 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Grimoire: Codebook-based Shape Generation under Raster Image Supervision
Oct 08, 2024
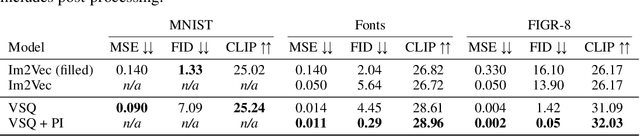
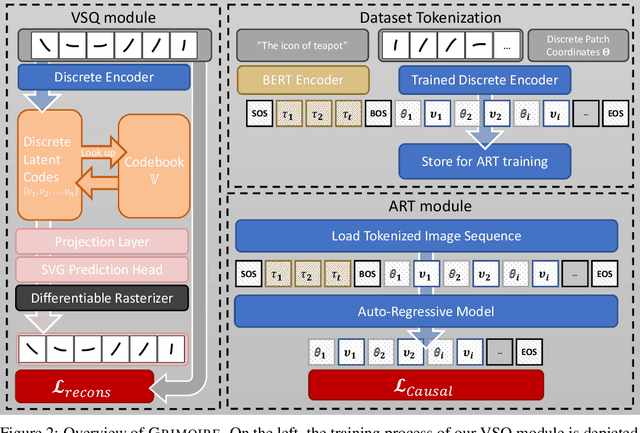
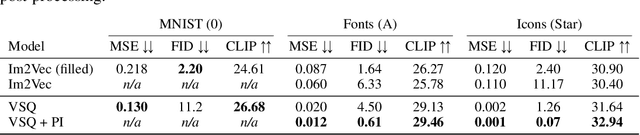
Scalable Vector Graphics (SVG) is a popular format on the web and in the design industry. However, despite the great strides made in generative modeling, SVG has remained underexplored due to the discrete and complex nature of such data. We introduce GRIMOIRE, a text-guided SVG generative model that is comprised of two modules: A Visual Shape Quantizer (VSQ) learns to map raster images onto a discrete codebook by reconstructing them as vector shapes, and an Auto-Regressive Transformer (ART) models the joint probability distribution over shape tokens, positions and textual descriptions, allowing us to generate vector graphics from natural language. Unlike existing models that require direct supervision from SVG data, GRIMOIRE learns shape image patches using only raster image supervision which opens up vector generative modeling to significantly more data. We demonstrate the effectiveness of our method by fitting GRIMOIRE for closed filled shapes on the MNIST and for outline strokes on icon and font data, surpassing previous image-supervised methods in generative quality and vector-supervised approach in flexibility.
ELSA: Evaluating Localization of Social Activities in Urban Streets
Jun 03, 2024



Why do some streets attract more social activities than others? Is it due to street design, or do land use patterns in neighborhoods create opportunities for businesses where people gather? These questions have intrigued urban sociologists, designers, and planners for decades. Yet, most research in this area has remained limited in scale, lacking a comprehensive perspective on the various factors influencing social interactions in urban settings. Exploring these issues requires fine-level data on the frequency and variety of social interactions on urban street. Recent advances in computer vision and the emergence of the open-vocabulary detection models offer a unique opportunity to address this long-standing issue on a scale that was previously impossible using traditional observational methods. In this paper, we propose a new benchmark dataset for Evaluating Localization of Social Activities (ELSA) in urban street images. ELSA draws on theoretical frameworks in urban sociology and design. While majority of action recognition datasets are collected in controlled settings, we use in-the-wild street-level imagery, where the size of social groups and the types of activities can vary significantly. ELSA includes 937 manually annotated images with more than 4,300 multi-labeled bounding boxes for individual and group activities, categorized into three primary groups: Condition, State, and Action. Each category contains various sub-categories, e.g., alone or group under Condition category, standing or walking, which fall under the State category, and talking or dining with regards to the Action category. ELSA is publicly available for the research community.
The color out of space: learning self-supervised representations for Earth Observation imagery
Jun 22, 2020
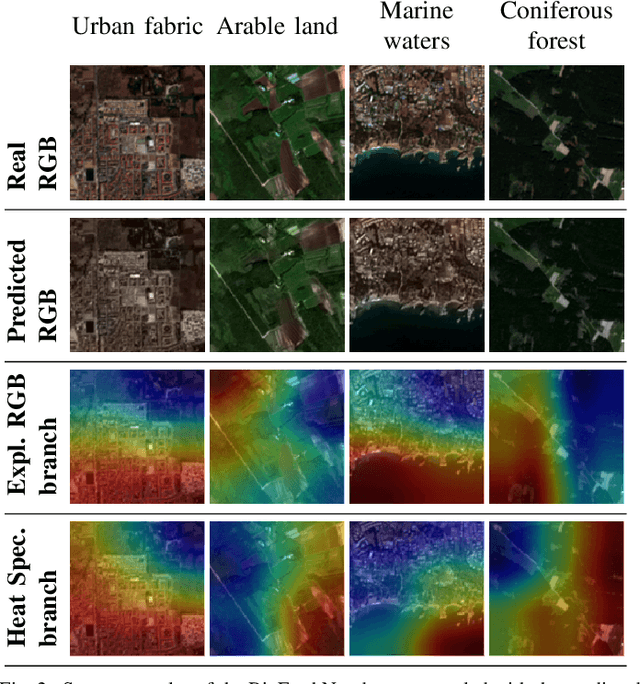
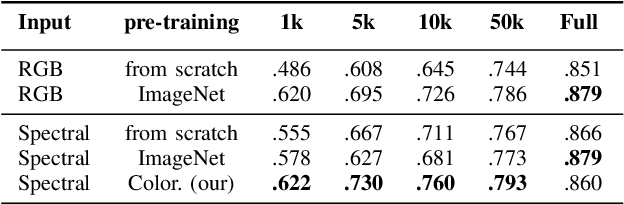
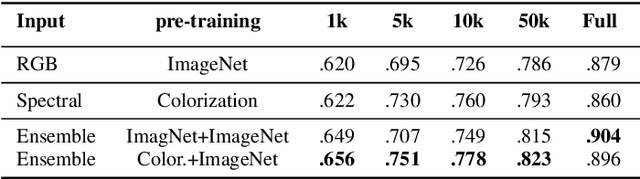
The recent growth in the number of satellite images fosters the development of effective deep-learning techniques for Remote Sensing (RS). However, their full potential is untapped due to the lack of large annotated datasets. Such a problem is usually countered by fine-tuning a feature extractor that is previously trained on the ImageNet dataset. Unfortunately, the domain of natural images differs from the RS one, which hinders the final performance. In this work, we propose to learn meaningful representations from satellite imagery, leveraging its high-dimensionality spectral bands to reconstruct the visible colors. We conduct experiments on land cover classification (BigEarthNet) and West Nile Virus detection, showing that colorization is a solid pretext task for training a feature extractor. Furthermore, we qualitatively observe that guesses based on natural images and colorization rely on different parts of the input. This paves the way to an ensemble model that eventually outperforms both the above-mentioned techniques.