 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHPO: Hysteretic Policy Optimization for Stable and Efficient Training under Sparse-Reward Regime
May 28, 2026We investigate a narrow but common failure mode of GRPO-style reinforcement learning in the context of sparse verifiable rewards: early updates contain more responses with negative advantages than those with positive advantages, while response-level length normalization ties the magnitude of the update to the length of the output. We propose Hysteretic Policy Optimization (HPO), a minimal modification of GRPO that reduces the weight of negative-advantage updates and replaces per-response length normalization with mean-length normalization. We further introduce Adaptive HPO (A-HPO), which sets the hysteretic weight based on batch-level advantage-sign statistics, thereby removing the need for tuning a fixed hysteretic weight. In our TeleLogs and Countdown experiments, A-HPO improves the reward per update compared to GRPO, with the largest gains in early sparse reward regimes. On TeleLogs, A-HPO achieves a final reward of 0.84, outperforming SAPO by 5%, GSPO by 11%, and GRPO by 15%, while maintaining a comparable response-length. On Countdown, A-HPO achieves the largest gains in initial and most difficult configurations across 1.5B-7B models. Ablation studies on the hysteretic weight show that the gains of A-HPO come from better balancing the contributions of positive and negative advantages compared to positive-only or fully symmetric updates.
BenchCAD: A Comprehensive, Industry-Standard Benchmark for Programmatic CAD
May 11, 2026Industrial Computer-Aided Design (CAD) code generation requires models to produce executable parametric programs from visual or textual inputs. Beyond recognizing the outer shape of a part, this task involves understanding its 3D structure, inferring engineering parameters, and choosing CAD operations that reflect how the part would be designed and manufactured. Despite the promise of Multimodal large language models (MLLMs) for this task, they are rarely evaluated on whether these capabilities jointly hold in realistic industrial CAD settings. We present BenchCAD, a unified benchmark for industrial CAD reasoning. BenchCAD contains 17,900 execution-verified CadQuery programs across 106 industrial part families, including bevel gears, compression springs, twist drills, and other reusable engineering designs. It evaluates models through visual question answering, code question answering, image-to-code generation, and instruction-guided code editing, enabling fine-grained analysis across perception, parametric abstraction, and executable program synthesis. Across 10+ frontier models, BenchCAD shows that current systems often recover coarse outer geometry but fail to produce faithful parametric CAD programs. Common failures include missing fine 3D structure, misinterpreting industrial design parameters, and replacing essential operations such as sweeps, lofts, and twist-extrudes with simpler sketch-and-extrude patterns. Fine-tuning and reinforcement learning improve in-distribution performance, but generalization to unseen part families remains limited. These results position BenchCAD as a benchmark for measuring and improving the industrial readiness of multimodal CAD automation.
UniDex: A Robot Foundation Suite for Universal Dexterous Hand Control from Egocentric Human Videos
Mar 23, 2026Dexterous manipulation remains challenging due to the cost of collecting real-robot teleoperation data, the heterogeneity of hand embodiments, and the high dimensionality of control. We present UniDex, a robot foundation suite that couples a large-scale robot-centric dataset with a unified vision-language-action (VLA) policy and a practical human-data capture setup for universal dexterous hand control. First, we construct UniDex-Dataset, a robot-centric dataset over 50K trajectories across eight dexterous hands (6--24 DoFs), derived from egocentric human video datasets. To transform human data into robot-executable trajectories, we employ a human-in-the-loop retargeting procedure to align fingertip trajectories while preserving plausible hand-object contacts, and we operate on explicit 3D pointclouds with human hands masked to narrow kinematic and visual gaps. Second, we introduce the Function-Actuator-Aligned Space (FAAS), a unified action space that maps functionally similar actuators to shared coordinates, enabling cross-hand transfer. Leveraging FAAS as the action parameterization, we train UniDex-VLA, a 3D VLA policy pretrained on UniDex-Dataset and finetuned with task demonstrations. In addition, we build UniDex-Cap, a simple portable capture setup that records synchronized RGB-D streams and human hand poses and converts them into robot-executable trajectories to enable human-robot data co-training that reduces reliance on costly robot demonstrations. On challenging tool-use tasks across two different hands, UniDex-VLA achieves 81% average task progress and outperforms prior VLA baselines by a large margin, while exhibiting strong spatial, object, and zero-shot cross-hand generalization. Together, UniDex-Dataset, UniDex-VLA, and UniDex-Cap provide a scalable foundation suite for universal dexterous manipulation.
Learning by Imagining: Debiased Feature Augmentation for Compositional Zero-Shot Learning
Sep 16, 2025Compositional Zero-Shot Learning (CZSL) aims to recognize unseen attribute-object compositions by learning prior knowledge of seen primitives, \textit{i.e.}, attributes and objects. Learning generalizable compositional representations in CZSL remains challenging due to the entangled nature of attributes and objects as well as the prevalence of long-tailed distributions in real-world data. Inspired by neuroscientific findings that imagination and perception share similar neural processes, we propose a novel approach called Debiased Feature Augmentation (DeFA) to address these challenges. The proposed DeFA integrates a disentangle-and-reconstruct framework for feature augmentation with a debiasing strategy. DeFA explicitly leverages the prior knowledge of seen attributes and objects by synthesizing high-fidelity composition features to support compositional generalization. Extensive experiments on three widely used datasets demonstrate that DeFA achieves state-of-the-art performance in both \textit{closed-world} and \textit{open-world} settings.
Reasoning Language Models for Root Cause Analysis in 5G Wireless Networks
Jul 29, 2025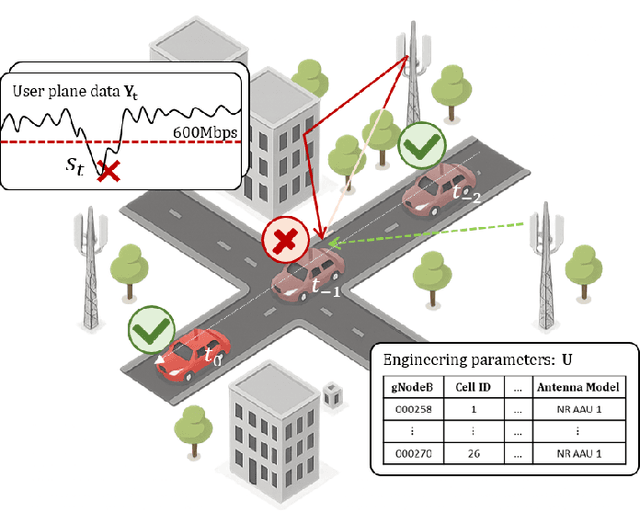
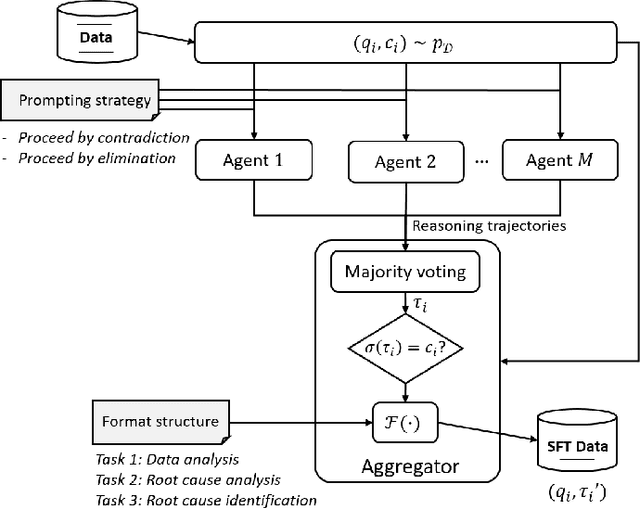

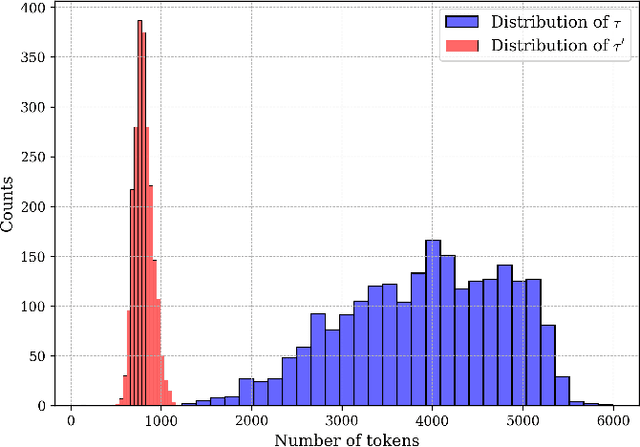
Root Cause Analysis (RCA) in mobile networks remains a challenging task due to the need for interpretability, domain expertise, and causal reasoning. In this work, we propose a lightweight framework that leverages Large Language Models (LLMs) for RCA. To do so, we introduce TeleLogs, a curated dataset of annotated troubleshooting problems designed to benchmark RCA capabilities. Our evaluation reveals that existing open-source reasoning LLMs struggle with these problems, underscoring the need for domain-specific adaptation. To address this issue, we propose a two-stage training methodology that combines supervised fine-tuning with reinforcement learning to improve the accuracy and reasoning quality of LLMs. The proposed approach fine-tunes a series of RCA models to integrate domain knowledge and generate structured, multi-step diagnostic explanations, improving both interpretability and effectiveness. Extensive experiments across multiple LLM sizes show significant performance gains over state-of-the-art reasoning and non-reasoning models, including strong generalization to randomized test variants. These results demonstrate the promise of domain-adapted, reasoning-enhanced LLMs for practical and explainable RCA in network operation and management.
MiniMax-Speech: Intrinsic Zero-Shot Text-to-Speech with a Learnable Speaker Encoder
May 12, 2025We introduce MiniMax-Speech, an autoregressive Transformer-based Text-to-Speech (TTS) model that generates high-quality speech. A key innovation is our learnable speaker encoder, which extracts timbre features from a reference audio without requiring its transcription. This enables MiniMax-Speech to produce highly expressive speech with timbre consistent with the reference in a zero-shot manner, while also supporting one-shot voice cloning with exceptionally high similarity to the reference voice. In addition, the overall quality of the synthesized audio is enhanced through the proposed Flow-VAE. Our model supports 32 languages and demonstrates excellent performance across multiple objective and subjective evaluations metrics. Notably, it achieves state-of-the-art (SOTA) results on objective voice cloning metrics (Word Error Rate and Speaker Similarity) and has secured the top position on the public TTS Arena leaderboard. Another key strength of MiniMax-Speech, granted by the robust and disentangled representations from the speaker encoder, is its extensibility without modifying the base model, enabling various applications such as: arbitrary voice emotion control via LoRA; text to voice (T2V) by synthesizing timbre features directly from text description; and professional voice cloning (PVC) by fine-tuning timbre features with additional data. We encourage readers to visit https://minimax-ai.github.io/tts_tech_report for more examples.
MMT-Bench: A Comprehensive Multimodal Benchmark for Evaluating Large Vision-Language Models Towards Multitask AGI
Apr 24, 2024



Large Vision-Language Models (LVLMs) show significant strides in general-purpose multimodal applications such as visual dialogue and embodied navigation. However, existing multimodal evaluation benchmarks cover a limited number of multimodal tasks testing rudimentary capabilities, falling short in tracking LVLM development. In this study, we present MMT-Bench, a comprehensive benchmark designed to assess LVLMs across massive multimodal tasks requiring expert knowledge and deliberate visual recognition, localization, reasoning, and planning. MMT-Bench comprises $31,325$ meticulously curated multi-choice visual questions from various multimodal scenarios such as vehicle driving and embodied navigation, covering $32$ core meta-tasks and $162$ subtasks in multimodal understanding. Due to its extensive task coverage, MMT-Bench enables the evaluation of LVLMs using a task map, facilitating the discovery of in- and out-of-domain tasks. Evaluation results involving $30$ LVLMs such as the proprietary GPT-4V, GeminiProVision, and open-sourced InternVL-Chat, underscore the significant challenges posed by MMT-Bench. We anticipate that MMT-Bench will inspire the community to develop next-generation multimodal foundation models aimed at achieving general-purpose multimodal intelligence.
Building Bilingual and Code-Switched Voice Conversion with Limited Training Data Using Embedding Consistency Loss
Apr 22, 2021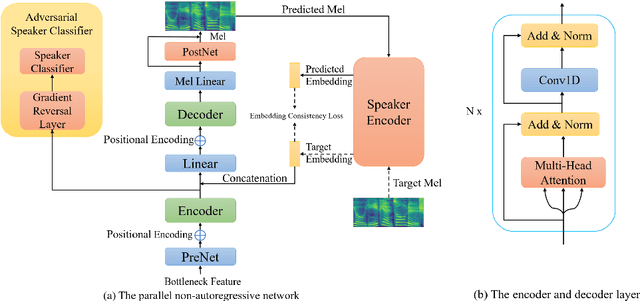

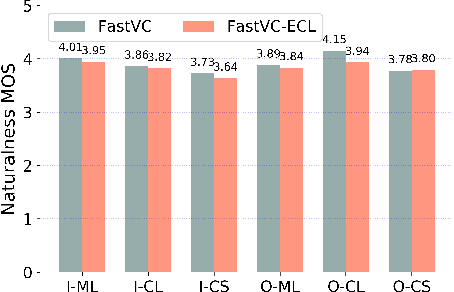
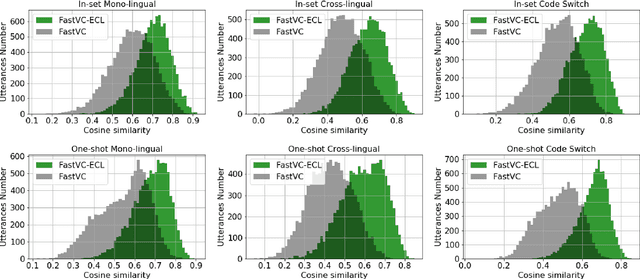
Building cross-lingual voice conversion (VC) systems for multiple speakers and multiple languages has been a challenging task for a long time. This paper describes a parallel non-autoregressive network to achieve bilingual and code-switched voice conversion for multiple speakers when there are only mono-lingual corpora for each language. We achieve cross-lingual VC between Mandarin speech with multiple speakers and English speech with multiple speakers by applying bilingual bottleneck features. To boost voice cloning performance, we use an adversarial speaker classifier with a gradient reversal layer to reduce the source speaker's information from the output of encoder. Furthermore, in order to improve speaker similarity between reference speech and converted speech, we adopt an embedding consistency loss between the synthesized speech and its natural reference speech in our network. Experimental results show that our proposed method can achieve high quality converted speech with mean opinion score (MOS) around 4. The conversion system performs well in terms of speaker similarity for both in-set speaker conversion and out-set-of one-shot conversion.
Regression-Enhanced Random Forests
Apr 23, 2019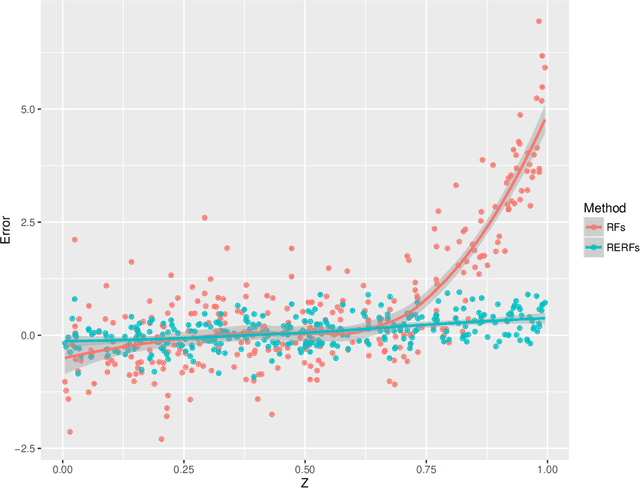

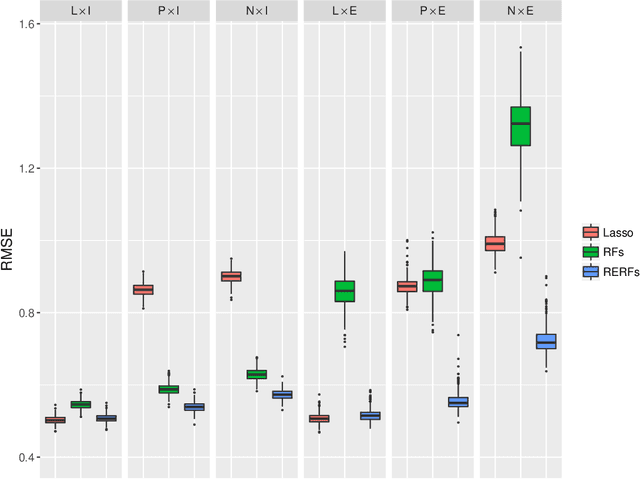
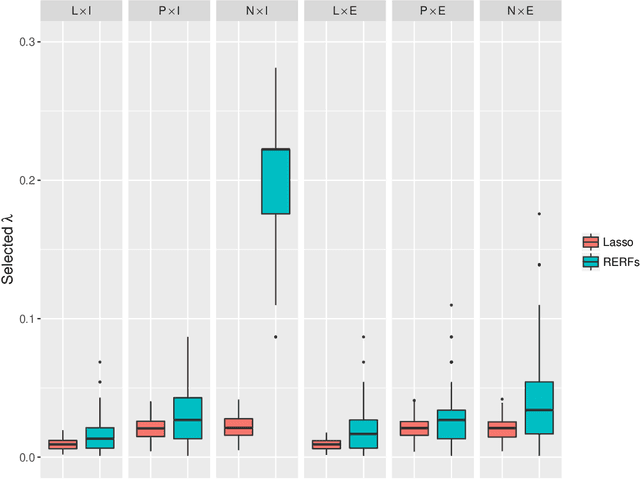
Random forest (RF) methodology is one of the most popular machine learning techniques for prediction problems. In this article, we discuss some cases where random forests may suffer and propose a novel generalized RF method, namely regression-enhanced random forests (RERFs), that can improve on RFs by borrowing the strength of penalized parametric regression. The algorithm for constructing RERFs and selecting its tuning parameters is described. Both simulation study and real data examples show that RERFs have better predictive performance than RFs in important situations often encountered in practice. Moreover, RERFs may incorporate known relationships between the response and the predictors, and may give reliable predictions in extrapolation problems where predictions are required at points out of the domain of the training dataset. Strategies analogous to those described here can be used to improve other machine learning methods via combination with penalized parametric regression techniques.
* 12 pages, 5 figures