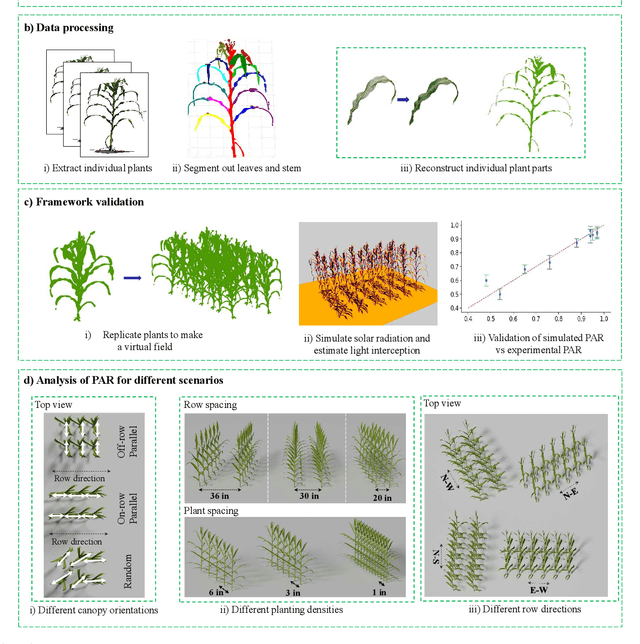
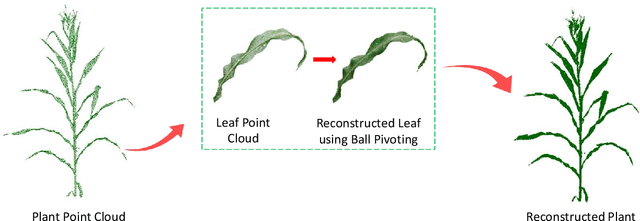
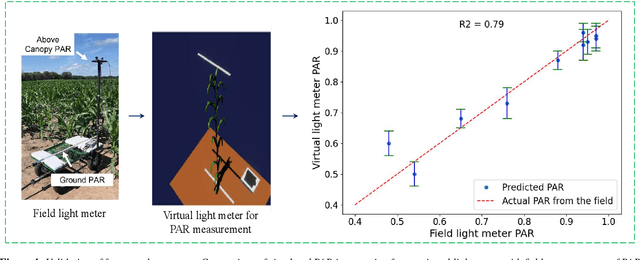
High-density planting is a widely adopted strategy to enhance maize productivity, yet it introduces challenges such as increased interplant competition and shading, which can limit light capture and overall yield potential. In response, some maize plants naturally reorient their canopies to optimize light capture, a process known as canopy reorientation. Understanding this adaptive response and its impact on light capture is crucial for maximizing agricultural yield potential. This study introduces an end-to-end framework that integrates realistic 3D reconstructions of field-grown maize with photosynthetically active radiation (PAR) modeling to assess the effects of phyllotaxy and planting density on light interception. In particular, using 3D point clouds derived from field data, virtual fields for a diverse set of maize genotypes were constructed and validated against field PAR measurements. Using this framework, we present detailed analyses of the impact of canopy orientations, plant and row spacings, and planting row directions on PAR interception throughout a typical growing season. Our findings highlight significant variations in light interception efficiency across different planting densities and canopy orientations. By elucidating the relationship between canopy architecture and light capture, this study offers valuable guidance for optimizing maize breeding and cultivation strategies across diverse agricultural settings.
Class-specific Data Augmentation for Plant Stress Classification
Jun 18, 2024
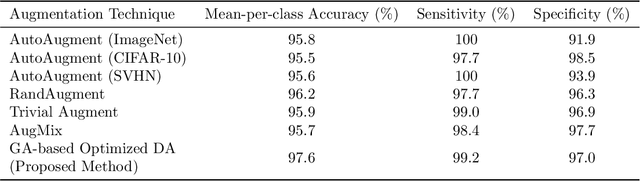
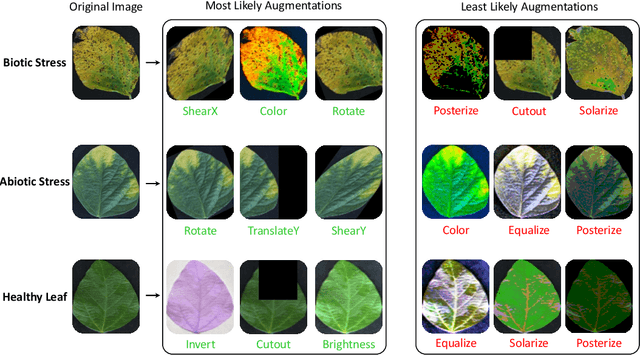

Data augmentation is a powerful tool for improving deep learning-based image classifiers for plant stress identification and classification. However, selecting an effective set of augmentations from a large pool of candidates remains a key challenge, particularly in imbalanced and confounding datasets. We propose an approach for automated class-specific data augmentation using a genetic algorithm. We demonstrate the utility of our approach on soybean [Glycine max (L.) Merr] stress classification where symptoms are observed on leaves; a particularly challenging problem due to confounding classes in the dataset. Our approach yields substantial performance, achieving a mean-per-class accuracy of 97.61% and an overall accuracy of 98% on the soybean leaf stress dataset. Our method significantly improves the accuracy of the most challenging classes, with notable enhancements from 83.01% to 88.89% and from 85.71% to 94.05%, respectively. A key observation we make in this study is that high-performing augmentation strategies can be identified in a computationally efficient manner. We fine-tune only the linear layer of the baseline model with different augmentations, thereby reducing the computational burden associated with training classifiers from scratch for each augmentation policy while achieving exceptional performance. This research represents an advancement in automated data augmentation strategies for plant stress classification, particularly in the context of confounding datasets. Our findings contribute to the growing body of research in tailored augmentation techniques and their potential impact on disease management strategies, crop yields, and global food security. The proposed approach holds the potential to enhance the accuracy and efficiency of deep learning-based tools for managing plant stresses in agriculture.
DIMAT: Decentralized Iterative Merging-And-Training for Deep Learning Models
Apr 11, 2024



Recent advances in decentralized deep learning algorithms have demonstrated cutting-edge performance on various tasks with large pre-trained models. However, a pivotal prerequisite for achieving this level of competitiveness is the significant communication and computation overheads when updating these models, which prohibits the applications of them to real-world scenarios. To address this issue, drawing inspiration from advanced model merging techniques without requiring additional training, we introduce the Decentralized Iterative Merging-And-Training (DIMAT) paradigm--a novel decentralized deep learning framework. Within DIMAT, each agent is trained on their local data and periodically merged with their neighboring agents using advanced model merging techniques like activation matching until convergence is achieved. DIMAT provably converges with the best available rate for nonconvex functions with various first-order methods, while yielding tighter error bounds compared to the popular existing approaches. We conduct a comprehensive empirical analysis to validate DIMAT's superiority over baselines across diverse computer vision tasks sourced from multiple datasets. Empirical results validate our theoretical claims by showing that DIMAT attains faster and higher initial gain in accuracy with independent and identically distributed (IID) and non-IID data, incurring lower communication overhead. This DIMAT paradigm presents a new opportunity for the future decentralized learning, enhancing its adaptability to real-world with sparse and light-weight communication and computation.