 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Models Struggle to Align Entities across Modalities
Mar 05, 2025Cross-modal entity linking refers to the ability to align entities and their attributes across different modalities. While cross-modal entity linking is a fundamental skill needed for real-world applications such as multimodal code generation, fake news detection, or scene understanding, it has not been thoroughly studied in the literature. In this paper, we introduce a new task and benchmark to address this gap. Our benchmark, MATE, consists of 5.5k evaluation instances featuring visual scenes aligned with their textual representations. To evaluate cross-modal entity linking performance, we design a question-answering task that involves retrieving one attribute of an object in one modality based on a unique attribute of that object in another modality. We evaluate state-of-the-art Vision-Language Models (VLMs) and humans on this task, and find that VLMs struggle significantly compared to humans, particularly as the number of objects in the scene increases. Our analysis also shows that, while chain-of-thought prompting can improve VLM performance, models remain far from achieving human-level proficiency. These findings highlight the need for further research in cross-modal entity linking and show that MATE is a strong benchmark to support that progress.
Conditioning LLMs to Generate Code-Switched Text: A Methodology Grounded in Naturally Occurring Data
Feb 18, 2025



Code-switching (CS) is still a critical challenge in Natural Language Processing (NLP). Current Large Language Models (LLMs) struggle to interpret and generate code-switched text, primarily due to the scarcity of large-scale CS datasets for training. This paper presents a novel methodology to generate CS data using LLMs, and test it on the English-Spanish language pair. We propose back-translating natural CS sentences into monolingual English, and using the resulting parallel corpus to fine-tune LLMs to turn monolingual sentences into CS. Unlike previous approaches to CS generation, our methodology uses natural CS data as a starting point, allowing models to learn its natural distribution beyond grammatical patterns. We thoroughly analyse the models' performance through a study on human preferences, a qualitative error analysis and an evaluation with popular automatic metrics. Results show that our methodology generates fluent code-switched text, expanding research opportunities in CS communication, and that traditional metrics do not correlate with human judgement when assessing the quality of the generated CS data. We release our code and generated dataset under a CC-BY-NC-SA license.
Truth Knows No Language: Evaluating Truthfulness Beyond English
Feb 13, 2025
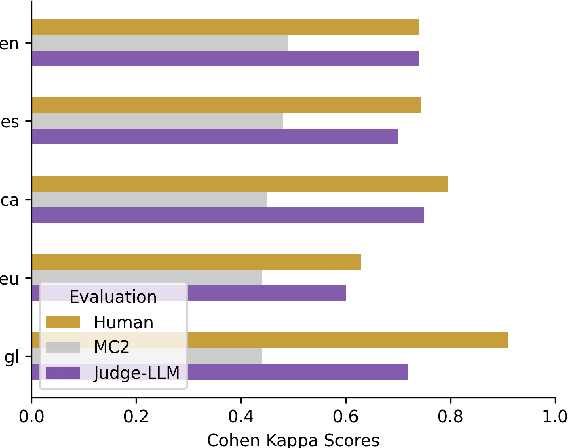
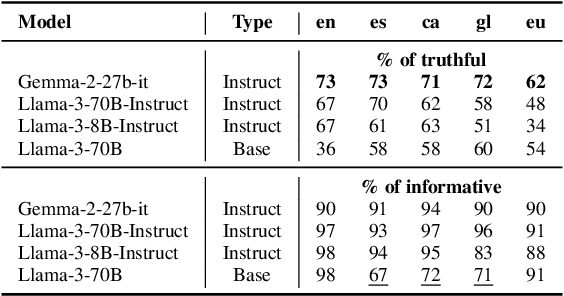
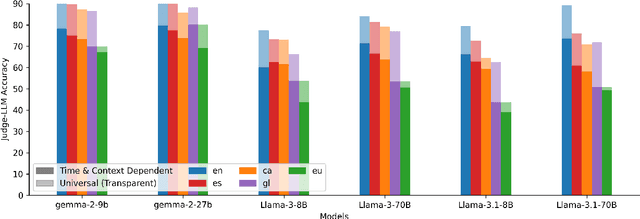
We introduce a professionally translated extension of the TruthfulQA benchmark designed to evaluate truthfulness in Basque, Catalan, Galician, and Spanish. Truthfulness evaluations of large language models (LLMs) have primarily been conducted in English. However, the ability of LLMs to maintain truthfulness across languages remains under-explored. Our study evaluates 12 state-of-the-art open LLMs, comparing base and instruction-tuned models using human evaluation, multiple-choice metrics, and LLM-as-a-Judge scoring. Our findings reveal that, while LLMs perform best in English and worst in Basque (the lowest-resourced language), overall truthfulness discrepancies across languages are smaller than anticipated. Furthermore, we show that LLM-as-a-Judge correlates more closely with human judgments than multiple-choice metrics, and that informativeness plays a critical role in truthfulness assessment. Our results also indicate that machine translation provides a viable approach for extending truthfulness benchmarks to additional languages, offering a scalable alternative to professional translation. Finally, we observe that universal knowledge questions are better handled across languages than context- and time-dependent ones, highlighting the need for truthfulness evaluations that account for cultural and temporal variability. Dataset and code are publicly available under open licenses.
EuskañolDS: A Naturally Sourced Corpus for Basque-Spanish Code-Switching
Feb 05, 2025
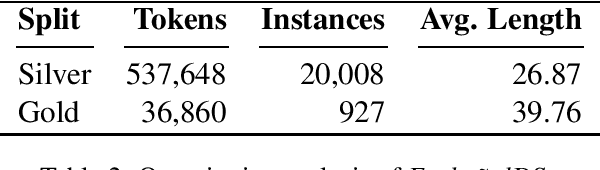

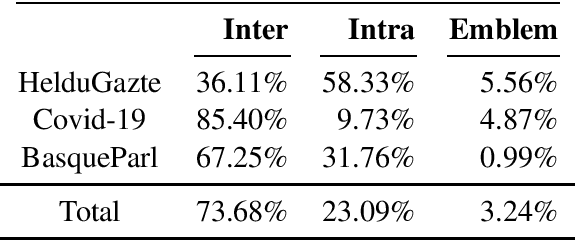
Code-switching (CS) remains a significant challenge in Natural Language Processing (NLP), mainly due a lack of relevant data. In the context of the contact between the Basque and Spanish languages in the north of the Iberian Peninsula, CS frequently occurs in both formal and informal spontaneous interactions. However, resources to analyse this phenomenon and support the development and evaluation of models capable of understanding and generating code-switched language for this language pair are almost non-existent. We introduce a first approach to develop a naturally sourced corpus for Basque-Spanish code-switching. Our methodology consists of identifying CS texts from previously available corpora using language identification models, which are then manually validated to obtain a reliable subset of CS instances. We present the properties of our corpus and make it available under the name Euska\~nolDS.
HiTZ at VarDial 2025 NorSID: Overcoming Data Scarcity with Language Transfer and Automatic Data Annotation
Dec 13, 2024In this paper we present our submission for the NorSID Shared Task as part of the 2025 VarDial Workshop (Scherrer et al., 2025), consisting of three tasks: Intent Detection, Slot Filling and Dialect Identification, evaluated using data in different dialects of the Norwegian language. For Intent Detection and Slot Filling, we have fine-tuned a multitask model in a cross-lingual setting, to leverage the xSID dataset available in 17 languages. In the case of Dialect Identification, our final submission consists of a model fine-tuned on the provided development set, which has obtained the highest scores within our experiments. Our final results on the test set show that our models do not drop in performance compared to the development set, likely due to the domain-specificity of the dataset and the similar distribution of both subsets. Finally, we also report an in-depth analysis of the provided datasets and their artifacts, as well as other sets of experiments that have been carried out but did not yield the best results. Additionally, we present an analysis on the reasons why some methods have been more successful than others; mainly the impact of the combination of languages and domain-specificity of the training data on the results.
XNLIeu: a dataset for cross-lingual NLI in Basque
Apr 10, 2024



XNLI is a popular Natural Language Inference (NLI) benchmark widely used to evaluate cross-lingual Natural Language Understanding (NLU) capabilities across languages. In this paper, we expand XNLI to include Basque, a low-resource language that can greatly benefit from transfer-learning approaches. The new dataset, dubbed XNLIeu, has been developed by first machine-translating the English XNLI corpus into Basque, followed by a manual post-edition step. We have conducted a series of experiments using mono- and multilingual LLMs to assess a) the effect of professional post-edition on the MT system; b) the best cross-lingual strategy for NLI in Basque; and c) whether the choice of the best cross-lingual strategy is influenced by the fact that the dataset is built by translation. The results show that post-edition is necessary and that the translate-train cross-lingual strategy obtains better results overall, although the gain is lower when tested in a dataset that has been built natively from scratch. Our code and datasets are publicly available under open licenses.
English Prompts are Better for NLI-based Zero-Shot Emotion Classification than Target-Language Prompts
Feb 05, 2024



Emotion classification in text is a challenging and subjective task, due to the involved cognitive inference processes that are required to interpret a textual stimulus. In addition, the set of emotion categories is highly domain-specific. For instance, literature analysis might require the use of aesthetic emotions (e.g., finding something beautiful), and social media analysis could benefit from fine-grained sets (e.g., separating anger from annoyance) in contrast to basic emotion categories. This renders the task an interesting field for zero-shot classifications, in which the label set is not known at model development time. Unfortunately, most resources for emotion analysis are English, and therefore, most studies on emotion analysis have been performed in English, including those that involve prompting language models for text labels. This leaves us with a research gap that we address in this paper: In which language should we prompt for emotion labels on non-English texts? This is particularly of interest when we have access to a multilingual large language model, because we could request labels with English prompts even for non-English data. Our experiments with natural language inference-based language models show that it is consistently better to use English prompts even if the data is in a different language.
Annotating Norwegian Language Varieties on Twitter for Part-of-Speech
Oct 12, 2022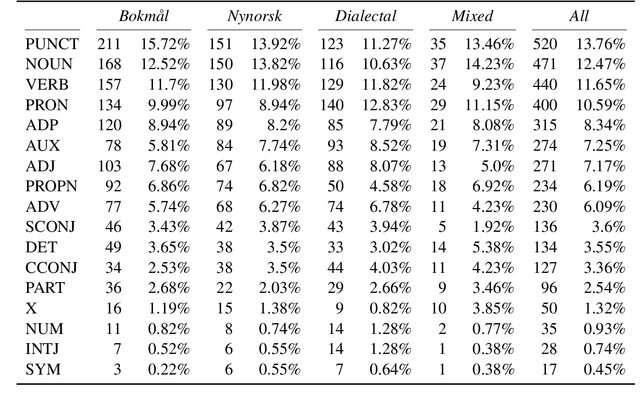
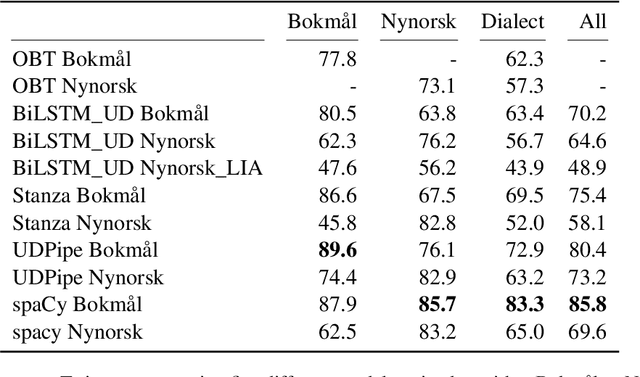
Norwegian Twitter data poses an interesting challenge for Natural Language Processing (NLP) tasks. These texts are difficult for models trained on standardized text in one of the two Norwegian written forms (Bokm{\aa}l and Nynorsk), as they contain both the typical variation of social media text, as well as a large amount of dialectal variety. In this paper we present a novel Norwegian Twitter dataset annotated with POS-tags. We show that models trained on Universal Dependency (UD) data perform worse when evaluated against this dataset, and that models trained on Bokm{\aa}l generally perform better than those trained on Nynorsk. We also see that performance on dialectal tweets is comparable to the written standards for some models. Finally we perform a detailed analysis of the errors that models commonly make on this data.
Direct parsing to sentiment graphs
Mar 24, 2022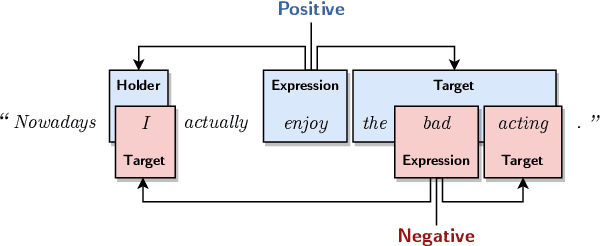
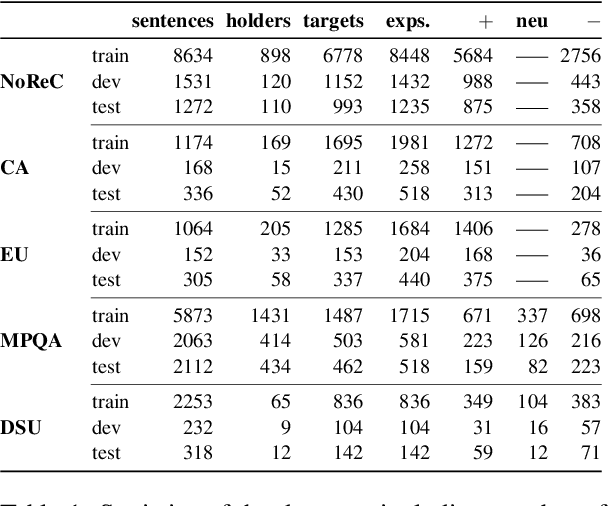
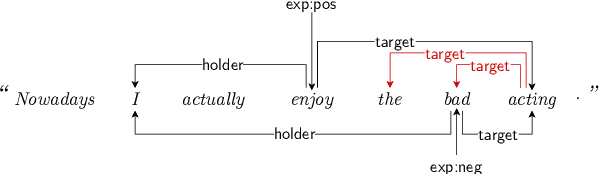
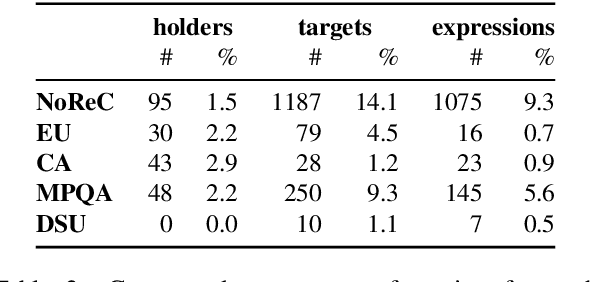
This paper demonstrates how a graph-based semantic parser can be applied to the task of structured sentiment analysis, directly predicting sentiment graphs from text. We advance the state of the art on 4 out of 5 standard benchmark sets. We release the source code, models and predictions.
The interplay between language similarity and script on a novel multi-layer Algerian dialect corpus
May 31, 2021
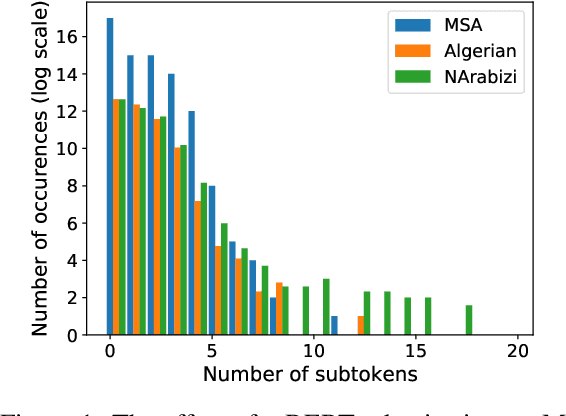
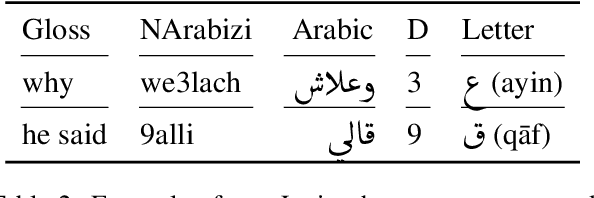
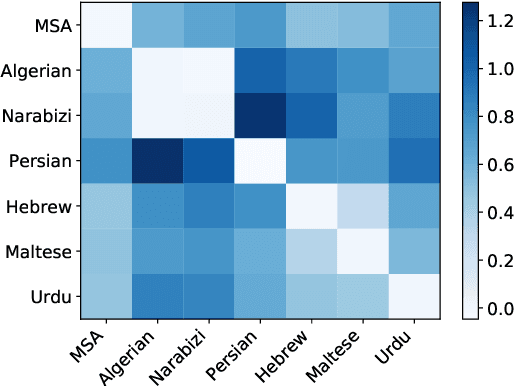
Recent years have seen a rise in interest for cross-lingual transfer between languages with similar typology, and between languages of various scripts. However, the interplay between language similarity and difference in script on cross-lingual transfer is a less studied problem. We explore this interplay on cross-lingual transfer for two supervised tasks, namely part-of-speech tagging and sentiment analysis. We introduce a newly annotated corpus of Algerian user-generated comments comprising parallel annotations of Algerian written in Latin, Arabic, and code-switched scripts, as well as annotations for sentiment and topic categories. We perform baseline experiments by fine-tuning multi-lingual language models. We further explore the effect of script vs. language similarity in cross-lingual transfer by fine-tuning multi-lingual models on languages which are a) typologically distinct, but use the same script, b) typologically similar, but use a distinct script, or c) are typologically similar and use the same script. We find there is a delicate relationship between script and typology for part-of-speech, while sentiment analysis is less sensitive.