 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuddle-Fish: Exploring a Soft Floating Robot with Flapping Wings for Physical Interactions
Apr 02, 2025
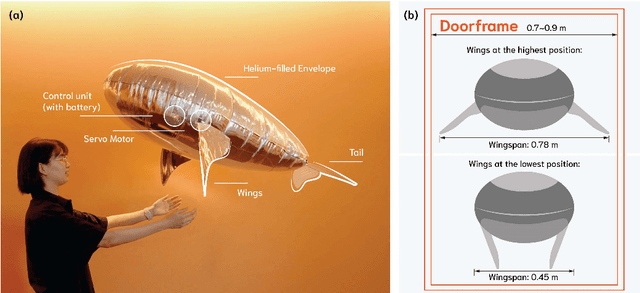

Flying robots, such as quadrotor drones, offer new possibilities for human-robot interaction but often pose safety risks due to fast-spinning propellers, rigid structures, and noise. In contrast, lighter-than-air flapping-wing robots, inspired by animal movement, offer a soft, quiet, and touch-safe alternative. Building on these advantages, we present \textit{Cuddle-Fish}, a soft, flapping-wing floating robot designed for safe, close-proximity interactions in indoor spaces. Through a user study with 24 participants, we explored their perceptions of the robot and experiences during a series of co-located demonstrations in which the robot moved near them. Results showed that participants felt safe, willingly engaged in touch-based interactions with the robot, and exhibited spontaneous affective behaviours, such as patting, stroking, hugging, and cheek-touching, without external prompting. They also reported positive emotional responses towards the robot. These findings suggest that the soft floating robot with flapping wings can serve as a novel and socially acceptable alternative to traditional rigid flying robots, opening new possibilities for companionship, play, and interactive experiences in everyday indoor environments.
Learning How To Ask: Cycle-Consistency Refines Prompts in Multimodal Foundation Models
Feb 13, 2024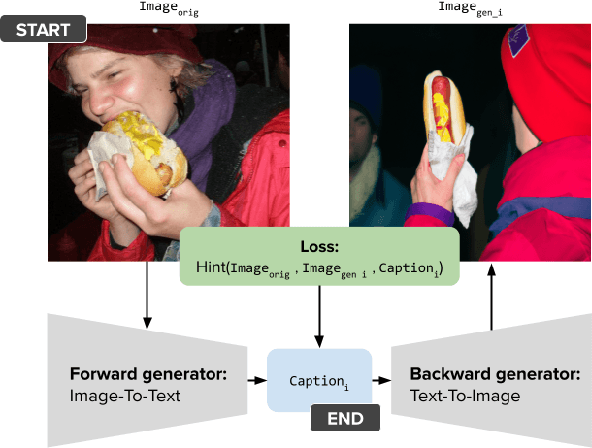

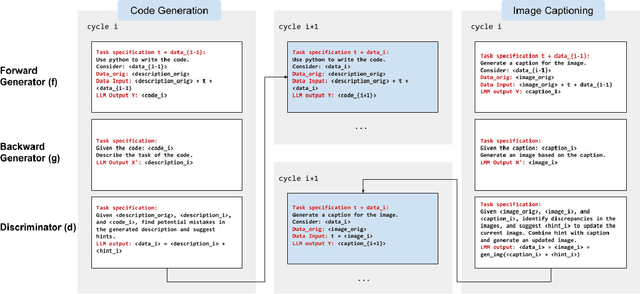

When LLMs perform zero-shot inference, they typically use a prompt with a task specification, and generate a completion. However, there is no work to explore the possibility of the reverse - going from completion to task specification. In this paper, we employ both directions to perform cycle-supervised learning entirely in-context. Our goal is to create a forward map f : X -> Y (e.g. image -> generated caption), coupled with a backward map g : Y -> X (e.g. caption -> generated image) to construct a cycle-consistency "loss" (formulated as an update to the prompt) to enforce g(f(X)) ~= X. The technique, called CyclePrompt, uses cycle-consistency as a free supervisory signal to iteratively craft the prompt. Importantly, CyclePrompt reinforces model performance without expensive fine-tuning, without training data, and without the complexity of external environments (e.g. compilers, APIs). We demonstrate CyclePrompt in two domains: code generation and image captioning. Our results on the HumanEval coding benchmark put us in first place on the leaderboard among models that do not rely on extra training data or usage of external environments, and third overall. Compared to the GPT4 baseline, we improve accuracy from 80.5% to 87.2%. In the vision-language space, we generate detailed image captions which outperform baseline zero-shot GPT4V captions, when tested against natural (VQAv2) and diagrammatic (FigureQA) visual question-answering benchmarks. To the best of our knowledge, this is the first use of self-supervised learning for prompting.
Multi-User Chat Assistant : a Framework Using LLMs to Facilitate Group Conversations
Jan 10, 2024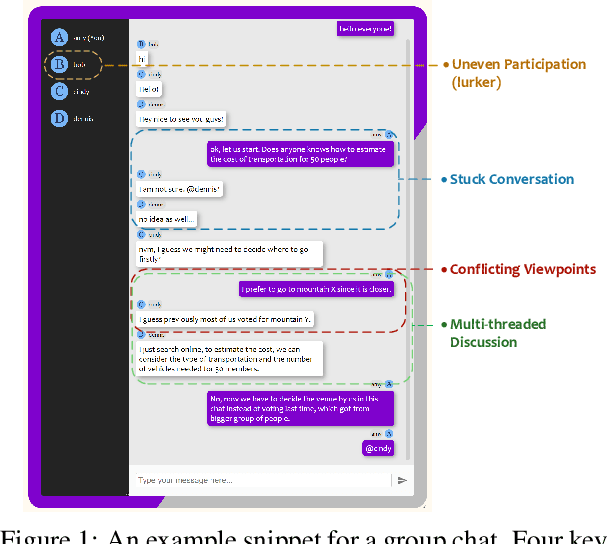
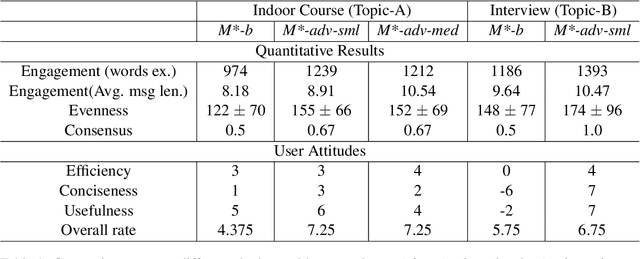
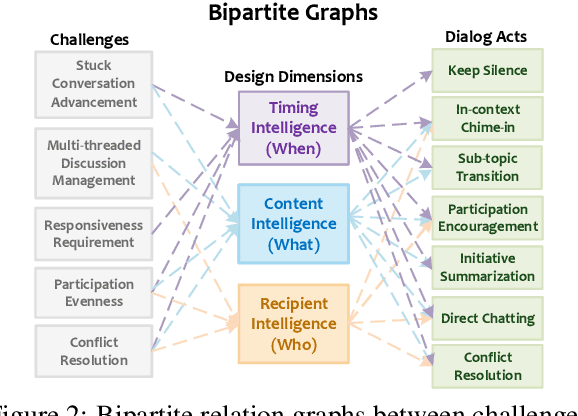
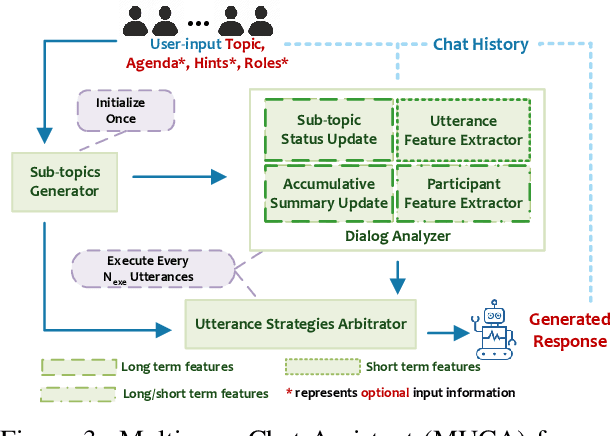
Recent advancements in large language models (LLMs) have provided a new avenue for chatbot development, while most existing research has primarily centered on single-user chatbots that focus on deciding "What" to answer after user inputs. In this paper, we identified that multi-user chatbots have more complex 3W design dimensions -- "What" to say, "When" to respond, and "Who" to answer. Additionally, we proposed Multi-User Chat Assistant (MUCA), which is an LLM-based framework for chatbots specifically designed for group discussions. MUCA consists of three main modules: Sub-topic Generator, Dialog Analyzer, and Utterance Strategies Arbitrator. These modules jointly determine suitable response contents, timings, and the appropriate recipients. To make the optimizing process for MUCA easier, we further propose an LLM-based Multi-User Simulator (MUS) that can mimic real user behavior. This enables faster simulation of a conversation between the chatbot and simulated users, making the early development of the chatbot framework much more efficient. MUCA demonstrates effectiveness, including appropriate chime-in timing, relevant content, and positive user engagement, in goal-oriented conversations with a small to medium number of participants, as evidenced by case studies and experimental results from user studies.
Building Bilingual and Code-Switched Voice Conversion with Limited Training Data Using Embedding Consistency Loss
Apr 22, 2021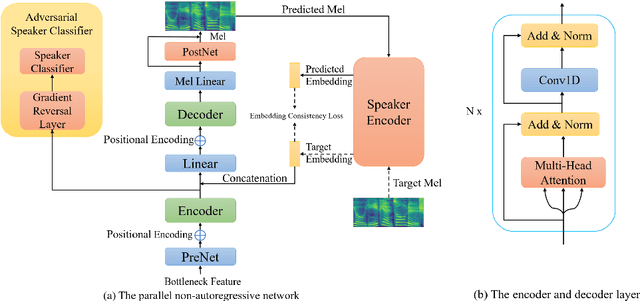

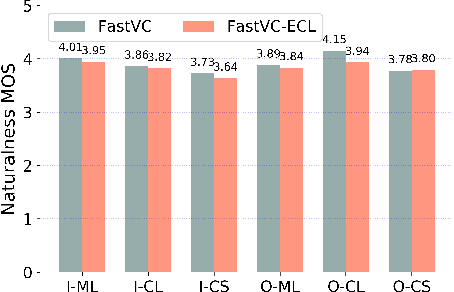
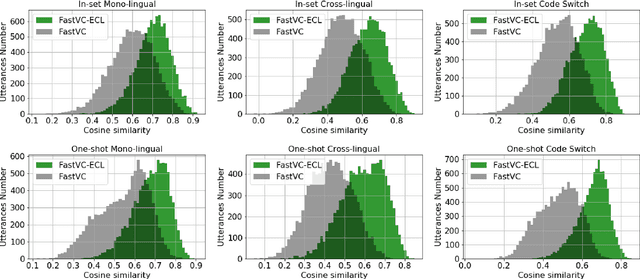
Building cross-lingual voice conversion (VC) systems for multiple speakers and multiple languages has been a challenging task for a long time. This paper describes a parallel non-autoregressive network to achieve bilingual and code-switched voice conversion for multiple speakers when there are only mono-lingual corpora for each language. We achieve cross-lingual VC between Mandarin speech with multiple speakers and English speech with multiple speakers by applying bilingual bottleneck features. To boost voice cloning performance, we use an adversarial speaker classifier with a gradient reversal layer to reduce the source speaker's information from the output of encoder. Furthermore, in order to improve speaker similarity between reference speech and converted speech, we adopt an embedding consistency loss between the synthesized speech and its natural reference speech in our network. Experimental results show that our proposed method can achieve high quality converted speech with mean opinion score (MOS) around 4. The conversion system performs well in terms of speaker similarity for both in-set speaker conversion and out-set-of one-shot conversion.