 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePipeline Analysis for Developing Instruct LLMs in Low-Resource Languages: A Case Study on Basque
Dec 18, 2024Large language models (LLMs) are typically optimized for resource-rich languages like English, exacerbating the gap between high-resource and underrepresented languages. This work presents a detailed analysis of strategies for developing a model capable of following instructions in a low-resource language, specifically Basque, by focusing on three key stages: pre-training, instruction tuning, and alignment with human preferences. Our findings demonstrate that continual pre-training with a high-quality Basque corpus of around 600 million words improves natural language understanding (NLU) of the foundational model by over 12 points. Moreover, instruction tuning and human preference alignment using automatically translated datasets proved highly effective, resulting in a 24-point improvement in instruction-following performance. The resulting models, Llama-eus-8B and Llama-eus-8B-instruct, establish a new state-of-the-art for Basque in the sub-10B parameter category.
XNLIeu: a dataset for cross-lingual NLI in Basque
Apr 10, 2024



XNLI is a popular Natural Language Inference (NLI) benchmark widely used to evaluate cross-lingual Natural Language Understanding (NLU) capabilities across languages. In this paper, we expand XNLI to include Basque, a low-resource language that can greatly benefit from transfer-learning approaches. The new dataset, dubbed XNLIeu, has been developed by first machine-translating the English XNLI corpus into Basque, followed by a manual post-edition step. We have conducted a series of experiments using mono- and multilingual LLMs to assess a) the effect of professional post-edition on the MT system; b) the best cross-lingual strategy for NLI in Basque; and c) whether the choice of the best cross-lingual strategy is influenced by the fact that the dataset is built by translation. The results show that post-edition is necessary and that the translate-train cross-lingual strategy obtains better results overall, although the gain is lower when tested in a dataset that has been built natively from scratch. Our code and datasets are publicly available under open licenses.
Give your Text Representation Models some Love: the Case for Basque
Apr 02, 2020
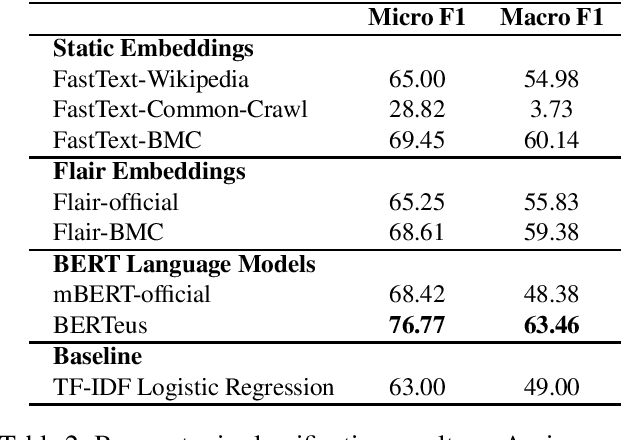
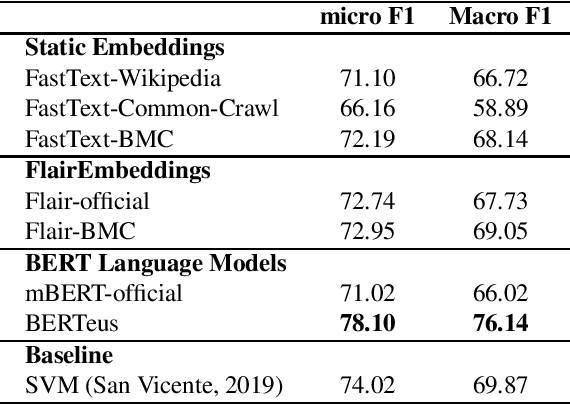
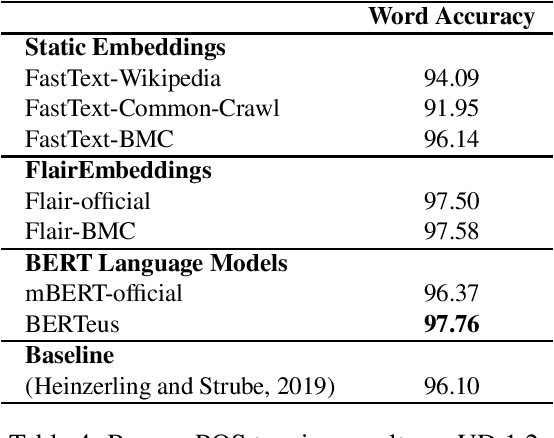
Word embeddings and pre-trained language models allow to build rich representations of text and have enabled improvements across most NLP tasks. Unfortunately they are very expensive to train, and many small companies and research groups tend to use models that have been pre-trained and made available by third parties, rather than building their own. This is suboptimal as, for many languages, the models have been trained on smaller (or lower quality) corpora. In addition, monolingual pre-trained models for non-English languages are not always available. At best, models for those languages are included in multilingual versions, where each language shares the quota of substrings and parameters with the rest of the languages. This is particularly true for smaller languages such as Basque. In this paper we show that a number of monolingual models (FastText word embeddings, FLAIR and BERT language models) trained with larger Basque corpora produce much better results than publicly available versions in downstream NLP tasks, including topic classification, sentiment classification, PoS tagging and NER. This work sets a new state-of-the-art in those tasks for Basque. All benchmarks and models used in this work are publicly available.
Talaia: a Real time Monitor of Social Media and Digital Press
Sep 28, 2018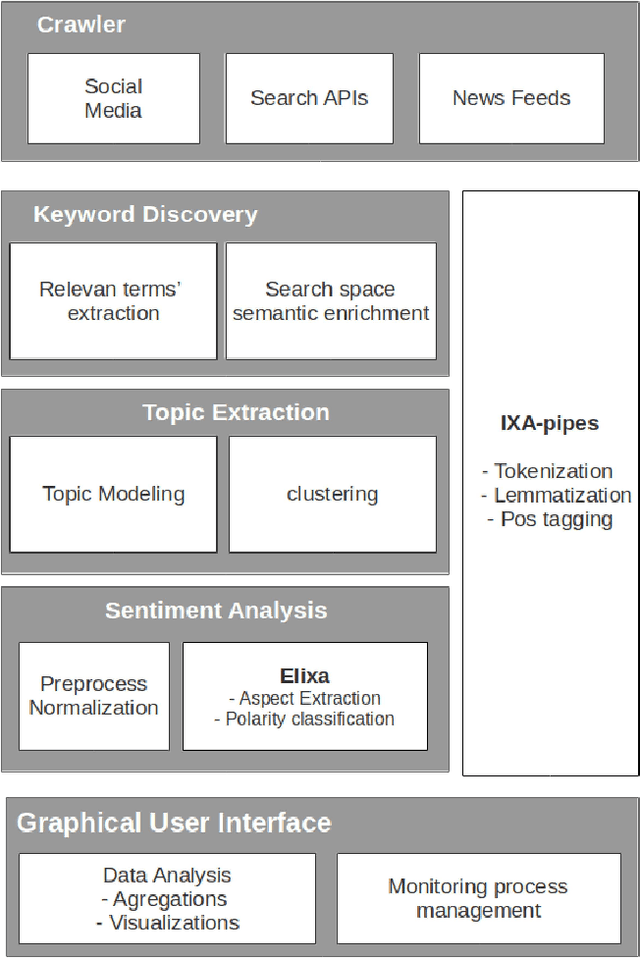

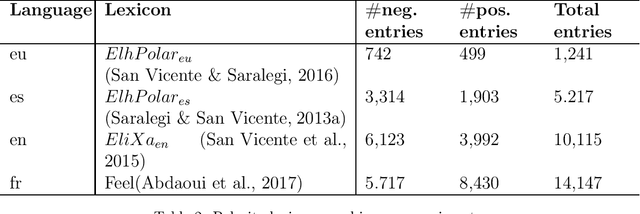
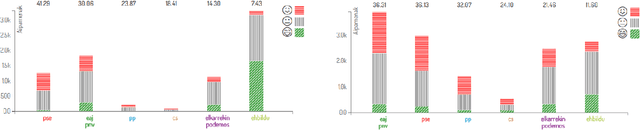
Talaia is a platform for monitoring social media and digital press. A configurable crawler gathers content with respect to user defined domains or topics. Crawled data is processed by means of IXA-pipes NLP chain and EliXa sentiment analysis system. A Django powered interface provides data visualization to provide the user analysis of the data. This paper presents the architecture of the system and describes in detail the different components of the system. To prove the validity of the approach, two real use cases are accounted for, one in the cultural domain and one in the political domain. Evaluation for the sentiment analysis task in both scenarios is also provided, showing the capacity for domain adaptation.
EliXa: A Modular and Flexible ABSA Platform
Feb 07, 2017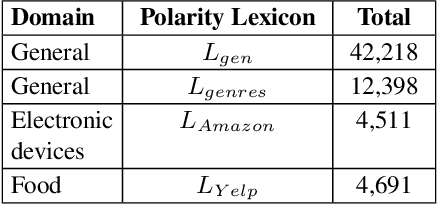
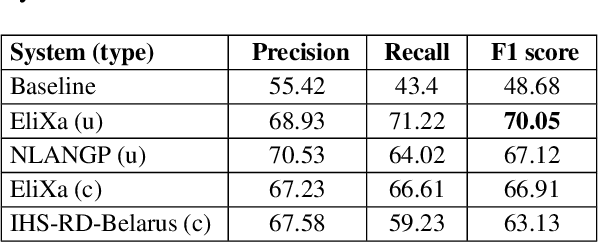
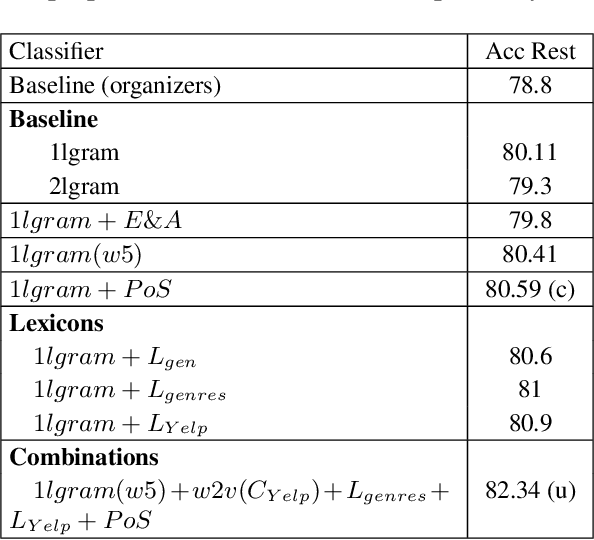
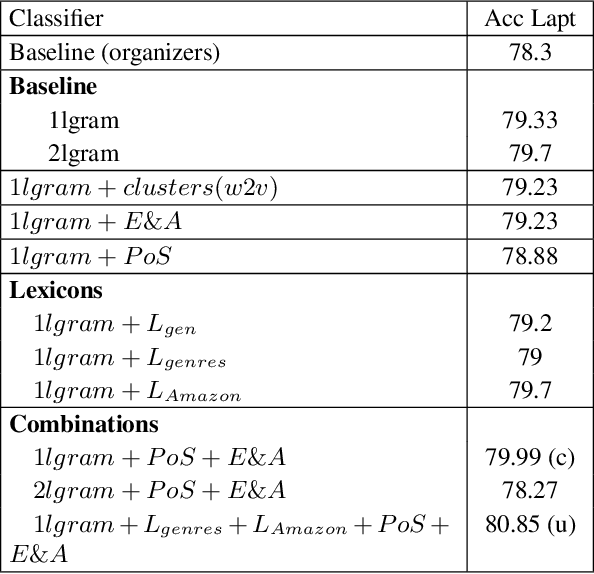
This paper presents a supervised Aspect Based Sentiment Analysis (ABSA) system. Our aim is to develop a modular platform which allows to easily conduct experiments by replacing the modules or adding new features. We obtain the best result in the Opinion Target Extraction (OTE) task (slot 2) using an off-the-shelf sequence labeler. The target polarity classification (slot 3) is addressed by means of a multiclass SVM algorithm which includes lexical based features such as the polarity values obtained from domain and open polarity lexicons. The system obtains accuracies of 0.70 and 0.73 for the restaurant and laptop domain respectively, and performs second best in the out-of-domain hotel, achieving an accuracy of 0.80.
* 5 pages, conference