 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrbanite: A Dataflow-Based Framework for Human-AI Interactive Alignment in Urban Visual Analytics
Aug 10, 2025With the growing availability of urban data and the increasing complexity of societal challenges, visual analytics has become essential for deriving insights into pressing real-world problems. However, analyzing such data is inherently complex and iterative, requiring expertise across multiple domains. The need to manage diverse datasets, distill intricate workflows, and integrate various analytical methods presents a high barrier to entry, especially for researchers and urban experts who lack proficiency in data management, machine learning, and visualization. Advancements in large language models offer a promising solution to lower the barriers to the construction of analytics systems by enabling users to specify intent rather than define precise computational operations. However, this shift from explicit operations to intent-based interaction introduces challenges in ensuring alignment throughout the design and development process. Without proper mechanisms, gaps can emerge between user intent, system behavior, and analytical outcomes. To address these challenges, we propose Urbanite, a framework for human-AI collaboration in urban visual analytics. Urbanite leverages a dataflow-based model that allows users to specify intent at multiple scopes, enabling interactive alignment across the specification, process, and evaluation stages of urban analytics. Based on findings from a survey to uncover challenges, Urbanite incorporates features to facilitate explainability, multi-resolution definition of tasks across dataflows, nodes, and parameters, while supporting the provenance of interactions. We demonstrate Urbanite's effectiveness through usage scenarios created in collaboration with urban experts. Urbanite is available at https://urbantk.org/urbanite.
ELSA: Evaluating Localization of Social Activities in Urban Streets
Jun 03, 2024



Why do some streets attract more social activities than others? Is it due to street design, or do land use patterns in neighborhoods create opportunities for businesses where people gather? These questions have intrigued urban sociologists, designers, and planners for decades. Yet, most research in this area has remained limited in scale, lacking a comprehensive perspective on the various factors influencing social interactions in urban settings. Exploring these issues requires fine-level data on the frequency and variety of social interactions on urban street. Recent advances in computer vision and the emergence of the open-vocabulary detection models offer a unique opportunity to address this long-standing issue on a scale that was previously impossible using traditional observational methods. In this paper, we propose a new benchmark dataset for Evaluating Localization of Social Activities (ELSA) in urban street images. ELSA draws on theoretical frameworks in urban sociology and design. While majority of action recognition datasets are collected in controlled settings, we use in-the-wild street-level imagery, where the size of social groups and the types of activities can vary significantly. ELSA includes 937 manually annotated images with more than 4,300 multi-labeled bounding boxes for individual and group activities, categorized into three primary groups: Condition, State, and Action. Each category contains various sub-categories, e.g., alone or group under Condition category, standing or walking, which fall under the State category, and talking or dining with regards to the Action category. ELSA is publicly available for the research community.
Deep Umbra: A Generative Approach for Sunlight Access Computation in Urban Spaces
Feb 27, 2024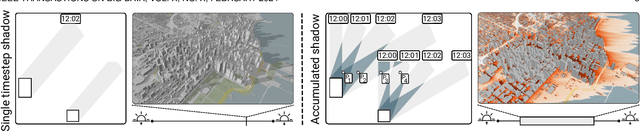
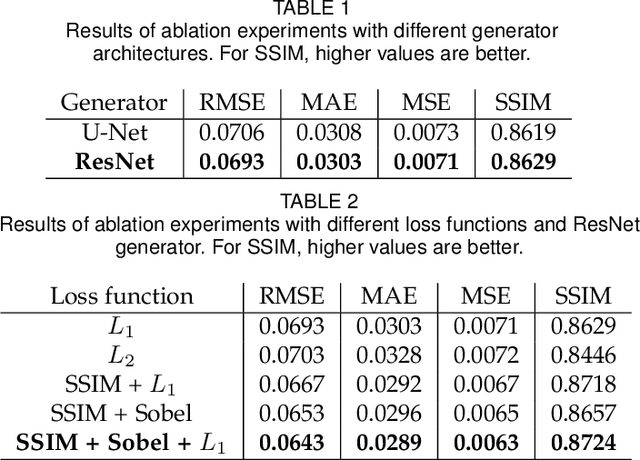
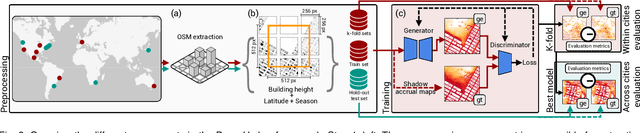
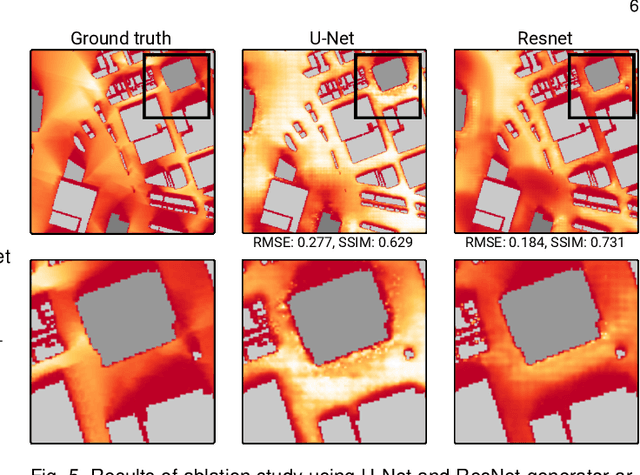
Sunlight and shadow play critical roles in how urban spaces are utilized, thrive, and grow. While access to sunlight is essential to the success of urban environments, shadows can provide shaded places to stay during the hot seasons, mitigate heat island effect, and increase pedestrian comfort levels. Properly quantifying sunlight access and shadows in large urban environments is key in tackling some of the important challenges facing cities today. In this paper, we propose Deep Umbra, a novel computational framework that enables the quantification of sunlight access and shadows at a global scale. Our framework is based on a conditional generative adversarial network that considers the physical form of cities to compute high-resolution spatial information of accumulated sunlight access for the different seasons of the year. We use data from seven different cities to train our model, and show, through an extensive set of experiments, its low overall RMSE (below 0.1) as well as its extensibility to cities that were not part of the training set. Additionally, we contribute a set of case studies and a comprehensive dataset with sunlight access information for more than 100 cities across six continents of the world. Deep Umbra is available at https://urbantk.org/shadows.
ALFA -- Leveraging All Levels of Feature Abstraction for Enhancing the Generalization of Histopathology Image Classification Across Unseen Hospitals
Aug 09, 2023



We propose an exhaustive methodology that leverages all levels of feature abstraction, targeting an enhancement in the generalizability of image classification to unobserved hospitals. Our approach incorporates augmentation-based self-supervision with common distribution shifts in histopathology scenarios serving as the pretext task. This enables us to derive invariant features from training images without relying on training labels, thereby covering different abstraction levels. Moving onto the subsequent abstraction level, we employ a domain alignment module to facilitate further extraction of invariant features across varying training hospitals. To represent the highly specific features of participating hospitals, an encoder is trained to classify hospital labels, independent of their diagnostic labels. The features from each of these encoders are subsequently disentangled to minimize redundancy and segregate the features. This representation, which spans a broad spectrum of semantic information, enables the development of a model demonstrating increased robustness to unseen images from disparate distributions. Experimental results from the PACS dataset (a domain generalization benchmark), a synthetic dataset created by applying histopathology-specific jitters to the MHIST dataset (defining different domains with varied distribution shifts), and a Renal Cell Carcinoma dataset derived from four image repositories from TCGA, collectively indicate that our proposed model is adept at managing varying levels of image granularity. Thus, it shows improved generalizability when faced with new, out-of-distribution hospital images.
Towards Global-Scale Crowd+AI Techniques to Map and Assess Sidewalks for People with Disabilities
Jun 28, 2022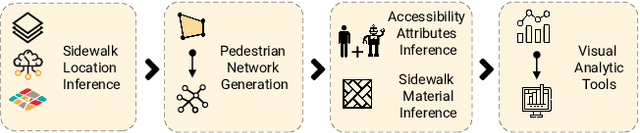


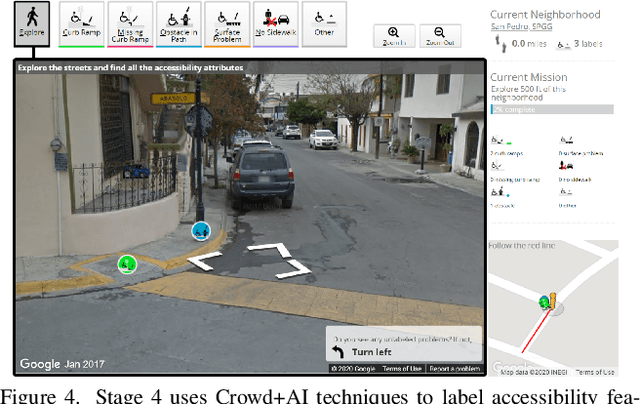
There is a lack of data on the location, condition, and accessibility of sidewalks across the world, which not only impacts where and how people travel but also fundamentally limits interactive mapping tools and urban analytics. In this paper, we describe initial work in semi-automatically building a sidewalk network topology from satellite imagery using hierarchical multi-scale attention models, inferring surface materials from street-level images using active learning-based semantic segmentation, and assessing sidewalk condition and accessibility features using Crowd+AI. We close with a call to create a database of labeled satellite and streetscape scenes for sidewalks and sidewalk accessibility issues along with standardized benchmarks.
Urban Rhapsody: Large-scale exploration of urban soundscapes
May 25, 2022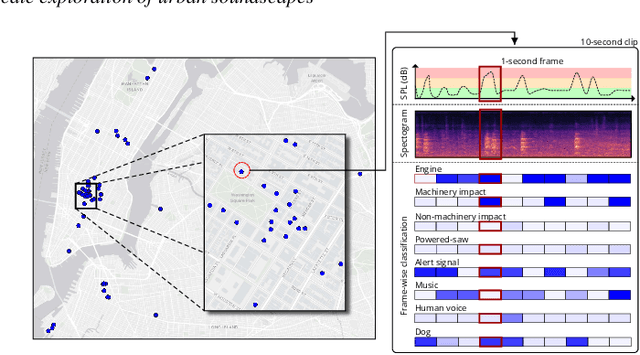
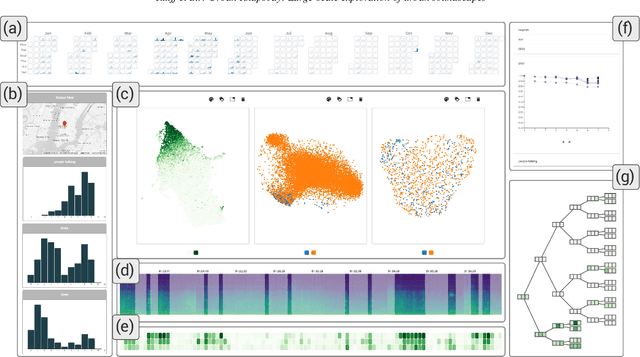
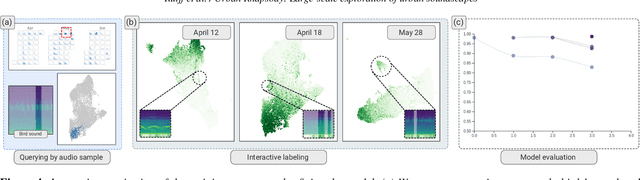
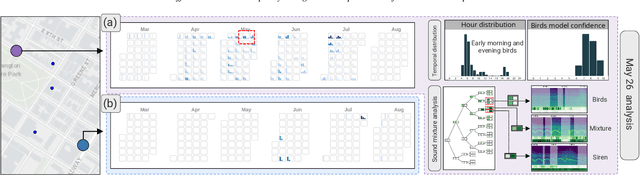
Noise is one of the primary quality-of-life issues in urban environments. In addition to annoyance, noise negatively impacts public health and educational performance. While low-cost sensors can be deployed to monitor ambient noise levels at high temporal resolutions, the amount of data they produce and the complexity of these data pose significant analytical challenges. One way to address these challenges is through machine listening techniques, which are used to extract features in attempts to classify the source of noise and understand temporal patterns of a city's noise situation. However, the overwhelming number of noise sources in the urban environment and the scarcity of labeled data makes it nearly impossible to create classification models with large enough vocabularies that capture the true dynamism of urban soundscapes In this paper, we first identify a set of requirements in the yet unexplored domain of urban soundscape exploration. To satisfy the requirements and tackle the identified challenges, we propose Urban Rhapsody, a framework that combines state-of-the-art audio representation, machine learning, and visual analytics to allow users to interactively create classification models, understand noise patterns of a city, and quickly retrieve and label audio excerpts in order to create a large high-precision annotated database of urban sound recordings. We demonstrate the tool's utility through case studies performed by domain experts using data generated over the five-year deployment of a one-of-a-kind sensor network in New York City.
CitySurfaces: City-Scale Semantic Segmentation of Sidewalk Materials
Jan 06, 2022



While designing sustainable and resilient urban built environment is increasingly promoted around the world, significant data gaps have made research on pressing sustainability issues challenging to carry out. Pavements are known to have strong economic and environmental impacts; however, most cities lack a spatial catalog of their surfaces due to the cost-prohibitive and time-consuming nature of data collection. Recent advancements in computer vision, together with the availability of street-level images, provide new opportunities for cities to extract large-scale built environment data with lower implementation costs and higher accuracy. In this paper, we propose CitySurfaces, an active learning-based framework that leverages computer vision techniques for classifying sidewalk materials using widely available street-level images. We trained the framework on images from New York City and Boston and the evaluation results show a 90.5% mIoU score. Furthermore, we evaluated the framework using images from six different cities, demonstrating that it can be applied to regions with distinct urban fabrics, even outside the domain of the training data. CitySurfaces can provide researchers and city agencies with a low-cost, accurate, and extensible method to collect sidewalk material data which plays a critical role in addressing major sustainability issues, including climate change and surface water management.
Sidewalk Measurements from Satellite Images: Preliminary Findings
Dec 12, 2021



Large-scale analysis of pedestrian infrastructures, particularly sidewalks, is critical to human-centric urban planning and design. Benefiting from the rich data set of planimetric features and high-resolution orthoimages provided through the New York City Open Data portal, we train a computer vision model to detect sidewalks, roads, and buildings from remote-sensing imagery and achieve 83% mIoU over held-out test set. We apply shape analysis techniques to study different attributes of the extracted sidewalks. More specifically, we do a tile-wise analysis of the width, angle, and curvature of sidewalks, which aside from their general impacts on walkability and accessibility of urban areas, are known to have significant roles in the mobility of wheelchair users. The preliminary results are promising, glimpsing the potential of the proposed approach to be adopted in different cities, enabling researchers and practitioners to have a more vivid picture of the pedestrian realm.