 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Good Verifiers Go Bad: Self-Improving VLMs Can Regress on New Tasks
Jun 12, 2026Verifier-driven self-DPO is a common recipe for self-improving production visual-language models. In this setup, a frozen verifier scores candidate generations, the top- and bottom-scoring candidates form a preference example, and DPO updates the learner. The deployment-time assumption is monotone: a stronger verifier should yield a stronger student. We show that this assumption can fail because verifier quality is highly task-specific. On a four-rung open-source verifier ladder across MathVista, MMMU, and BLINK, the same verifiers that are above-threshold and improve a Qwen-3-VL-2B student on MathVista become sub-threshold on MMMU, where their task-rubric accuracy drops to 8% to 23%. In this regime, every verifier we tested silently regresses the student, producing drops of 3.4 to 10.9 percentage points below the frozen baseline while the DPO training loss continues to decrease. The regression replicates on a second student, Qwen-2.5-VL-3B. Moreover, within the failure regime, damage is confidence-inverted: the more accurate-but-still-wrong verifier causes larger regression than a near-random verifier, suggesting that progress-gated replay amplifies confidently wrong preference pairs. We give a compact mechanistic explanation via a variance theorem for progress-gated replay and its direction-mismatch failure mode. The deployment message is operational rather than purely diagnostic: before running any verifier-driven loop, teams should measure target-task rubric accuracy, rank verifiers by target-task rubric quality rather than parameter count, and treat diminishing returns in above-threshold regimes as a verifier-side compute budget cap.
Learning How To Ask: Cycle-Consistency Refines Prompts in Multimodal Foundation Models
Feb 13, 2024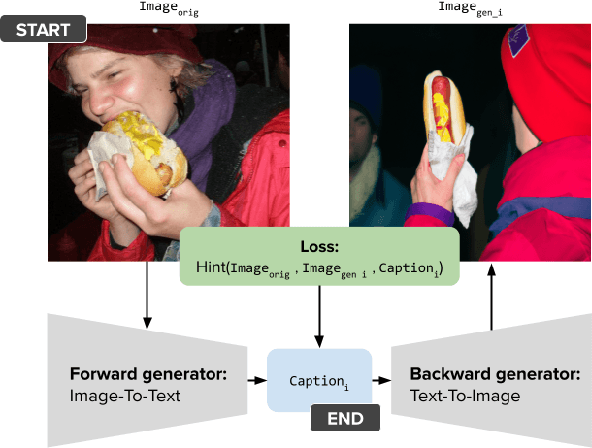

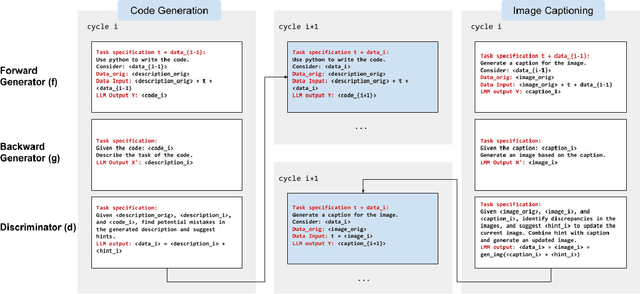

When LLMs perform zero-shot inference, they typically use a prompt with a task specification, and generate a completion. However, there is no work to explore the possibility of the reverse - going from completion to task specification. In this paper, we employ both directions to perform cycle-supervised learning entirely in-context. Our goal is to create a forward map f : X -> Y (e.g. image -> generated caption), coupled with a backward map g : Y -> X (e.g. caption -> generated image) to construct a cycle-consistency "loss" (formulated as an update to the prompt) to enforce g(f(X)) ~= X. The technique, called CyclePrompt, uses cycle-consistency as a free supervisory signal to iteratively craft the prompt. Importantly, CyclePrompt reinforces model performance without expensive fine-tuning, without training data, and without the complexity of external environments (e.g. compilers, APIs). We demonstrate CyclePrompt in two domains: code generation and image captioning. Our results on the HumanEval coding benchmark put us in first place on the leaderboard among models that do not rely on extra training data or usage of external environments, and third overall. Compared to the GPT4 baseline, we improve accuracy from 80.5% to 87.2%. In the vision-language space, we generate detailed image captions which outperform baseline zero-shot GPT4V captions, when tested against natural (VQAv2) and diagrammatic (FigureQA) visual question-answering benchmarks. To the best of our knowledge, this is the first use of self-supervised learning for prompting.
Multi-User Chat Assistant : a Framework Using LLMs to Facilitate Group Conversations
Jan 10, 2024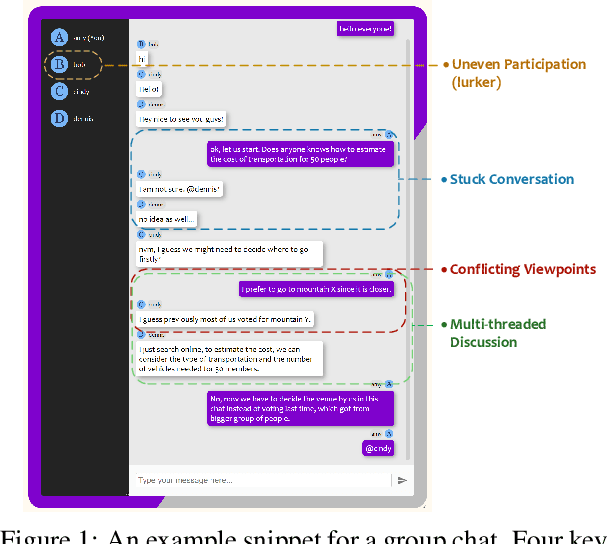
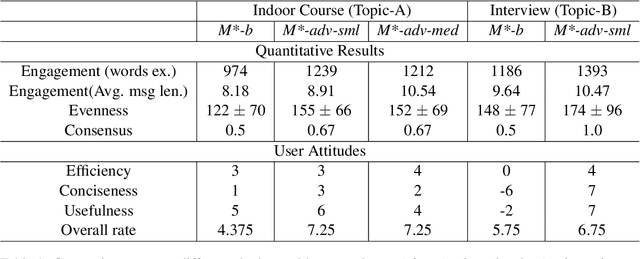
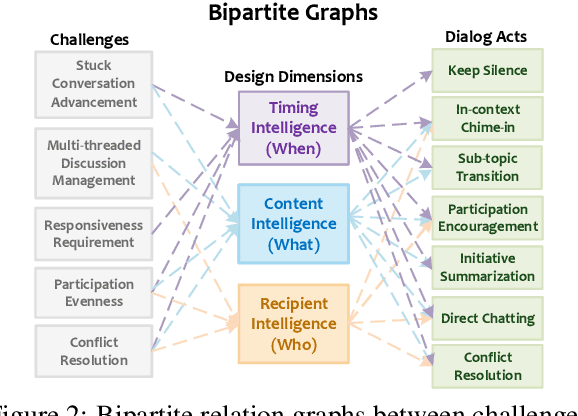
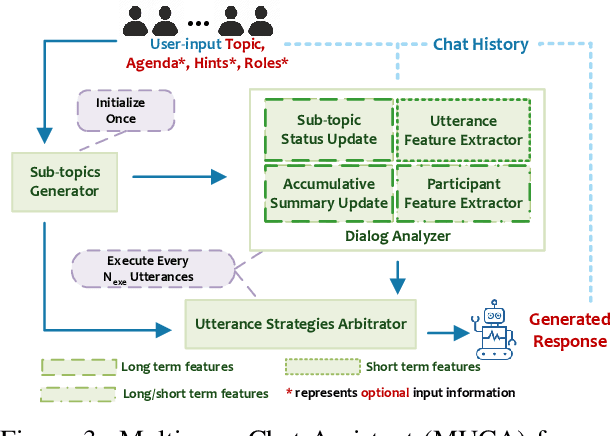
Recent advancements in large language models (LLMs) have provided a new avenue for chatbot development, while most existing research has primarily centered on single-user chatbots that focus on deciding "What" to answer after user inputs. In this paper, we identified that multi-user chatbots have more complex 3W design dimensions -- "What" to say, "When" to respond, and "Who" to answer. Additionally, we proposed Multi-User Chat Assistant (MUCA), which is an LLM-based framework for chatbots specifically designed for group discussions. MUCA consists of three main modules: Sub-topic Generator, Dialog Analyzer, and Utterance Strategies Arbitrator. These modules jointly determine suitable response contents, timings, and the appropriate recipients. To make the optimizing process for MUCA easier, we further propose an LLM-based Multi-User Simulator (MUS) that can mimic real user behavior. This enables faster simulation of a conversation between the chatbot and simulated users, making the early development of the chatbot framework much more efficient. MUCA demonstrates effectiveness, including appropriate chime-in timing, relevant content, and positive user engagement, in goal-oriented conversations with a small to medium number of participants, as evidenced by case studies and experimental results from user studies.
BatchPrompt: Accomplish more with less
Sep 05, 2023



As the ever-increasing token limits of large language models (LLMs) have enabled long context as input, prompting with single data samples might no longer an efficient way. A straightforward strategy improving efficiency is to batch data within the token limit (e.g., 8k for gpt-3.5-turbo; 32k for GPT-4), which we call BatchPrompt. We have two initial observations for prompting with batched data. First, we find that prompting with batched data in longer contexts will inevitably lead to worse performance, compared to single-data prompting. Second, the performance of the language model is significantly correlated with the positions and order of the batched data, due to the corresponding change in decoder context. To retain efficiency and overcome performance loss, we propose Batch Permutation and Ensembling (BPE), and a novel Self-reflection-guided EArly Stopping (SEAS) technique. Our comprehensive experimental evaluation demonstrates that BPE can boost the performance of BatchPrompt with a striking margin on a range of popular NLP tasks, including question answering (Boolq), textual entailment (RTE), and duplicate questions identification (QQP). These performances are even competitive with/higher than single-data prompting(SinglePrompt), while BatchPrompt requires much fewer LLM calls and input tokens (For SinglePrompt v.s. BatchPrompt with batch size 32, using just 9%-16% the number of LLM calls, Boolq accuracy 90.6% to 90.9% with 27.4% tokens, QQP accuracy 87.2% to 88.4% with 18.6% tokens, RTE accuracy 91.5% to 91.1% with 30.8% tokens). To the best of our knowledge, this is the first work to technically improve prompting efficiency of large language models. We hope our simple yet effective approach will shed light on the future research of large language models. The code will be released.
CitySurfaces: City-Scale Semantic Segmentation of Sidewalk Materials
Jan 06, 2022



While designing sustainable and resilient urban built environment is increasingly promoted around the world, significant data gaps have made research on pressing sustainability issues challenging to carry out. Pavements are known to have strong economic and environmental impacts; however, most cities lack a spatial catalog of their surfaces due to the cost-prohibitive and time-consuming nature of data collection. Recent advancements in computer vision, together with the availability of street-level images, provide new opportunities for cities to extract large-scale built environment data with lower implementation costs and higher accuracy. In this paper, we propose CitySurfaces, an active learning-based framework that leverages computer vision techniques for classifying sidewalk materials using widely available street-level images. We trained the framework on images from New York City and Boston and the evaluation results show a 90.5% mIoU score. Furthermore, we evaluated the framework using images from six different cities, demonstrating that it can be applied to regions with distinct urban fabrics, even outside the domain of the training data. CitySurfaces can provide researchers and city agencies with a low-cost, accurate, and extensible method to collect sidewalk material data which plays a critical role in addressing major sustainability issues, including climate change and surface water management.
NYU-VPR: Long-Term Visual Place Recognition Benchmark with View Direction and Data Anonymization Influences
Oct 18, 2021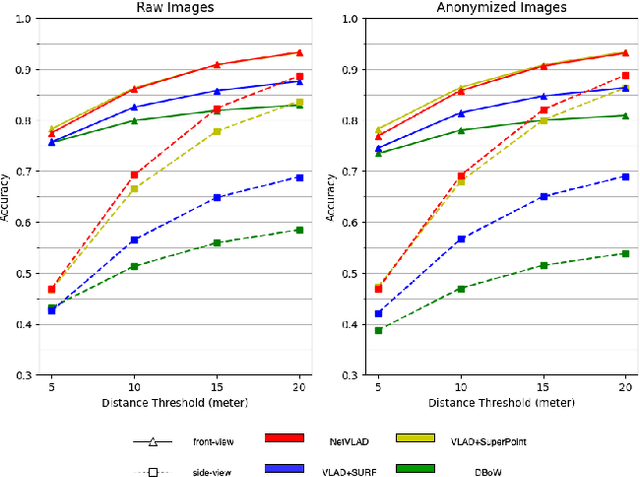
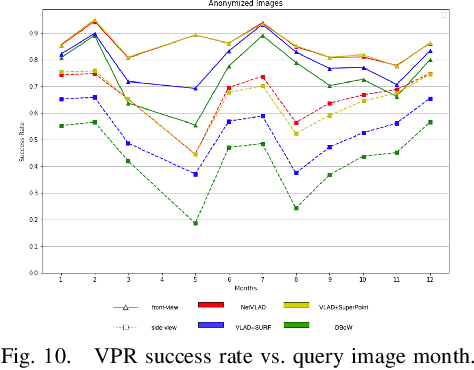


Visual place recognition (VPR) is critical in not only localization and mapping for autonomous driving vehicles, but also assistive navigation for the visually impaired population. To enable a long-term VPR system on a large scale, several challenges need to be addressed. First, different applications could require different image view directions, such as front views for self-driving cars while side views for the low vision people. Second, VPR in metropolitan scenes can often cause privacy concerns due to the imaging of pedestrian and vehicle identity information, calling for the need for data anonymization before VPR queries and database construction. Both factors could lead to VPR performance variations that are not well understood yet. To study their influences, we present the NYU-VPR dataset that contains more than 200,000 images over a 2km by 2km area near the New York University campus, taken within the whole year of 2016. We present benchmark results on several popular VPR algorithms showing that side views are significantly more challenging for current VPR methods while the influence of data anonymization is almost negligible, together with our hypothetical explanations and in-depth analysis.
IntentVizor: Towards Generic Query Guided Interactive Video Summarization Using Slow-Fast Graph Convolutional Networks
Sep 30, 2021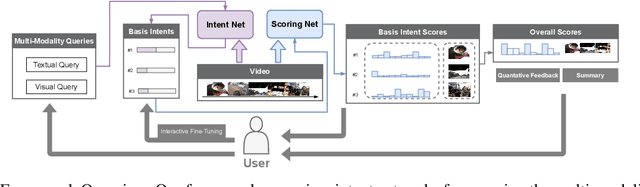
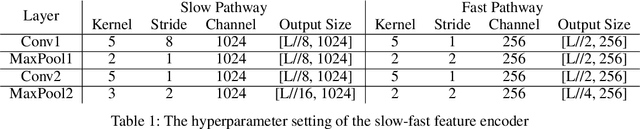
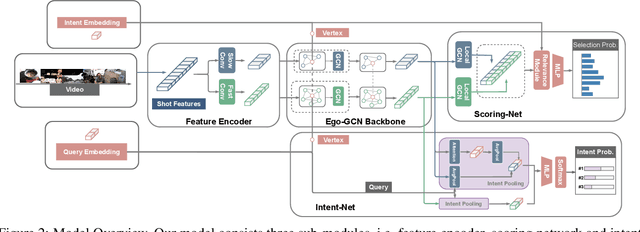
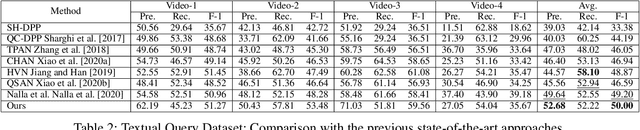
The target of automatic Video summarization is to create a short skim of the original long video while preserving the major content/events. There is a growing interest in the integration of user's queries into video summarization, or query-driven video summarization. This video summarization method predicts a concise synopsis of the original video based on the user query, which is commonly represented by the input text. However, two inherent problems exist in this query-driven way. First, the query text might not be enough to describe the exact and diverse needs of the user. Second, the user cannot edit once the summaries are produced, limiting this summarization technique's practical value. We assume the needs of the user should be subtle and need to be adjusted interactively. To solve these two problems, we propose a novel IntentVizor framework, which is an interactive video summarization framework guided by genric multi-modality queries. The input query that describes the user's needs is not limited to text but also the video snippets. We further conclude these multi-modality finer-grained queries as user `intent', which is a newly proposed concept in this paper. This intent is interpretable, interactable, and better quantifies/describes the user's needs. To be more specific, We use a set of intents to represent the inputs of users to design our new interactive visual analytic interface. Users can interactively control and adjust these mixed-initiative intents to obtain a more satisfying summary of this newly proposed interface. Also, as algorithms help users achieve their summarization goal via video understanding, we propose two novel intent/scoring networks based on the slow-fast feature for our algorithm part. We conduct our experiments on two benchmark datasets. The comparison with the state-of-the-art methods verifies the effectiveness of the proposed framework.
Rethinking Crowdsourcing Annotation: Partial Annotation with Salient Labels for Multi-Label Image Classification
Sep 06, 2021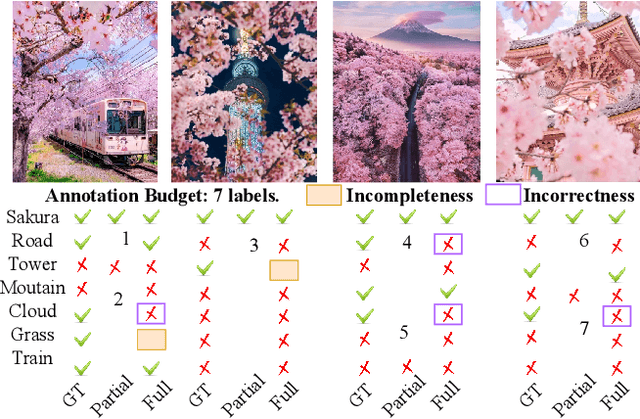
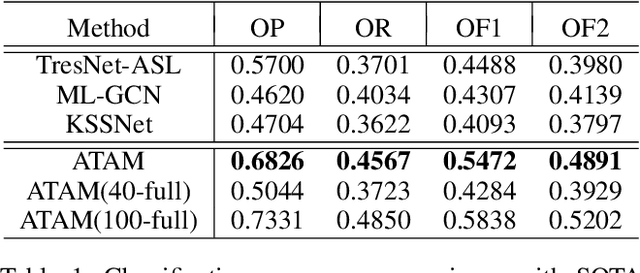
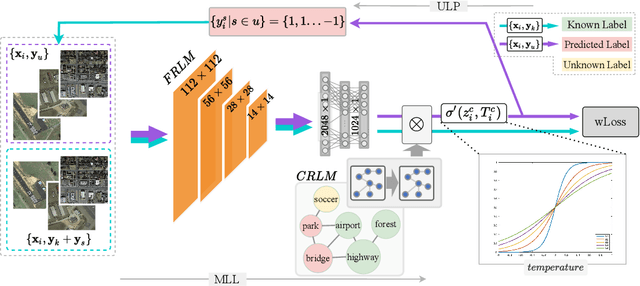
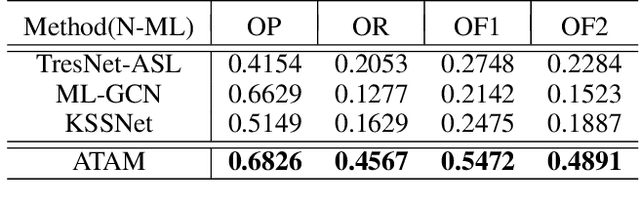
Annotated images are required for both supervised model training and evaluation in image classification. Manually annotating images is arduous and expensive, especially for multi-labeled images. A recent trend for conducting such laboursome annotation tasks is through crowdsourcing, where images are annotated by volunteers or paid workers online (e.g., workers of Amazon Mechanical Turk) from scratch. However, the quality of crowdsourcing image annotations cannot be guaranteed, and incompleteness and incorrectness are two major concerns for crowdsourcing annotations. To address such concerns, we have a rethinking of crowdsourcing annotations: Our simple hypothesis is that if the annotators only partially annotate multi-label images with salient labels they are confident in, there will be fewer annotation errors and annotators will spend less time on uncertain labels. As a pleasant surprise, with the same annotation budget, we show a multi-label image classifier supervised by images with salient annotations can outperform models supervised by fully annotated images. Our method contributions are 2-fold: An active learning way is proposed to acquire salient labels for multi-label images; and a novel Adaptive Temperature Associated Model (ATAM) specifically using partial annotations is proposed for multi-label image classification. We conduct experiments on practical crowdsourcing data, the Open Street Map (OSM) dataset and benchmark dataset COCO 2014. When compared with state-of-the-art classification methods trained on fully annotated images, the proposed ATAM can achieve higher accuracy. The proposed idea is promising for crowdsourcing data annotation. Our code will be publicly available.
ERA: Entity Relationship Aware Video Summarization with Wasserstein GAN
Sep 06, 2021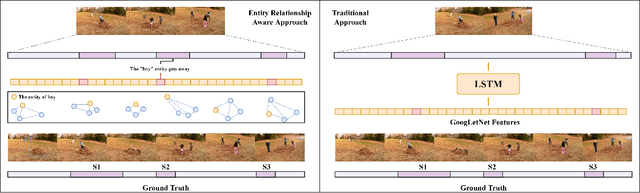
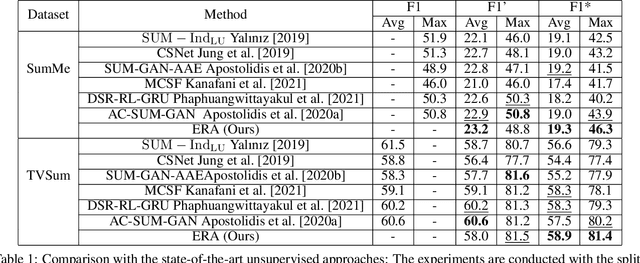
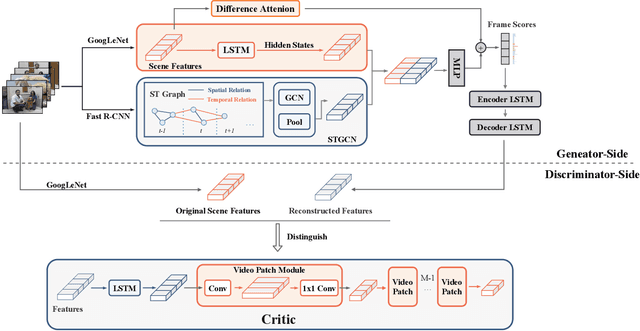

Video summarization aims to simplify large scale video browsing by generating concise, short summaries that diver from but well represent the original video. Due to the scarcity of video annotations, recent progress for video summarization concentrates on unsupervised methods, among which the GAN based methods are most prevalent. This type of methods includes a summarizer and a discriminator. The summarized video from the summarizer will be assumed as the final output, only if the video reconstructed from this summary cannot be discriminated from the original one by the discriminator. The primary problems of this GAN based methods are two folds. First, the summarized video in this way is a subset of original video with low redundancy and contains high priority events/entities. This summarization criterion is not enough. Second, the training of the GAN framework is not stable. This paper proposes a novel Entity relationship Aware video summarization method (ERA) to address the above problems. To be more specific, we introduce an Adversarial Spatio Temporal network to construct the relationship among entities, which we think should also be given high priority in the summarization. The GAN training problem is solved by introducing the Wasserstein GAN and two newly proposed video patch/score sum losses. In addition, the score sum loss can also relieve the model sensitivity to the varying video lengths, which is an inherent problem for most current video analysis tasks. Our method substantially lifts the performance on the target benchmark datasets and exceeds the current leaderboard Rank 1 state of the art CSNet (2.1% F1 score increase on TVSum and 3.1% F1 score increase on SumMe). We hope our straightforward yet effective approach will shed some light on the future research of unsupervised video summarization.
SCIDA: Self-Correction Integrated Domain Adaptation from Single- to Multi-label Aerial Images
Aug 15, 2021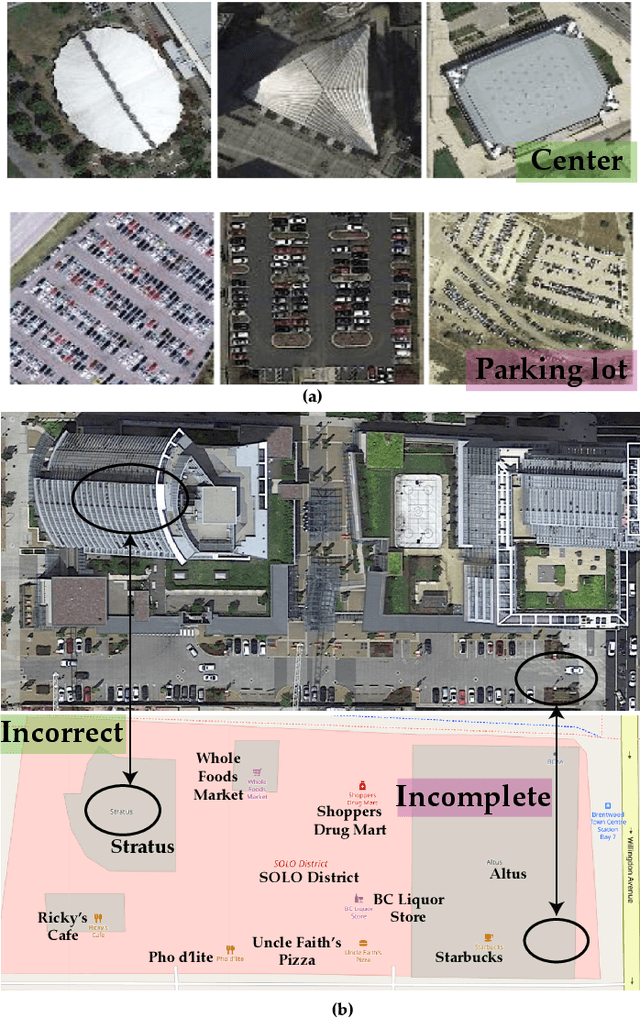
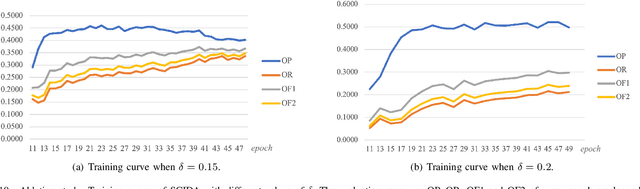
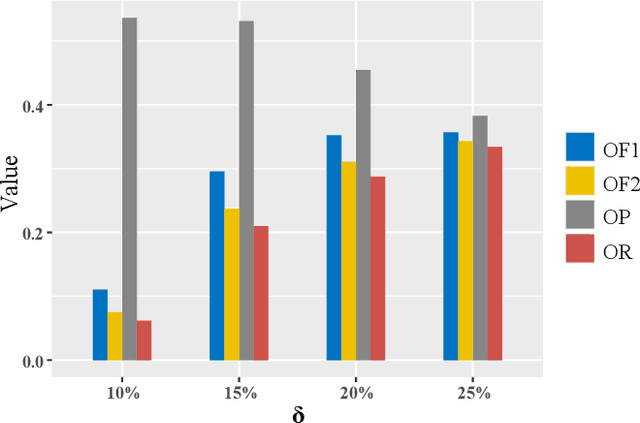
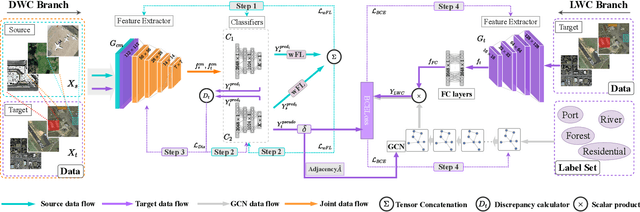
Most publicly available datasets for image classification are with single labels, while images are inherently multi-labeled in our daily life. Such an annotation gap makes many pre-trained single-label classification models fail in practical scenarios. This annotation issue is more concerned for aerial images: Aerial data collected from sensors naturally cover a relatively large land area with multiple labels, while annotated aerial datasets, which are publicly available (e.g., UCM, AID), are single-labeled. As manually annotating multi-label aerial images would be time/labor-consuming, we propose a novel self-correction integrated domain adaptation (SCIDA) method for automatic multi-label learning. SCIDA is weakly supervised, i.e., automatically learning the multi-label image classification model from using massive, publicly available single-label images. To achieve this goal, we propose a novel Label-Wise self-Correction (LWC) module to better explore underlying label correlations. This module also makes the unsupervised domain adaptation (UDA) from single- to multi-label data possible. For model training, the proposed model only uses single-label information yet requires no prior knowledge of multi-labeled data; and it predicts labels for multi-label aerial images. In our experiments, trained with single-labeled MAI-AID-s and MAI-UCM-s datasets, the proposed model is tested directly on our collected Multi-scene Aerial Image (MAI) dataset.