 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructing Large Language Models for Low-Resource Languages: A Systematic Study for Basque
Jun 09, 2025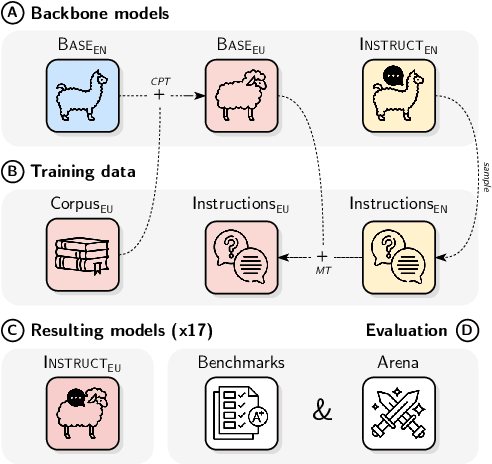
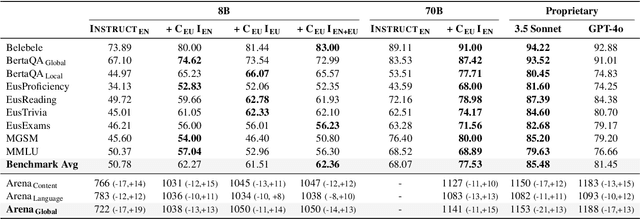
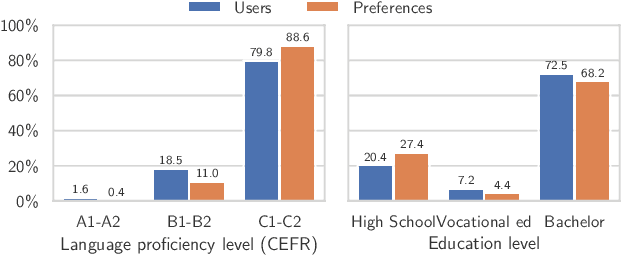

Instructing language models with user intent requires large instruction datasets, which are only available for a limited set of languages. In this paper, we explore alternatives to conventional instruction adaptation pipelines in low-resource scenarios. We assume a realistic scenario for low-resource languages, where only the following are available: corpora in the target language, existing open-weight multilingual base and instructed backbone LLMs, and synthetically generated instructions sampled from the instructed backbone. We present a comprehensive set of experiments for Basque that systematically study different combinations of these components evaluated on benchmarks and human preferences from 1,680 participants. Our conclusions show that target language corpora are essential, with synthetic instructions yielding robust models, and, most importantly, that using as backbone an instruction-tuned model outperforms using a base non-instructed model, and improved results when scaling up. Using Llama 3.1 instruct 70B as backbone our model comes near frontier models of much larger sizes for Basque, without using any Basque data apart from the 1.2B word corpora. We release code, models, instruction datasets, and human preferences to support full reproducibility in future research on low-resource language adaptation.
Conditioning LLMs to Generate Code-Switched Text: A Methodology Grounded in Naturally Occurring Data
Feb 18, 2025



Code-switching (CS) is still a critical challenge in Natural Language Processing (NLP). Current Large Language Models (LLMs) struggle to interpret and generate code-switched text, primarily due to the scarcity of large-scale CS datasets for training. This paper presents a novel methodology to generate CS data using LLMs, and test it on the English-Spanish language pair. We propose back-translating natural CS sentences into monolingual English, and using the resulting parallel corpus to fine-tune LLMs to turn monolingual sentences into CS. Unlike previous approaches to CS generation, our methodology uses natural CS data as a starting point, allowing models to learn its natural distribution beyond grammatical patterns. We thoroughly analyse the models' performance through a study on human preferences, a qualitative error analysis and an evaluation with popular automatic metrics. Results show that our methodology generates fluent code-switched text, expanding research opportunities in CS communication, and that traditional metrics do not correlate with human judgement when assessing the quality of the generated CS data. We release our code and generated dataset under a CC-BY-NC-SA license.
EuskañolDS: A Naturally Sourced Corpus for Basque-Spanish Code-Switching
Feb 05, 2025
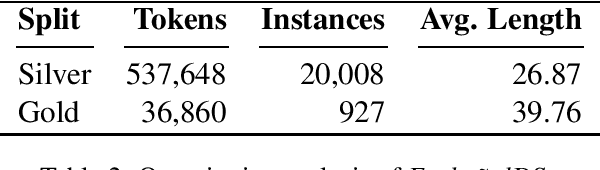

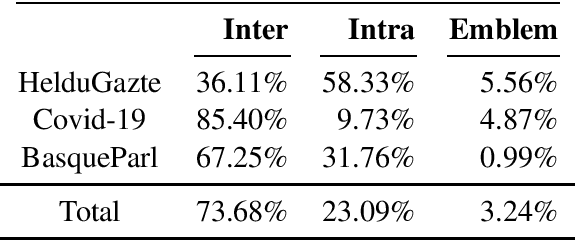
Code-switching (CS) remains a significant challenge in Natural Language Processing (NLP), mainly due a lack of relevant data. In the context of the contact between the Basque and Spanish languages in the north of the Iberian Peninsula, CS frequently occurs in both formal and informal spontaneous interactions. However, resources to analyse this phenomenon and support the development and evaluation of models capable of understanding and generating code-switched language for this language pair are almost non-existent. We introduce a first approach to develop a naturally sourced corpus for Basque-Spanish code-switching. Our methodology consists of identifying CS texts from previously available corpora using language identification models, which are then manually validated to obtain a reliable subset of CS instances. We present the properties of our corpus and make it available under the name Euska\~nolDS.
A LLM-Based Ranking Method for the Evaluation of Automatic Counter-Narrative Generation
Jun 21, 2024
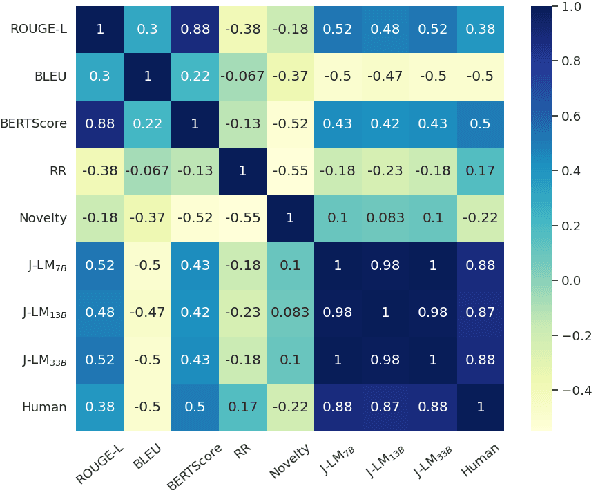


The proliferation of misinformation and harmful narratives in online discourse has underscored the critical need for effective Counter Narrative (CN) generation techniques. However, existing automatic evaluation methods often lack interpretability and fail to capture the nuanced relationship between generated CNs and human perception. Aiming to achieve a higher correlation with human judgments, this paper proposes a novel approach to asses generated CNs that consists on the use of a Large Language Model (LLM) as a evaluator. By comparing generated CNs pairwise in a tournament-style format, we establish a model ranking pipeline that achieves a correlation of $0.88$ with human preference. As an additional contribution, we leverage LLMs as zero-shot (ZS) CN generators and conduct a comparative analysis of chat, instruct, and base models, exploring their respective strengths and limitations. Through meticulous evaluation, including fine-tuning experiments, we elucidate the differences in performance and responsiveness to domain-specific data. We conclude that chat-aligned models in ZS are the best option for carrying out the task, provided they do not refuse to generate an answer due to security concerns.
BertaQA: How Much Do Language Models Know About Local Culture?
Jun 11, 2024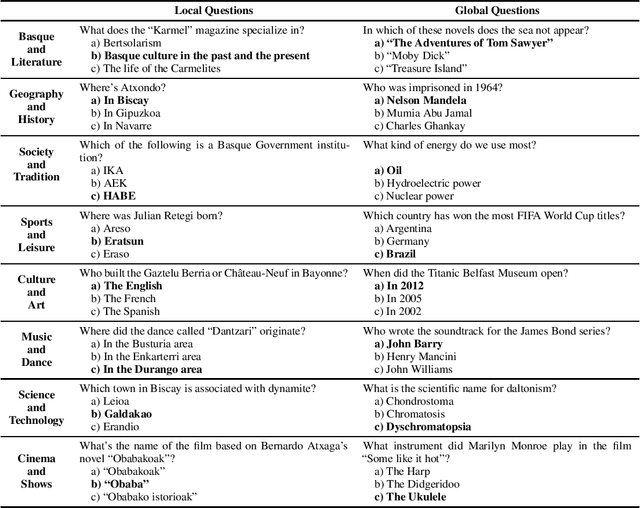
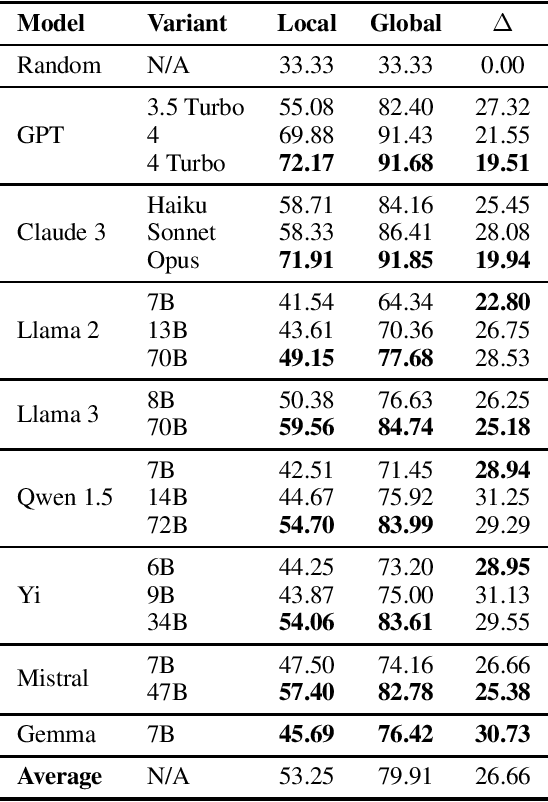
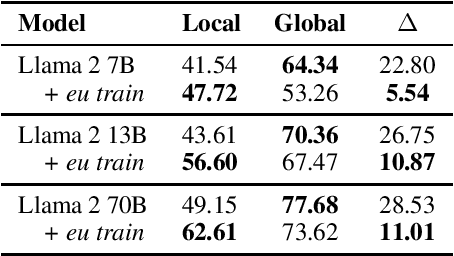
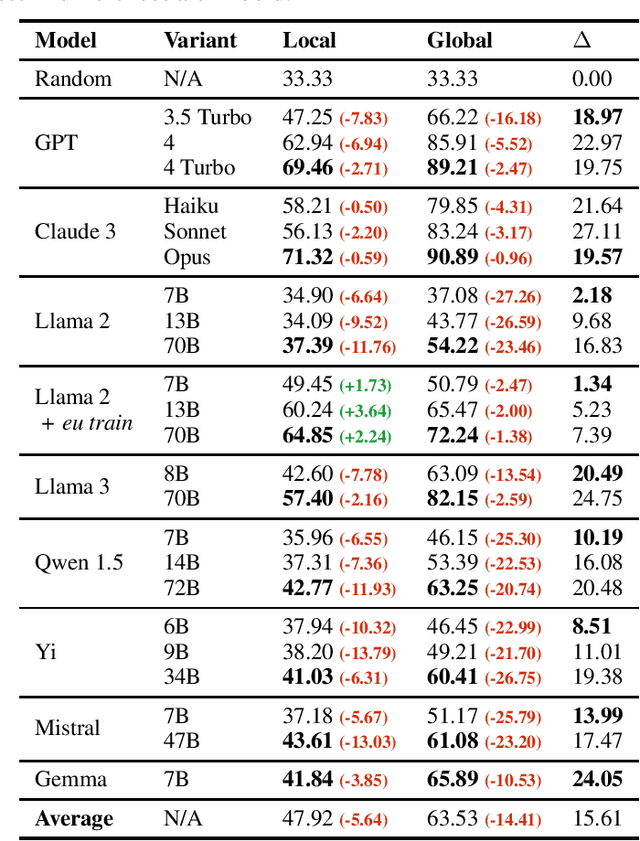
Large Language Models (LLMs) exhibit extensive knowledge about the world, but most evaluations have been limited to global or anglocentric subjects. This raises the question of how well these models perform on topics relevant to other cultures, whose presence on the web is not that prominent. To address this gap, we introduce BertaQA, a multiple-choice trivia dataset that is parallel in English and Basque. The dataset consists of a local subset with questions pertinent to the Basque culture, and a global subset with questions of broader interest. We find that state-of-the-art LLMs struggle with local cultural knowledge, even as they excel on global topics. However, we show that continued pre-training in Basque significantly improves the models' performance on Basque culture, even when queried in English. To our knowledge, this is the first solid evidence of knowledge transfer from a low-resource to a high-resource language. Our analysis sheds light on the complex interplay between language and knowledge, and reveals that some prior findings do not fully hold when reassessed on local topics. Our dataset and evaluation code are available under open licenses at https://github.com/juletx/BertaQA.
XNLIeu: a dataset for cross-lingual NLI in Basque
Apr 10, 2024



XNLI is a popular Natural Language Inference (NLI) benchmark widely used to evaluate cross-lingual Natural Language Understanding (NLU) capabilities across languages. In this paper, we expand XNLI to include Basque, a low-resource language that can greatly benefit from transfer-learning approaches. The new dataset, dubbed XNLIeu, has been developed by first machine-translating the English XNLI corpus into Basque, followed by a manual post-edition step. We have conducted a series of experiments using mono- and multilingual LLMs to assess a) the effect of professional post-edition on the MT system; b) the best cross-lingual strategy for NLI in Basque; and c) whether the choice of the best cross-lingual strategy is influenced by the fact that the dataset is built by translation. The results show that post-edition is necessary and that the translate-train cross-lingual strategy obtains better results overall, although the gain is lower when tested in a dataset that has been built natively from scratch. Our code and datasets are publicly available under open licenses.
Latxa: An Open Language Model and Evaluation Suite for Basque
Mar 29, 2024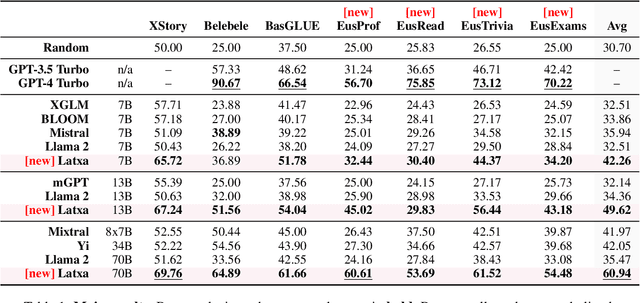
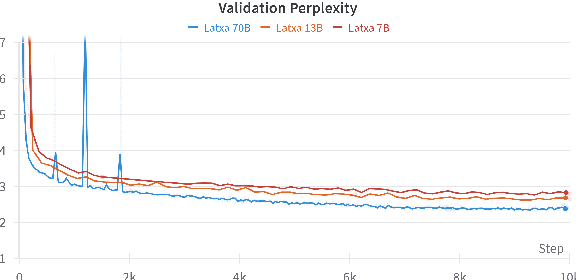
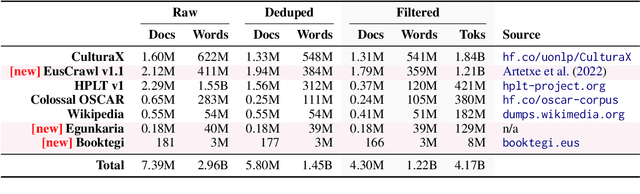
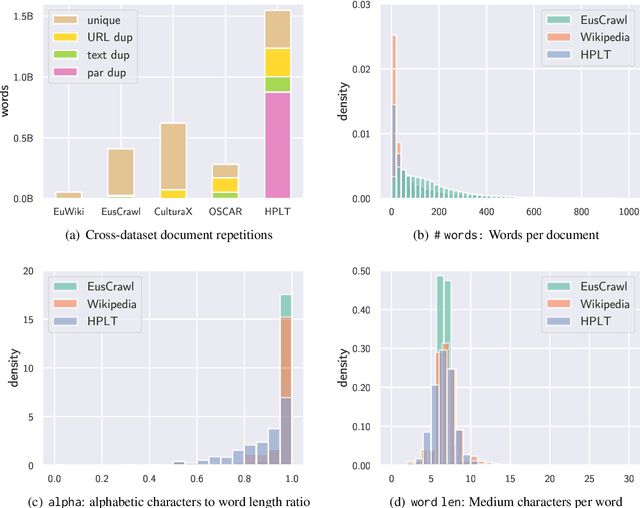
We introduce Latxa, a family of large language models for Basque ranging from 7 to 70 billion parameters. Latxa is based on Llama 2, which we continue pretraining on a new Basque corpus comprising 4.3M documents and 4.2B tokens. Addressing the scarcity of high-quality benchmarks for Basque, we further introduce 4 multiple choice evaluation datasets: EusProficiency, comprising 5,169 questions from official language proficiency exams; EusReading, comprising 352 reading comprehension questions; EusTrivia, comprising 1,715 trivia questions from 5 knowledge areas; and EusExams, comprising 16,774 questions from public examinations. In our extensive evaluation, Latxa outperforms all previous open models we compare to by a large margin. In addition, it is competitive with GPT-4 Turbo in language proficiency and understanding, despite lagging behind in reading comprehension and knowledge-intensive tasks. Both the Latxa family of models, as well as our new pretraining corpora and evaluation datasets, are publicly available under open licenses at https://github.com/hitz-zentroa/latxa. Our suite enables reproducible research on methods to build LLMs for low-resource languages.
Improving Explicit Spatial Relationships in Text-to-Image Generation through an Automatically Derived Dataset
Mar 01, 2024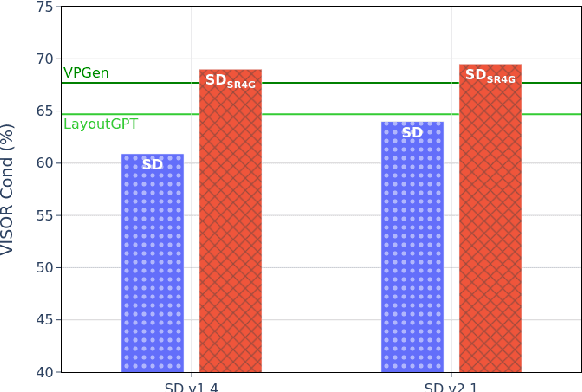
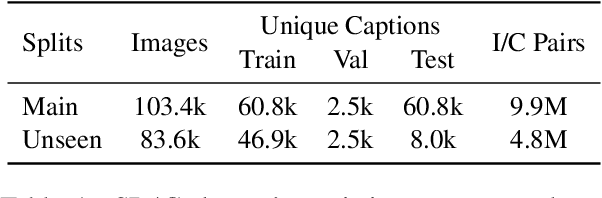

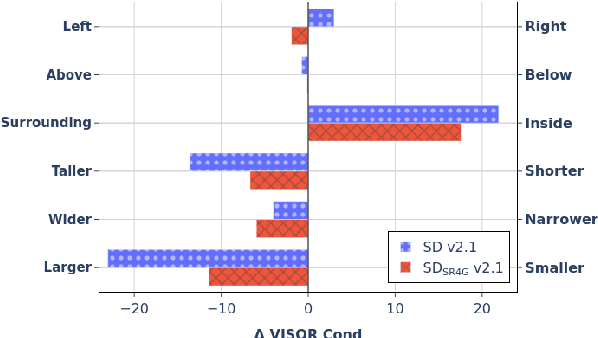
Existing work has observed that current text-to-image systems do not accurately reflect explicit spatial relations between objects such as 'left of' or 'below'. We hypothesize that this is because explicit spatial relations rarely appear in the image captions used to train these models. We propose an automatic method that, given existing images, generates synthetic captions that contain 14 explicit spatial relations. We introduce the Spatial Relation for Generation (SR4G) dataset, which contains 9.9 millions image-caption pairs for training, and more than 60 thousand captions for evaluation. In order to test generalization we also provide an 'unseen' split, where the set of objects in the train and test captions are disjoint. SR4G is the first dataset that can be used to spatially fine-tune text-to-image systems. We show that fine-tuning two different Stable Diffusion models (denoted as SD$_{SR4G}$) yields up to 9 points improvements in the VISOR metric. The improvement holds in the 'unseen' split, showing that SD$_{SR4G}$ is able to generalize to unseen objects. SD$_{SR4G}$ improves the state-of-the-art with fewer parameters, and avoids complex architectures. Our analysis shows that improvement is consistent for all relations. The dataset and the code will be publicly available.
Do Multilingual Language Models Think Better in English?
Aug 02, 2023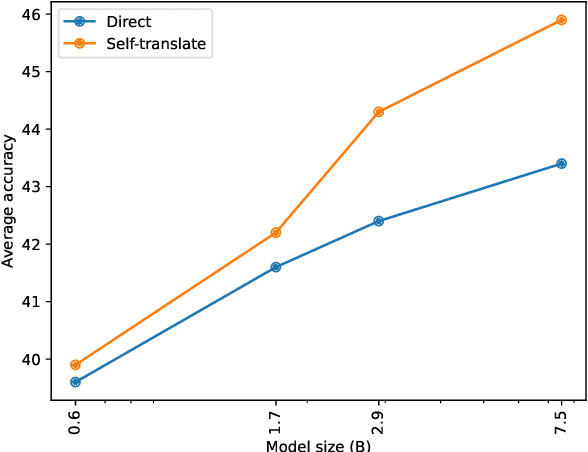

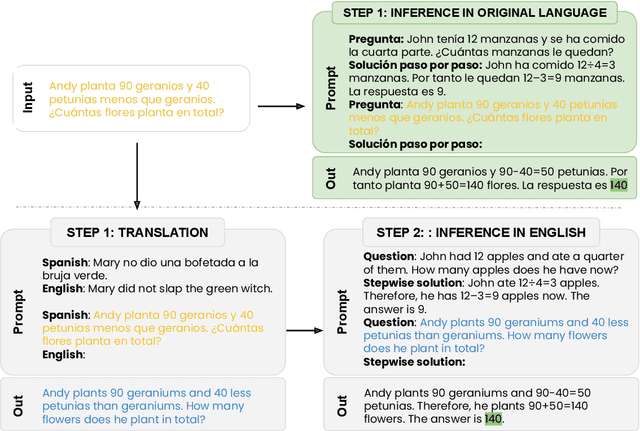

Translate-test is a popular technique to improve the performance of multilingual language models. This approach works by translating the input into English using an external machine translation system, and running inference over the translated input. However, these improvements can be attributed to the use of a separate translation system, which is typically trained on large amounts of parallel data not seen by the language model. In this work, we introduce a new approach called self-translate, which overcomes the need of an external translation system by leveraging the few-shot translation capabilities of multilingual language models. Experiments over 5 tasks show that self-translate consistently outperforms direct inference, demonstrating that language models are unable to leverage their full multilingual potential when prompted in non-English languages. Our code is available at https://github.com/juletx/self-translate.
The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset
Mar 07, 2023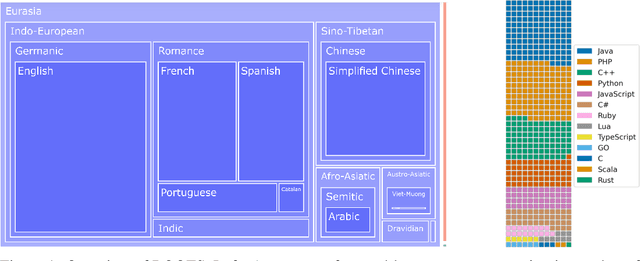

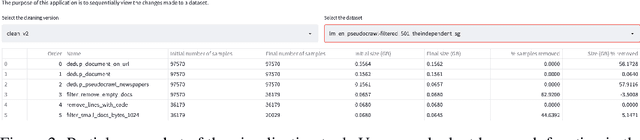

As language models grow ever larger, the need for large-scale high-quality text datasets has never been more pressing, especially in multilingual settings. The BigScience workshop, a 1-year international and multidisciplinary initiative, was formed with the goal of researching and training large language models as a values-driven undertaking, putting issues of ethics, harm, and governance in the foreground. This paper documents the data creation and curation efforts undertaken by BigScience to assemble the Responsible Open-science Open-collaboration Text Sources (ROOTS) corpus, a 1.6TB dataset spanning 59 languages that was used to train the 176-billion-parameter BigScience Large Open-science Open-access Multilingual (BLOOM) language model. We further release a large initial subset of the corpus and analyses thereof, and hope to empower large-scale monolingual and multilingual modeling projects with both the data and the processing tools, as well as stimulate research around this large multilingual corpus.