 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Bilingual and Code-Switched Voice Conversion with Limited Training Data Using Embedding Consistency Loss
Apr 22, 2021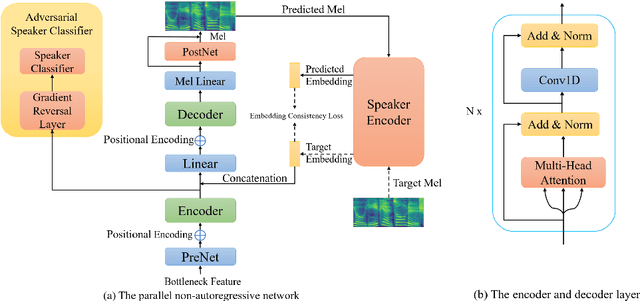

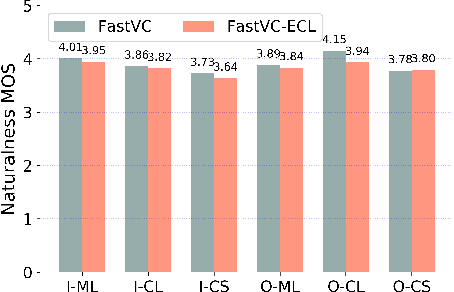
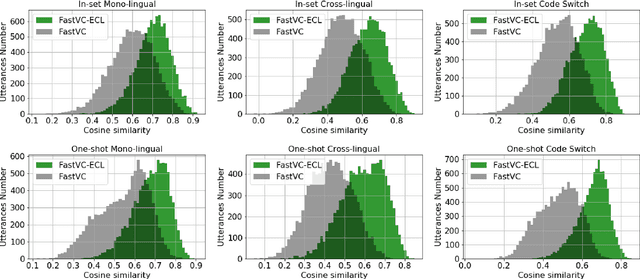
Building cross-lingual voice conversion (VC) systems for multiple speakers and multiple languages has been a challenging task for a long time. This paper describes a parallel non-autoregressive network to achieve bilingual and code-switched voice conversion for multiple speakers when there are only mono-lingual corpora for each language. We achieve cross-lingual VC between Mandarin speech with multiple speakers and English speech with multiple speakers by applying bilingual bottleneck features. To boost voice cloning performance, we use an adversarial speaker classifier with a gradient reversal layer to reduce the source speaker's information from the output of encoder. Furthermore, in order to improve speaker similarity between reference speech and converted speech, we adopt an embedding consistency loss between the synthesized speech and its natural reference speech in our network. Experimental results show that our proposed method can achieve high quality converted speech with mean opinion score (MOS) around 4. The conversion system performs well in terms of speaker similarity for both in-set speaker conversion and out-set-of one-shot conversion.
Cross-lingual Multispeaker Text-to-Speech under Limited-Data Scenario
May 21, 2020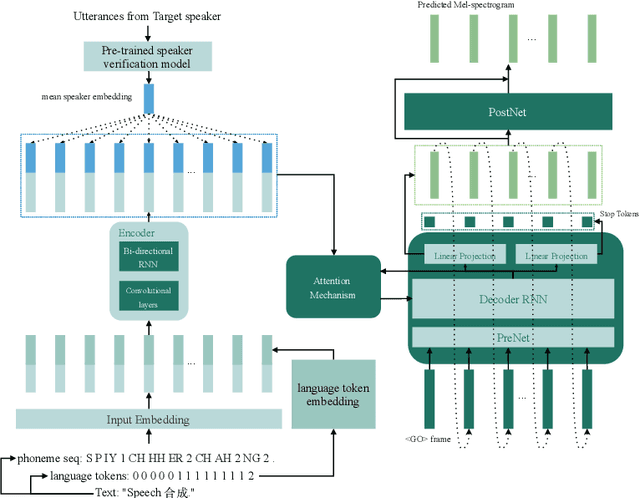


Modeling voices for multiple speakers and multiple languages in one text-to-speech system has been a challenge for a long time. This paper presents an extension on Tacotron2 to achieve bilingual multispeaker speech synthesis when there are limited data for each language. We achieve cross-lingual synthesis, including code-switching cases, between English and Mandarin for monolingual speakers. The two languages share the same phonemic representations for input, while the language attribute and the speaker identity are independently controlled by language tokens and speaker embeddings, respectively. In addition, we investigate the model's performance on the cross-lingual synthesis, with and without a bilingual dataset during training. With the bilingual dataset, not only can the model generate high-fidelity speech for all speakers concerning the language they speak, but also can generate accented, yet fluent and intelligible speech for monolingual speakers regarding non-native language. For example, the Mandarin speaker can speak English fluently. Furthermore, the model trained with bilingual dataset is robust for code-switching text-to-speech, as shown in our results and provided samples.{https://caizexin.github.io/mlms-syn-samples/index.html}.
Polyphone Disambiguation for Mandarin Chinese Using Conditional Neural Network with Multi-level Embedding Features
Jul 03, 2019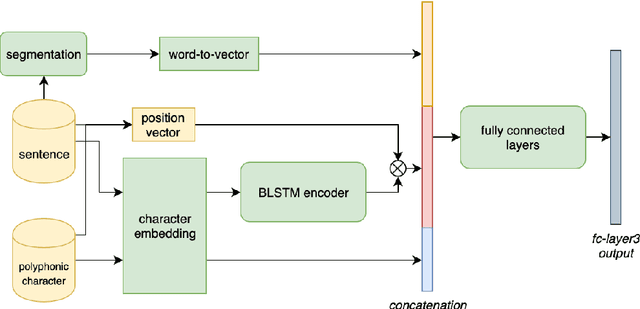
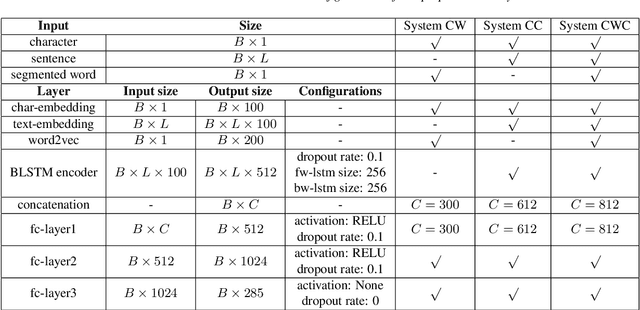
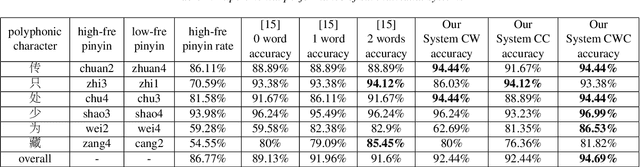
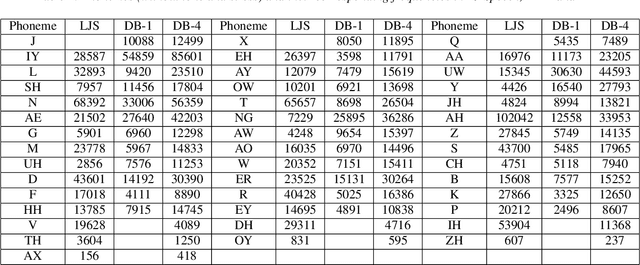
This paper describes a conditional neural network architecture for Mandarin Chinese polyphone disambiguation. The system is composed of a bidirectional recurrent neural network component acting as a sentence encoder to accumulate the context correlations, followed by a prediction network that maps the polyphonic character embeddings along with the conditions to corresponding pronunciations. We obtain the word-level condition from a pre-trained word-to-vector lookup table. One goal of polyphone disambiguation is to address the homograph problem existing in the front-end processing of Mandarin Chinese text-to-speech system. Our system achieves an accuracy of 94.69\% on a publicly available polyphonic character dataset. To further validate our choices on the conditional feature, we investigate polyphone disambiguation systems with multi-level conditions respectively. The experimental results show that both the sentence-level and the word-level conditional embedding features are able to attain good performance for Mandarin Chinese polyphone disambiguation.