 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Order and World Knowledge
Mar 01, 2024



Word order is an important concept in natural language, and in this work, we study how word order affects the induction of world knowledge from raw text using language models. We use word analogies to probe for such knowledge. Specifically, in addition to the natural word order, we first respectively extract texts of six fixed word orders from five languages and then pretrain the language models on these texts. Finally, we analyze the experimental results of the fixed word orders on word analogies and show that i) certain fixed word orders consistently outperform or underperform others, though the specifics vary across languages, and ii) the Wov2Lex hypothesis is not hold in pre-trained language models, and the natural word order typically yields mediocre results. The source code will be made publicly available at https://github.com/lshowway/probing_by_analogy.
Multi-Task Contrastive Learning for 8192-Token Bilingual Text Embeddings
Feb 26, 2024



We introduce a novel suite of state-of-the-art bilingual text embedding models that are designed to support English and another target language. These models are capable of processing lengthy text inputs with up to 8192 tokens, making them highly versatile for a range of natural language processing tasks such as text retrieval, clustering, and semantic textual similarity (STS) calculations. By focusing on bilingual models and introducing a unique multi-task learning objective, we have significantly improved the model performance on STS tasks, which outperforms the capabilities of existing multilingual models in both target language understanding and cross-lingual evaluation tasks. Moreover, our bilingual models are more efficient, requiring fewer parameters and less memory due to their smaller vocabulary needs. Furthermore, we have expanded the Massive Text Embedding Benchmark (MTEB) to include benchmarks for German and Spanish embedding models. This integration aims to stimulate further research and advancement in text embedding technologies for these languages.
Word Order Does Matter (And Shuffled Language Models Know It)
Mar 21, 2022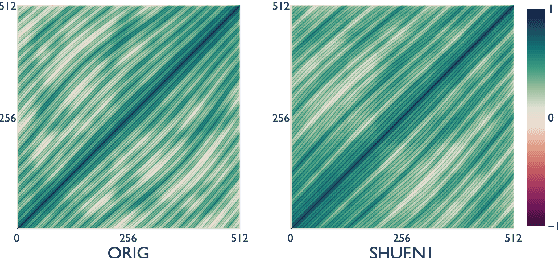
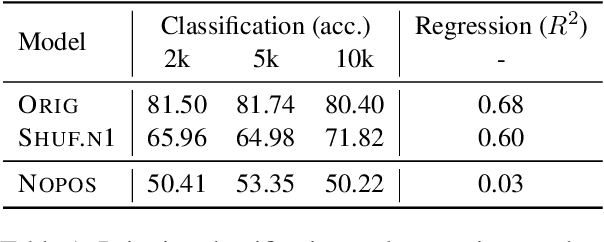
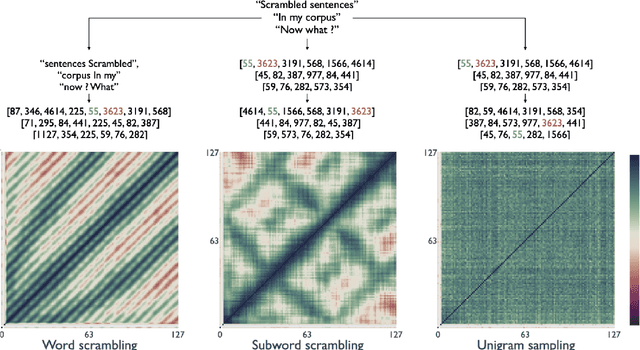
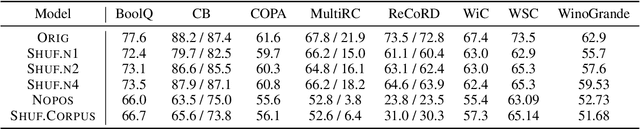
Recent studies have shown that language models pretrained and/or fine-tuned on randomly permuted sentences exhibit competitive performance on GLUE, putting into question the importance of word order information. Somewhat counter-intuitively, some of these studies also report that position embeddings appear to be crucial for models' good performance with shuffled text. We probe these language models for word order information and investigate what position embeddings learned from shuffled text encode, showing that these models retain information pertaining to the original, naturalistic word order. We show this is in part due to a subtlety in how shuffling is implemented in previous work -- before rather than after subword segmentation. Surprisingly, we find even Language models trained on text shuffled after subword segmentation retain some semblance of information about word order because of the statistical dependencies between sentence length and unigram probabilities. Finally, we show that beyond GLUE, a variety of language understanding tasks do require word order information, often to an extent that cannot be learned through fine-tuning.
The Impact of Positional Encodings on Multilingual Compression
Sep 11, 2021
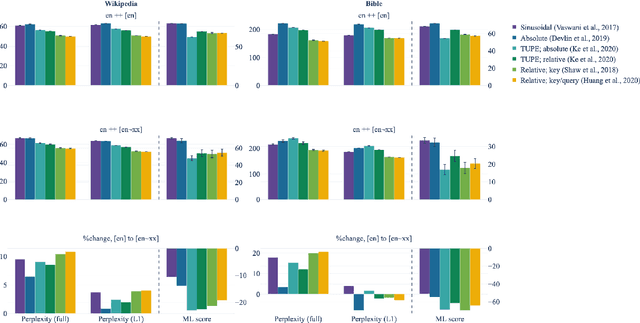


In order to preserve word-order information in a non-autoregressive setting, transformer architectures tend to include positional knowledge, by (for instance) adding positional encodings to token embeddings. Several modifications have been proposed over the sinusoidal positional encodings used in the original transformer architecture; these include, for instance, separating position encodings and token embeddings, or directly modifying attention weights based on the distance between word pairs. We first show that surprisingly, while these modifications tend to improve monolingual language models, none of them result in better multilingual language models. We then answer why that is: Sinusoidal encodings were explicitly designed to facilitate compositionality by allowing linear projections over arbitrary time steps. Higher variances in multilingual training distributions requires higher compression, in which case, compositionality becomes indispensable. Learned absolute positional encodings (e.g., in mBERT) tend to approximate sinusoidal embeddings in multilingual settings, but more complex positional encoding architectures lack the inductive bias to effectively learn compositionality and cross-lingual alignment. In other words, while sinusoidal positional encodings were originally designed for monolingual applications, they are particularly useful in multilingual language models.
Attention Can Reflect Syntactic Structure (If You Let It)
Jan 26, 2021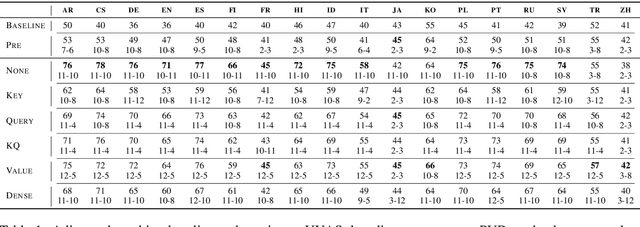
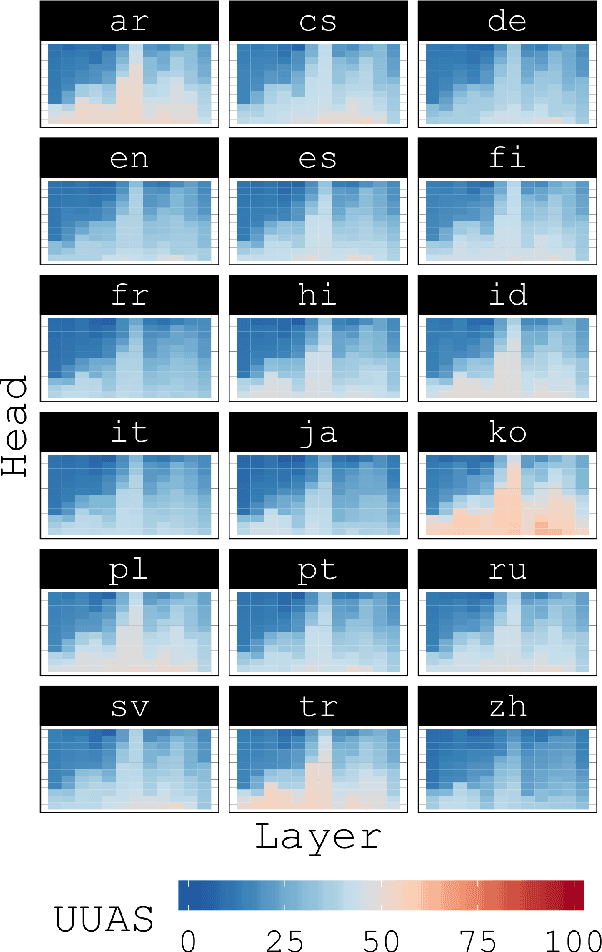
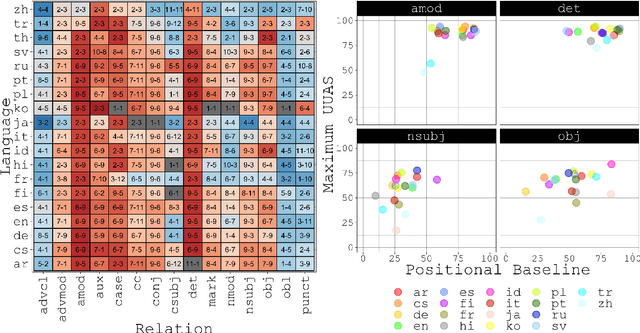
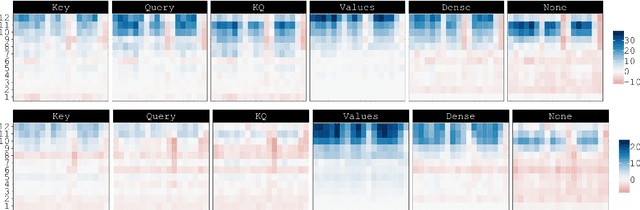
Since the popularization of the Transformer as a general-purpose feature encoder for NLP, many studies have attempted to decode linguistic structure from its novel multi-head attention mechanism. However, much of such work focused almost exclusively on English -- a language with rigid word order and a lack of inflectional morphology. In this study, we present decoding experiments for multilingual BERT across 18 languages in order to test the generalizability of the claim that dependency syntax is reflected in attention patterns. We show that full trees can be decoded above baseline accuracy from single attention heads, and that individual relations are often tracked by the same heads across languages. Furthermore, in an attempt to address recent debates about the status of attention as an explanatory mechanism, we experiment with fine-tuning mBERT on a supervised parsing objective while freezing different series of parameters. Interestingly, in steering the objective to learn explicit linguistic structure, we find much of the same structure represented in the resulting attention patterns, with interesting differences with respect to which parameters are frozen.
The Sensitivity of Language Models and Humans to Winograd Schema Perturbations
May 07, 2020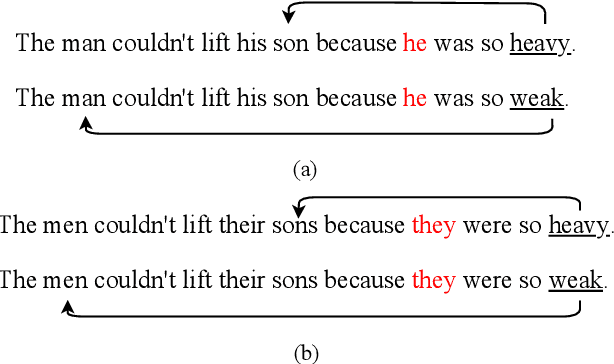

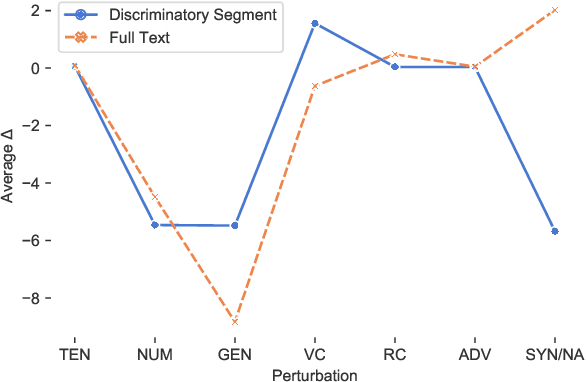
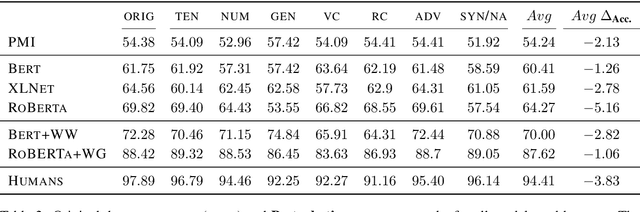
Large-scale pretrained language models are the major driving force behind recent improvements in performance on the Winograd Schema Challenge, a widely employed test of common sense reasoning ability. We show, however, with a new diagnostic dataset, that these models are sensitive to linguistic perturbations of the Winograd examples that minimally affect human understanding. Our results highlight interesting differences between humans and language models: language models are more sensitive to number or gender alternations and synonym replacements than humans, and humans are more stable and consistent in their predictions, maintain a much higher absolute performance, and perform better on non-associative instances than associative ones. Overall, humans are correct more often than out-of-the-box models, and the models are sometimes right for the wrong reasons. Finally, we show that fine-tuning on a large, task-specific dataset can offer a solution to these issues.
From Zero to Hero: On the Limitations of Zero-Shot Cross-Lingual Transfer with Multilingual Transformers
May 01, 2020
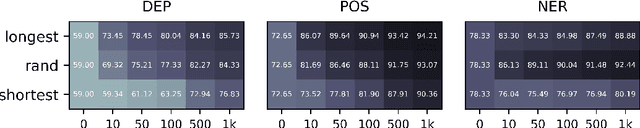
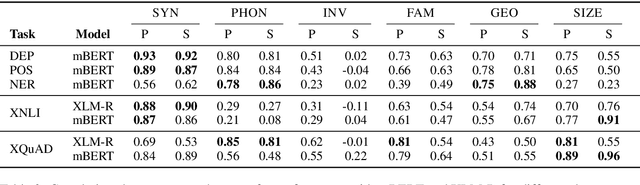
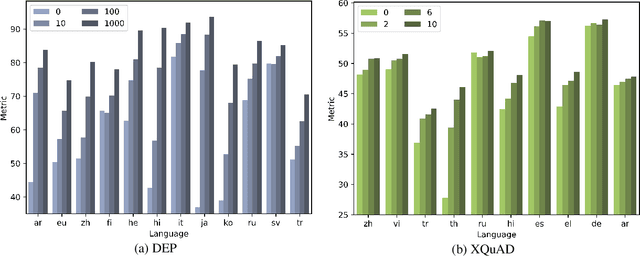
Massively multilingual transformers pretrained with language modeling objectives (e.g., mBERT, XLM-R) have become a de facto default transfer paradigm for zero-shot cross-lingual transfer in NLP, offering unmatched transfer performance. Current downstream evaluations, however, verify their efficacy predominantly in transfer settings involving languages with sufficient amounts of pretraining data, and with lexically and typologically close languages. In this work, we analyze their limitations and show that cross-lingual transfer via massively multilingual transformers, much like transfer via cross-lingual word embeddings, is substantially less effective in resource-lean scenarios and for distant languages. Our experiments, encompassing three lower-level tasks (POS tagging, dependency parsing, NER), as well as two high-level semantic tasks (NLI, QA), empirically correlate transfer performance with linguistic similarity between the source and target languages, but also with the size of pretraining corpora of target languages. We also demonstrate a surprising effectiveness of inexpensive few-shot transfer (i.e., fine-tuning on a few target-language instances after fine-tuning in the source) across the board. This suggests that additional research efforts should be invested to reach beyond the limiting zero-shot conditions.
Do Neural Language Models Show Preferences for Syntactic Formalisms?
Apr 29, 2020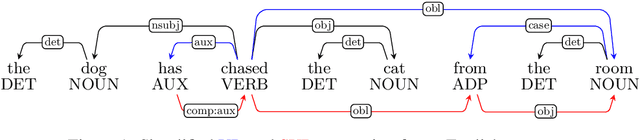
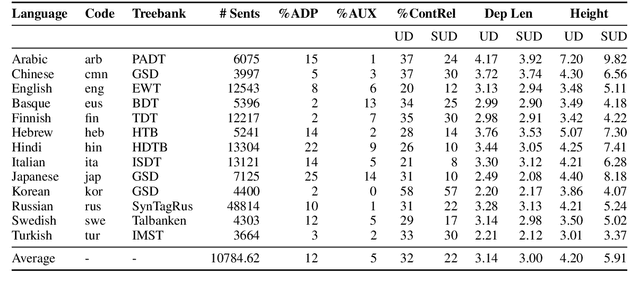


Recent work on the interpretability of deep neural language models has concluded that many properties of natural language syntax are encoded in their representational spaces. However, such studies often suffer from limited scope by focusing on a single language and a single linguistic formalism. In this study, we aim to investigate the extent to which the semblance of syntactic structure captured by language models adheres to a surface-syntactic or deep syntactic style of analysis, and whether the patterns are consistent across different languages. We apply a probe for extracting directed dependency trees to BERT and ELMo models trained on 13 different languages, probing for two different syntactic annotation styles: Universal Dependencies (UD), prioritizing deep syntactic relations, and Surface-Syntactic Universal Dependencies (SUD), focusing on surface structure. We find that both models exhibit a preference for UD over SUD - with interesting variations across languages and layers - and that the strength of this preference is correlated with differences in tree shape.
Hierarchical models vs. transfer learning for document-level sentiment classification
Feb 19, 2020
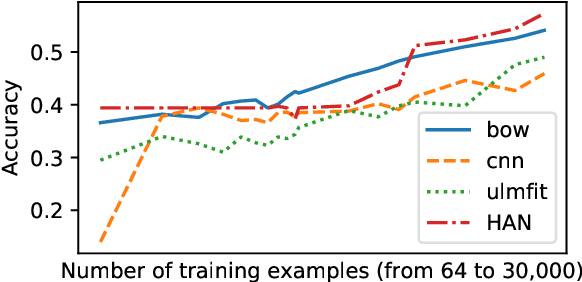

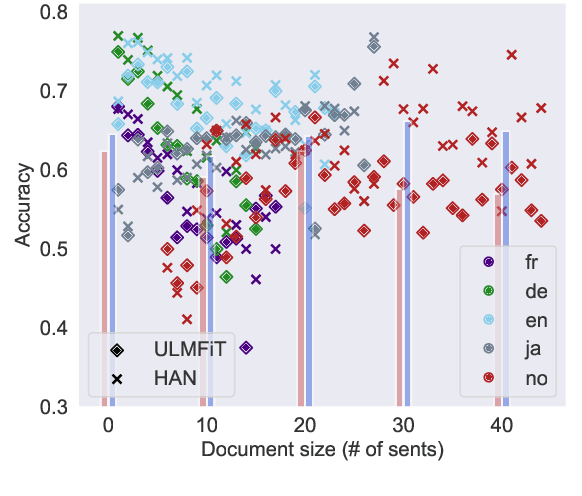
Documents are composed of smaller pieces - paragraphs, sentences, and tokens - that have complex relationships between one another. Sentiment classification models that take into account the structure inherent in these documents have a theoretical advantage over those that do not. At the same time, transfer learning models based on language model pretraining have shown promise for document classification. However, these two paradigms have not been systematically compared and it is not clear under which circumstances one approach is better than the other. In this work we empirically compare hierarchical models and transfer learning for document-level sentiment classification. We show that non-trivial hierarchical models outperform previous baselines and transfer learning on document-level sentiment classification in five languages.
Probing Multilingual Sentence Representations With X-Probe
Jun 12, 2019
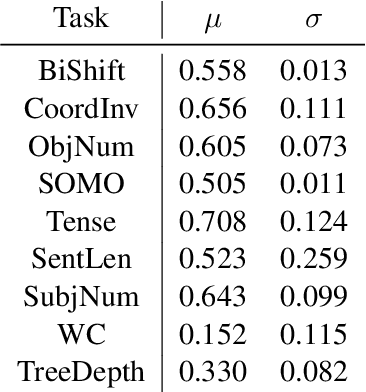

This paper extends the task of probing sentence representations for linguistic insight in a multilingual domain. In doing so, we make two contributions: first, we provide datasets for multilingual probing, derived from Wikipedia, in five languages, viz. English, French, German, Spanish and Russian. Second, we evaluate six sentence encoders for each language, each trained by mapping sentence representations to English sentence representations, using sentences in a parallel corpus. We discover that cross-lingually mapped representations are often better at retaining certain linguistic information than representations derived from English encoders trained on natural language inference (NLI) as a downstream task.