 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanLUNA: An Efficient and Robust Query-Unified Multimodal Model for Edge Biosignal Intelligence
Apr 05, 2026Physiological foundation models (FMs) have shown promise for biosignal representation learning, yet most remain confined to a single modality such as EEG, ECG, or PPG, largely because paired multimodal datasets are scarce. In this paper, we present PanLUNA, a compact 5.4M-parameter pan-modal FM that jointly processes EEG, ECG, and PPG within a single shared encoder. Extending LUNA's channel-unification module, PanLUNA treats multimodal channels as entries in a unified query set augmented with sensor-type embeddings, enabling efficient cross-modal early fusion while remaining inherently robust to missing modalities at inference time. Despite its small footprint, PanLUNA matches or exceeds models up to 57$\times$ larger: 81.21% balanced accuracy on TUAB abnormal EEG detection and state-of-the-art 0.7416 balanced accuracy on HMC multimodal sleep staging. Quantization-aware training with INT8 weights recovers $\geq$96% of full-precision performance, and deployment on the GAP9 ultra-low-power RISC-V microcontroller for wearables achieves 325.6 ms latency and 18.8 mJ per 10-second, 12-lead ECG inference, and 1.206 s latency at 68.65 mJ for multimodal 5-channel sleep staging over 30-second epochs.
The Eleventh NTIRE 2026 Efficient Super-Resolution Challenge Report
Apr 03, 2026This paper reviews the NTIRE 2026 challenge on efficient single-image super-resolution with a focus on the proposed solutions and results. The aim of this challenge is to devise a network that reduces one or several aspects, such as runtime, parameters, and FLOPs, while maintaining PSNR of around 26.90 dB on the DIV2K_LSDIR_valid dataset, and 26.99 dB on the DIV2K_LSDIR_test dataset. The challenge had 95 registered participants, and 15 teams made valid submissions. They gauge the state-of-the-art results for efficient single-image super-resolution.
LuMamba: Latent Unified Mamba for Electrode Topology-Invariant and Efficient EEG Modeling
Mar 19, 2026Electroencephalography (EEG) enables non-invasive monitoring of brain activity across clinical and neurotechnology applications, yet building foundation models for EEG remains challenging due to \emph{differing electrode topologies} and \emph{computational scalability}, as Transformer architectures incur quadratic sequence complexity. As a joint solution, we propose \textbf{LuMamba} (\textbf{L}atent \textbf{U}nified \textbf{Mamba}), a self-supervised framework combining topology-invariant encodings with linear-complexity state-space modeling, using LUNA's learned-query cross-attention mechanism for channel unification~\cite{luna}, and FEMBA's bidirectional Mamba blocks for efficient temporal modeling~\cite{femba}. Within this architecture, we provide the first systematic investigation of the Latent-Euclidean Joint-Embedding Predictive Architecture (LeJEPA) for biosignal learning. Pre-trained on over 21,000 hours of unlabeled EEG from the TUEG corpus, LuMamba is evaluated on five downstream tasks spanning abnormality detection, artifact recognition, and mental condition classification across electrode configurations ranging from 16 to 26 channels. In the pre-training objective, masked reconstruction alone yields structured but less generalizable representations, while LeJEPA alone produces diffuse embeddings; combining both objectives achieves the most robust performance. With only 4.6M parameters, LuMamba attains 80.99\% balanced accuracy on TUAB and achieves state-of-art performance on Alzheimer's detection (0.97 AUPR), while requiring \textbf{377$\times$ fewer FLOPS} than state-of-art models at equivalent sequence lengths and scaling to \textbf{12$\times$ longer sequences} before reaching typical GPU memory limits. Code is available at https://github.com/pulp-bio/biofoundation
ATD: Improved Transformer with Adaptive Token Dictionary for Image Restoration
Mar 03, 2026Recently, Transformers have gained significant popularity in image restoration tasks such as image super-resolution and denoising, owing to their superior performance. However, balancing performance and computational burden remains a long-standing problem for transformer-based architectures. Due to the quadratic complexity of self-attention, existing methods often restrict attention to local windows, resulting in limited receptive field and suboptimal performance. To address this issue, we propose Adaptive Token Dictionary (ATD), a novel transformer-based architecture for image restoration that enables global dependency modeling with linear complexity relative to image size. The ATD model incorporates a learnable token dictionary, which summarizes external image priors (i.e., typical image structures) during the training process. To utilize this information, we introduce a token dictionary cross-attention (TDCA) mechanism that enhances the input features via interaction with the learned dictionary. Furthermore, we exploit the category information embedded in the TDCA attention maps to group input features into multiple categories, each representing a cluster of similar features across the image and serving as an attention group. We also integrate the learned category information into the feed-forward network to further improve feature fusion. ATD and its lightweight version ATD-light, achieve state-of-the-art performance on multiple image super-resolution benchmarks. Moreover, we develop ATD-U, a multi-scale variant of ATD, to address other image restoration tasks, including image denoising and JPEG compression artifacts removal. Extensive experiments demonstrate the superiority of out proposed models, both quantitatively and qualitatively.
Robotic Grasping and Placement Controlled by EEG-Based Hybrid Visual and Motor Imagery
Mar 03, 2026We present a framework that integrates EEG-based visual and motor imagery (VI/MI) with robotic control to enable real-time, intention-driven grasping and placement. Motivated by the promise of BCI-driven robotics to enhance human-robot interaction, this system bridges neural signals with physical control by deploying offline-pretrained decoders in a zero-shot manner within an online streaming pipeline. This establishes a dual-channel intent interface that translates visual intent into robotic actions, with VI identifying objects for grasping and MI determining placement poses, enabling intuitive control over both what to grasp and where to place. The system operates solely on EEG via a cue-free imagery protocol, achieving integration and online validation. Implemented on a Base robotic platform and evaluated across diverse scenarios, including occluded targets or varying participant postures, the system achieves online decoding accuracies of 40.23% (VI) and 62.59% (MI), with an end-to-end task success rate of 20.88%. These results demonstrate that high-level visual cognition can be decoded in real time and translated into executable robot commands, bridging the gap between neural signals and physical interaction, and validating the flexibility of a purely imagery-based BCI paradigm for practical human-robot collaboration.
Steering Large Reasoning Models towards Concise Reasoning via Flow Matching
Feb 05, 2026Large Reasoning Models (LRMs) excel at complex reasoning tasks, but their efficiency is often hampered by overly verbose outputs. Prior steering methods attempt to address this issue by applying a single, global vector to hidden representations -- an approach grounded in the restrictive linear representation hypothesis. In this work, we introduce FlowSteer, a nonlinear steering method that goes beyond uniform linear shifts by learning a complete transformation between the distributions associated with verbose and concise reasoning. This transformation is learned via Flow Matching as a velocity field, enabling precise, input-dependent control over the model's reasoning process. By aligning steered representations with the distribution of concise-reasoning activations, FlowSteer yields more compact reasoning than the linear shifts. Across diverse reasoning benchmarks, FlowSteer demonstrates strong task performance and token efficiency compared to leading inference-time baselines. Our work demonstrates that modeling the full distributional transport with generative techniques offers a more effective and principled foundation for controlling LRMs.
Revisiting Adaptive Rounding with Vectorized Reparameterization for LLM Quantization
Feb 02, 2026Adaptive Rounding has emerged as an alternative to round-to-nearest (RTN) for post-training quantization by enabling cross-element error cancellation. Yet, dense and element-wise rounding matrices are prohibitively expensive for billion-parameter large language models (LLMs). We revisit adaptive rounding from an efficiency perspective and propose VQRound, a parameter-efficient optimization framework that reparameterizes the rounding matrix into a compact codebook. Unlike low-rank alternatives, VQRound minimizes the element-wise worst-case error under $L_\infty$ norm, which is critical for handling heavy-tailed weight distributions in LLMs. Beyond reparameterization, we identify rounding initialization as a decisive factor and develop a lightweight end-to-end finetuning pipeline that optimizes codebooks across all layers using only 128 samples. Extensive experiments on OPT, LLaMA, LLaMA2, and Qwen3 models demonstrate that VQRound achieves better convergence than traditional adaptive rounding at the same number of steps while using as little as 0.2% of the trainable parameters. Our results show that adaptive rounding can be made both scalable and fast-fitting. The code is available at https://github.com/zhoustan/VQRound.
Gated Relational Alignment via Confidence-based Distillation for Efficient VLMs
Jan 30, 2026Vision-Language Models (VLMs) achieve strong multimodal performance but are costly to deploy, and post-training quantization often causes significant accuracy loss. Despite its potential, quantization-aware training for VLMs remains underexplored. We propose GRACE, a framework unifying knowledge distillation and QAT under the Information Bottleneck principle: quantization constrains information capacity while distillation guides what to preserve within this budget. Treating the teacher as a proxy for task-relevant information, we introduce confidence-gated decoupled distillation to filter unreliable supervision, relational centered kernel alignment to transfer visual token structures, and an adaptive controller via Lagrangian relaxation to balance fidelity against capacity constraints. Across extensive benchmarks on LLaVA and Qwen families, our INT4 models consistently outperform FP16 baselines (e.g., LLaVA-1.5-7B: 70.1 vs. 66.8 on SQA; Qwen2-VL-2B: 76.9 vs. 72.6 on MMBench), nearly matching teacher performance. Using real INT4 kernel, we achieve 3$\times$ throughput with 54% memory reduction. This principled framework significantly outperforms existing quantization methods, making GRACE a compelling solution for resource-constrained deployment.
Efficient Autoregressive Video Diffusion with Dummy Head
Jan 28, 2026The autoregressive video diffusion model has recently gained considerable research interest due to its causal modeling and iterative denoising. In this work, we identify that the multi-head self-attention in these models under-utilizes historical frames: approximately 25% heads attend almost exclusively to the current frame, and discarding their KV caches incurs only minor performance degradation. Building upon this, we propose Dummy Forcing, a simple yet effective method to control context accessibility across different heads. Specifically, the proposed heterogeneous memory allocation reduces head-wise context redundancy, accompanied by dynamic head programming to adaptively classify head types. Moreover, we develop a context packing technique to achieve more aggressive cache compression. Without additional training, our Dummy Forcing delivers up to 2.0x speedup over the baseline, supporting video generation at 24.3 FPS with less than 0.5% quality drop. Project page is available at https://csguoh.github.io/project/DummyForcing/.
HiM2SAM: Enhancing SAM2 with Hierarchical Motion Estimation and Memory Optimization towards Long-term Tracking
Jul 10, 2025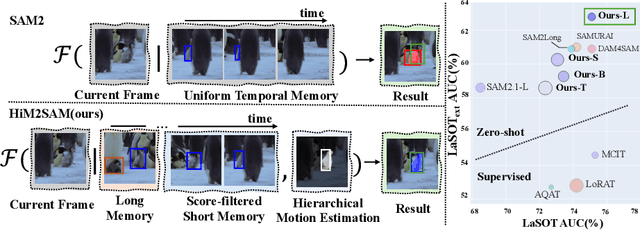
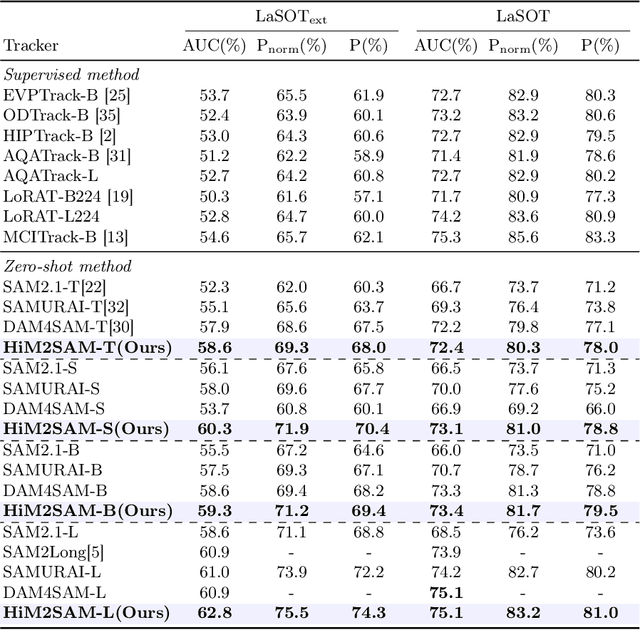
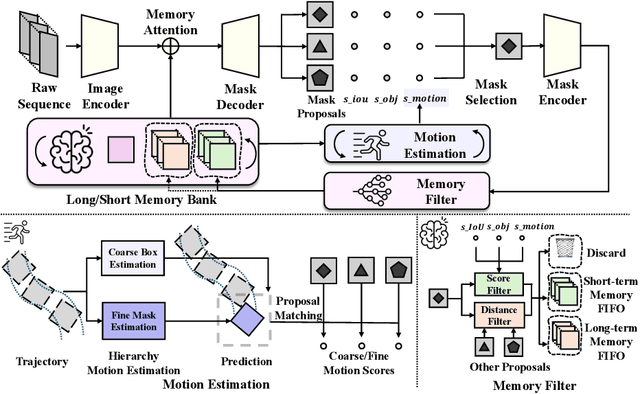
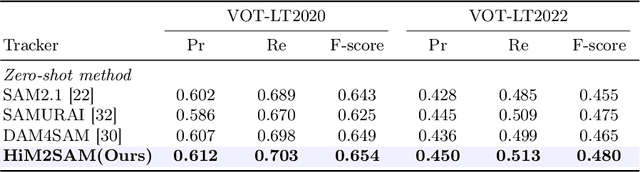
This paper presents enhancements to the SAM2 framework for video object tracking task, addressing challenges such as occlusions, background clutter, and target reappearance. We introduce a hierarchical motion estimation strategy, combining lightweight linear prediction with selective non-linear refinement to improve tracking accuracy without requiring additional training. In addition, we optimize the memory bank by distinguishing long-term and short-term memory frames, enabling more reliable tracking under long-term occlusions and appearance changes. Experimental results show consistent improvements across different model scales. Our method achieves state-of-the-art performance on LaSOT and LaSOText with the large model, achieving 9.6% and 7.2% relative improvements in AUC over the original SAM2, and demonstrates even larger relative gains on smaller models, highlighting the effectiveness of our trainless, low-overhead improvements for boosting long-term tracking performance. The code is available at https://github.com/LouisFinner/HiM2SAM.