 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Pretrained Dense and Contextual Embeddings
Feb 13, 2026In this report, we introduce pplx-embed, a family of multilingual embedding models that employ multi-stage contrastive learning on a diffusion-pretrained language model backbone for web-scale retrieval. By leveraging bidirectional attention through diffusion-based pretraining, our models capture comprehensive bidirectional context within passages, enabling the use of mean pooling and a late chunking strategy to better preserve global context across long documents. We release two model types: pplx-embed-v1 for standard retrieval, and pplx-embed-context-v1 for contextualized embeddings that incorporate global document context into passage representations. pplx-embed-v1 achieves competitive performance on the MTEB(Multilingual, v2), MTEB(Code), MIRACL, BERGEN, and ToolRet retrieval benchmarks, while pplx-embed-context-v1 sets new records on the ConTEB benchmark. Beyond public benchmarks, pplx-embed-v1 demonstrates strong performance on our internal evaluation suite, focusing on real-world, large-scale search scenarios constructed from 1B production web pages. These results validate the models' effectiveness in production environments where retrieval quality and efficiency are critical at scale.
jina-embeddings-v4: Universal Embeddings for Multimodal Multilingual Retrieval
Jun 24, 2025We introduce jina-embeddings-v4, a 3.8 billion parameter multimodal embedding model that unifies text and image representations through a novel architecture supporting both single-vector and multi-vector embeddings in the late interaction style. The model incorporates task-specific Low-Rank Adaptation (LoRA) adapters to optimize performance across diverse retrieval scenarios, including query-document retrieval, semantic text similarity, and code search. Comprehensive evaluations demonstrate that jina-embeddings-v4 achieves state-of-the-art performance on both single-modal and cross-modal retrieval tasks, with particular strength in processing visually rich content such as tables, charts, diagrams, and mixed-media formats. To facilitate evaluation of this capability, we also introduce Jina-VDR, a novel benchmark specifically designed for visually rich image retrieval.
jina-clip-v2: Multilingual Multimodal Embeddings for Text and Images
Dec 11, 2024



Contrastive Language-Image Pretraining (CLIP) is a highly effective method for aligning images and texts in a shared embedding space. These models are widely used for tasks such as cross-modal information retrieval and multi-modal understanding. However, CLIP models often struggle with text-only tasks, underperforming compared to specialized text models. This performance disparity forces retrieval systems to rely on separate models for text-only and multi-modal tasks. In this work, we build upon our previous model, jina-clip-v1, by introducing a refined framework that utilizes multi-task, multi-stage contrastive learning across multiple languages, coupled with an improved training recipe to enhance text-only retrieval. The resulting model, jina-clip-v2, outperforms its predecessor on text-only and multimodal tasks, while adding multilingual support, better understanding of complex visual documents and efficiency gains thanks to Matryoshka Representation Learning and vector truncation. The model performs comparably to the state-of-the-art in both multilingual-multimodal and multilingual text retrieval benchmarks, addressing the challenge of unifying text-only and multi-modal retrieval systems.
Mitigate the Gap: Investigating Approaches for Improving Cross-Modal Alignment in CLIP
Jun 26, 2024Contrastive Language--Image Pre-training (CLIP) has manifested remarkable improvements in zero-shot classification and cross-modal vision-language tasks. Yet, from a geometrical point of view, the CLIP embedding space has been found to have a pronounced modality gap. This gap renders the embedding space overly sparse and disconnected, with different modalities being densely distributed in distinct subregions of the hypersphere. In this work, we aim at answering two main questions: 1. Does sharing the parameter space between the multi-modal encoders reduce the modality gap? 2. Can the gap be mitigated by pushing apart the uni-modal embeddings via intra-modality separation? We design AlignCLIP, in order to answer these questions and show that answers to both questions are positive. Through extensive experiments, we show that AlignCLIP achieves noticeable enhancements in the cross-modal alignment of the embeddings, and thereby, reduces the modality gap, while maintaining the performance across several downstream evaluations, such as zero-shot image classification, zero-shot multi-modal retrieval and zero-shot semantic text similarity.
ELSA: Evaluating Localization of Social Activities in Urban Streets
Jun 03, 2024



Why do some streets attract more social activities than others? Is it due to street design, or do land use patterns in neighborhoods create opportunities for businesses where people gather? These questions have intrigued urban sociologists, designers, and planners for decades. Yet, most research in this area has remained limited in scale, lacking a comprehensive perspective on the various factors influencing social interactions in urban settings. Exploring these issues requires fine-level data on the frequency and variety of social interactions on urban street. Recent advances in computer vision and the emergence of the open-vocabulary detection models offer a unique opportunity to address this long-standing issue on a scale that was previously impossible using traditional observational methods. In this paper, we propose a new benchmark dataset for Evaluating Localization of Social Activities (ELSA) in urban street images. ELSA draws on theoretical frameworks in urban sociology and design. While majority of action recognition datasets are collected in controlled settings, we use in-the-wild street-level imagery, where the size of social groups and the types of activities can vary significantly. ELSA includes 937 manually annotated images with more than 4,300 multi-labeled bounding boxes for individual and group activities, categorized into three primary groups: Condition, State, and Action. Each category contains various sub-categories, e.g., alone or group under Condition category, standing or walking, which fall under the State category, and talking or dining with regards to the Action category. ELSA is publicly available for the research community.
Does CLIP Benefit Visual Question Answering in the Medical Domain as Much as it Does in the General Domain?
Dec 27, 2021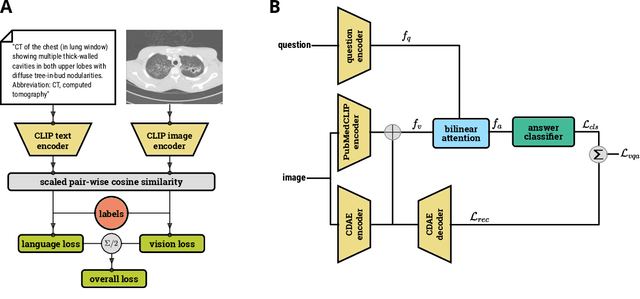
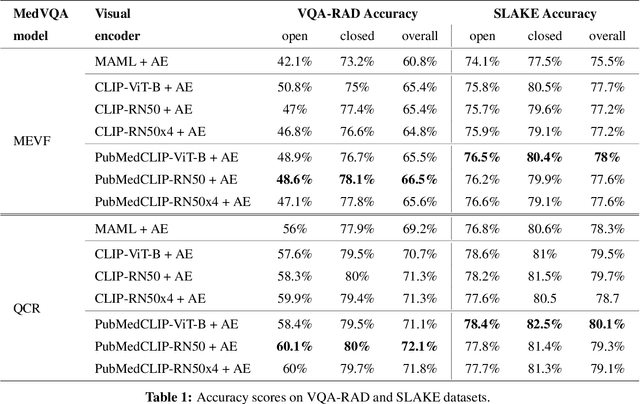
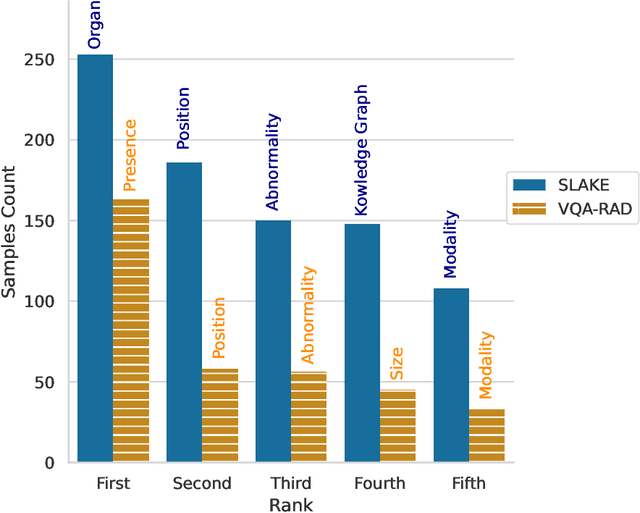
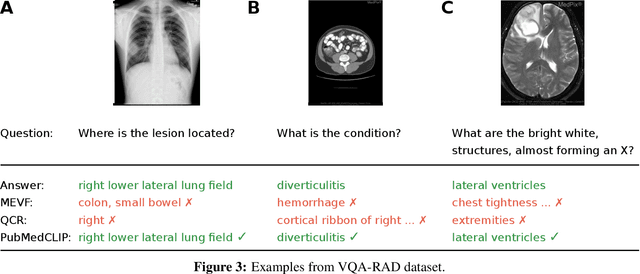
Contrastive Language--Image Pre-training (CLIP) has shown remarkable success in learning with cross-modal supervision from extensive amounts of image--text pairs collected online. Thus far, the effectiveness of CLIP has been investigated primarily in general-domain multimodal problems. This work evaluates the effectiveness of CLIP for the task of Medical Visual Question Answering (MedVQA). To this end, we present PubMedCLIP, a fine-tuned version of CLIP for the medical domain based on PubMed articles. Our experiments are conducted on two MedVQA benchmark datasets and investigate two MedVQA methods, MEVF (Mixture of Enhanced Visual Features) and QCR (Question answering via Conditional Reasoning). For each of these, we assess the merits of visual representation learning using PubMedCLIP, the original CLIP, and state-of-the-art MAML (Model-Agnostic Meta-Learning) networks pre-trained only on visual data. We open source the code for our MedVQA pipeline and pre-training PubMedCLIP. CLIP and PubMedCLIP achieve improvements in comparison to MAML's visual encoder. PubMedCLIP achieves the best results with gains in the overall accuracy of up to 3%. Individual examples illustrate the strengths of PubMedCLIP in comparison to the previously widely used MAML networks. Visual representation learning with language supervision in PubMedCLIP leads to noticeable improvements for MedVQA. Our experiments reveal distributional differences in the two MedVQA benchmark datasets that have not been imparted in previous work and cause different back-end visual encoders in PubMedCLIP to exhibit different behavior on these datasets. Moreover, we witness fundamental performance differences of VQA in general versus medical domains.
SignCol: Open-Source Software for Collecting Sign Language Gestures
Oct 31, 2019

Sign(ed) languages use gestures, such as hand or head movements, for communication. Sign language recognition is an assistive technology for individuals with hearing disability and its goal is to improve such individuals' life quality by facilitating their social involvement. Since sign languages are vastly varied in alphabets, as known as signs, a sign recognition software should be capable of handling eight different types of sign combinations, e.g. numbers, letters, words and sentences. Due to the intrinsic complexity and diversity of symbolic gestures, recognition algorithms need a comprehensive visual dataset to learn by. In this paper, we describe the design and implementation of a Microsoft Kinect-based open source software, called SignCol, for capturing and saving the gestures used in sign languages. Our work supports a multi-language database and reports the recorded items statistics. SignCol can capture and store colored(RGB) frames, depth frames, infrared frames, body index frames, coordinate mapped color-body frames, skeleton information of each frame and camera parameters simultaneously.