 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgejina-clip-v2: Multilingual Multimodal Embeddings for Text and Images
Dec 11, 2024



Contrastive Language-Image Pretraining (CLIP) is a highly effective method for aligning images and texts in a shared embedding space. These models are widely used for tasks such as cross-modal information retrieval and multi-modal understanding. However, CLIP models often struggle with text-only tasks, underperforming compared to specialized text models. This performance disparity forces retrieval systems to rely on separate models for text-only and multi-modal tasks. In this work, we build upon our previous model, jina-clip-v1, by introducing a refined framework that utilizes multi-task, multi-stage contrastive learning across multiple languages, coupled with an improved training recipe to enhance text-only retrieval. The resulting model, jina-clip-v2, outperforms its predecessor on text-only and multimodal tasks, while adding multilingual support, better understanding of complex visual documents and efficiency gains thanks to Matryoshka Representation Learning and vector truncation. The model performs comparably to the state-of-the-art in both multilingual-multimodal and multilingual text retrieval benchmarks, addressing the challenge of unifying text-only and multi-modal retrieval systems.
jina-embeddings-v3: Multilingual Embeddings With Task LoRA
Sep 17, 2024


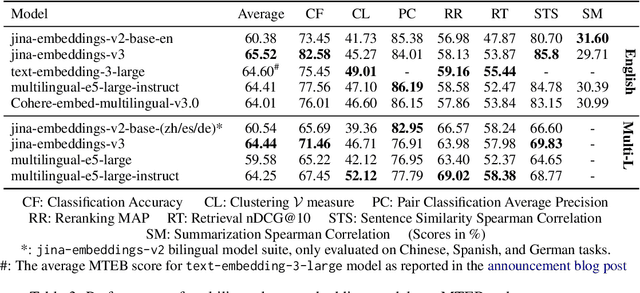
We introduce jina-embeddings-v3, a novel text embedding model with 570 million parameters, achieves state-of-the-art performance on multilingual data and long-context retrieval tasks, supporting context lengths of up to 8192 tokens. The model includes a set of task-specific Low-Rank Adaptation (LoRA) adapters to generate high-quality embeddings for query-document retrieval, clustering, classification, and text matching. Additionally, Matryoshka Representation Learning is integrated into the training process, allowing flexible truncation of embedding dimensions without compromising performance. Evaluation on the MTEB benchmark shows that jina-embeddings-v3 outperforms the latest proprietary embeddings from OpenAI and Cohere on English tasks, while achieving superior performance compared to multilingual-e5-large-instruct across all multilingual tasks.
Jina-ColBERT-v2: A General-Purpose Multilingual Late Interaction Retriever
Sep 04, 2024



Multi-vector dense models, such as ColBERT, have proven highly effective in information retrieval. ColBERT's late interaction scoring approximates the joint query-document attention seen in cross-encoders while maintaining inference efficiency closer to traditional dense retrieval models, thanks to its bi-encoder architecture and recent optimizations in indexing and search. In this paper, we introduce a novel architecture and a training framework to support long context window and multilingual retrieval. Our new model, Jina-ColBERT-v2, demonstrates strong performance across a range of English and multilingual retrieval tasks,
Jina CLIP: Your CLIP Model Is Also Your Text Retriever
May 30, 2024



Contrastive Language-Image Pretraining (CLIP) is widely used to train models to align images and texts in a common embedding space by mapping them to fixed-sized vectors. These models are key to multimodal information retrieval and related tasks. However, CLIP models generally underperform in text-only tasks compared to specialized text models. This creates inefficiencies for information retrieval systems that keep separate embeddings and models for text-only and multimodal tasks. We propose a novel, multi-task contrastive training method to address this issue, which we use to train the jina-clip-v1 model to achieve the state-of-the-art performance on both text-image and text-text retrieval tasks.
Multi-Task Contrastive Learning for 8192-Token Bilingual Text Embeddings
Feb 26, 2024



We introduce a novel suite of state-of-the-art bilingual text embedding models that are designed to support English and another target language. These models are capable of processing lengthy text inputs with up to 8192 tokens, making them highly versatile for a range of natural language processing tasks such as text retrieval, clustering, and semantic textual similarity (STS) calculations. By focusing on bilingual models and introducing a unique multi-task learning objective, we have significantly improved the model performance on STS tasks, which outperforms the capabilities of existing multilingual models in both target language understanding and cross-lingual evaluation tasks. Moreover, our bilingual models are more efficient, requiring fewer parameters and less memory due to their smaller vocabulary needs. Furthermore, we have expanded the Massive Text Embedding Benchmark (MTEB) to include benchmarks for German and Spanish embedding models. This integration aims to stimulate further research and advancement in text embedding technologies for these languages.