 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Compositionality in Dual-Encoder Vision-Language Models: The Role of Inference
Apr 13, 2026Dual-encoder Vision-Language Models (VLMs) such as CLIP are often characterized as bag-of-words systems due to their poor performance on compositional benchmarks. We argue that this limitation may stem less from deficient representations than from the standard inference protocol based on global cosine similarity. First, through controlled diagnostic experiments, we show that explicitly enforcing fine-grained region-segment alignment at inference dramatically improves compositional performance without updating pretrained encoders. We then introduce a lightweight transformer that learns such alignments directly from frozen patch and token embeddings. Comparing against full fine-tuning and prior end-to-end compositional training methods, we find that although these approaches improve in-domain retrieval, their gains do not consistently transfer under distribution shift. In contrast, learning localized alignment over frozen representations matches full fine-tuning on in-domain retrieval while yielding substantial improvements on controlled out-of-domain compositional benchmarks. These results identify global embedding matching as a key bottleneck in dual-encoder VLMs and highlight the importance of alignment mechanisms for robust compositional generalization.
Do not be greedy, Think Twice: Sampling and Selection for Document-level Information Extraction
Jan 26, 2026Document-level Information Extraction (DocIE) aims to produce an output template with the entities and relations of interest occurring in the given document. Standard practices include prompting decoder-only LLMs using greedy decoding to avoid output variability. Rather than treating this variability as a limitation, we show that sampling can produce substantially better solutions than greedy decoding, especially when using reasoning models. We thus propose ThinkTwice, a sampling and selection framework in which the LLM generates multiple candidate templates for a given document, and a selection module chooses the most suitable one. We introduce both an unsupervised method that exploits agreement across generated outputs, and a supervised selection method using reward models trained on labeled DocIE data. To address the scarcity of golden reasoning trajectories for DocIE, we propose a rejection-sampling-based method to generate silver training data that pairs output templates with reasoning traces. Our experiments show the validity of unsupervised and supervised ThinkTwice, consistently outperforming greedy baselines and the state-of-the-art.
Adding simple structure at inference improves Vision-Language Compositionality
Jun 11, 2025Dual encoder Vision-Language Models (VLM) such as CLIP are widely used for image-text retrieval tasks. However, those models struggle with compositionality, showing a bag-of-words-like behavior that limits their retrieval performance. Many different training approaches have been proposed to improve the vision-language compositionality capabilities of those models. In comparison, inference-time techniques have received little attention. In this paper, we propose to add simple structure at inference, where, given an image and a caption: i) we divide the image into different smaller crops, ii) we extract text segments, capturing objects, attributes and relations, iii) using a VLM, we find the image crops that better align with text segments obtaining matches, and iv) we compute the final image-text similarity aggregating the individual similarities of the matches. Based on various popular dual encoder VLMs, we evaluate our approach in controlled and natural datasets for VL compositionality. We find that our approach consistently improves the performance of evaluated VLMs without any training, which shows the potential of inference-time techniques. The results are especially good for attribute-object binding as shown in the controlled dataset. As a result of an extensive analysis: i) we show that processing image crops is actually essential for the observed gains in performance, and ii) we identify specific areas to further improve inference-time approaches.
Instructing Large Language Models for Low-Resource Languages: A Systematic Study for Basque
Jun 09, 2025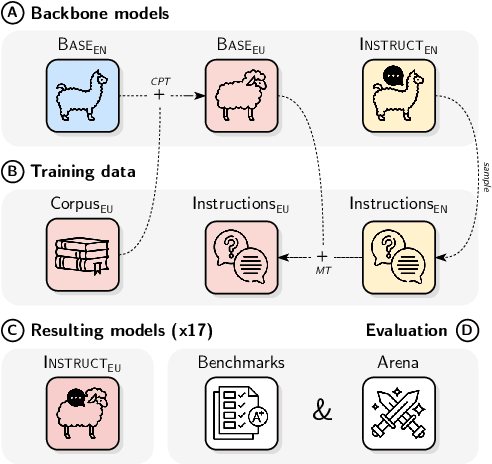
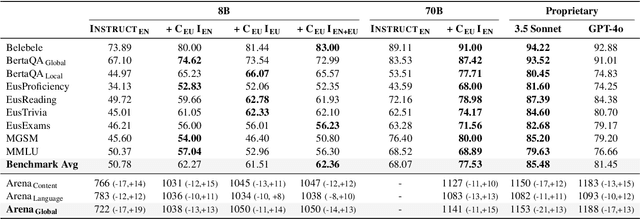
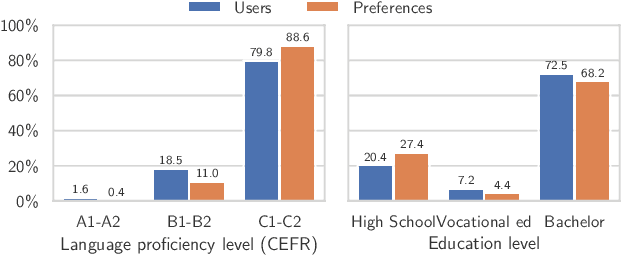

Instructing language models with user intent requires large instruction datasets, which are only available for a limited set of languages. In this paper, we explore alternatives to conventional instruction adaptation pipelines in low-resource scenarios. We assume a realistic scenario for low-resource languages, where only the following are available: corpora in the target language, existing open-weight multilingual base and instructed backbone LLMs, and synthetically generated instructions sampled from the instructed backbone. We present a comprehensive set of experiments for Basque that systematically study different combinations of these components evaluated on benchmarks and human preferences from 1,680 participants. Our conclusions show that target language corpora are essential, with synthetic instructions yielding robust models, and, most importantly, that using as backbone an instruction-tuned model outperforms using a base non-instructed model, and improved results when scaling up. Using Llama 3.1 instruct 70B as backbone our model comes near frontier models of much larger sizes for Basque, without using any Basque data apart from the 1.2B word corpora. We release code, models, instruction datasets, and human preferences to support full reproducibility in future research on low-resource language adaptation.
WiCkeD: A Simple Method to Make Multiple Choice Benchmarks More Challenging
Feb 25, 2025We introduce WiCkeD, a simple method to increase the complexity of existing multiple-choice benchmarks by randomly replacing a choice with "None of the above", a method often used in educational tests. We show that WiCkeD can be automatically applied to any existing benchmark, making it more challenging. We apply WiCkeD to 6 popular benchmarks and use it to evaluate 18 open-weight LLMs. The performance of the models drops 12.1 points on average with respect to the original versions of the datasets. When using chain-of-thought on 3 MMLU datasets, the performance drop for the WiCkeD variant is similar to the one observed when using the LLMs directly, showing that WiCkeD is also challenging for models with enhanced reasoning abilities. WiCkeD also uncovers that some models are more sensitive to the extra reasoning required, providing additional information with respect to the original benchmarks. We relase our code and data at https://github.com/ahmedselhady/wicked-benchmarks.
Data Contamination Report from the 2024 CONDA Shared Task
Jul 31, 2024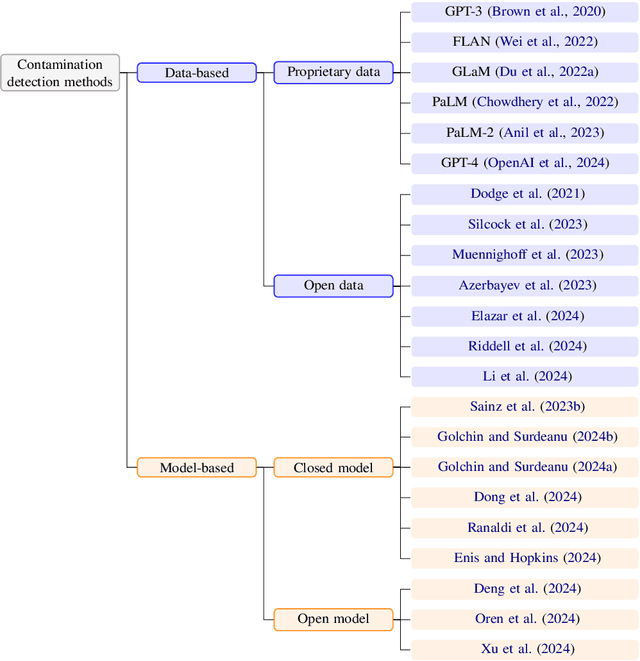
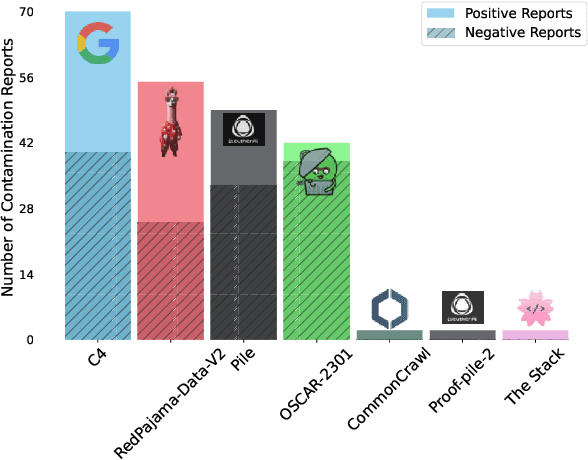
The 1st Workshop on Data Contamination (CONDA 2024) focuses on all relevant aspects of data contamination in natural language processing, where data contamination is understood as situations where evaluation data is included in pre-training corpora used to train large scale models, compromising evaluation results. The workshop fostered a shared task to collect evidence on data contamination in current available datasets and models. The goal of the shared task and associated database is to assist the community in understanding the extent of the problem and to assist researchers in avoiding reporting evaluation results on known contaminated resources. The shared task provides a structured, centralized public database for the collection of contamination evidence, open to contributions from the community via GitHub pool requests. This first compilation paper is based on 566 reported entries over 91 contaminated sources from a total of 23 contributors. The details of the individual contamination events are available in the platform. The platform continues to be online, open to contributions from the community.
BiVLC: Extending Vision-Language Compositionality Evaluation with Text-to-Image Retrieval
Jun 14, 2024Existing Vision-Language Compositionality (VLC) benchmarks like SugarCrepe are formulated as image-to-text retrieval problems, where, given an image, the models need to select between the correct textual description and a synthetic hard negative text. In this work we present the Bidirectional Vision-Language Compositionality (BiVLC) dataset. The novelty of BiVLC is to add a synthetic hard negative image generated from the synthetic text, resulting in two image-to-text retrieval examples (one for each image) and, more importantly, two text-to-image retrieval examples (one for each text). Human annotators filter out ill-formed examples ensuring the validity of the benchmark. The experiments on BiVLC uncover a weakness of current multimodal models, as they perform poorly in the text-to-image direction. In fact, when considering both retrieval directions, the conclusions obtained in previous works change significantly. In addition to the benchmark, we show that a contrastive model trained using synthetic images and texts improves the state of the art in SugarCrepe and in BiVLC for both retrieval directions. The gap to human performance in BiVLC confirms that Vision-Language Compositionality is still a challenging problem. BiVLC and code are available at https://imirandam.github.io/BiVLC_project_page.
Event Extraction in Basque: Typologically motivated Cross-Lingual Transfer-Learning Analysis
Apr 09, 2024Cross-lingual transfer-learning is widely used in Event Extraction for low-resource languages and involves a Multilingual Language Model that is trained in a source language and applied to the target language. This paper studies whether the typological similarity between source and target languages impacts the performance of cross-lingual transfer, an under-explored topic. We first focus on Basque as the target language, which is an ideal target language because it is typologically different from surrounding languages. Our experiments on three Event Extraction tasks show that the shared linguistic characteristic between source and target languages does have an impact on transfer quality. Further analysis of 72 language pairs reveals that for tasks that involve token classification such as entity and event trigger identification, common writing script and morphological features produce higher quality cross-lingual transfer. In contrast, for tasks involving structural prediction like argument extraction, common word order is the most relevant feature. In addition, we show that when increasing the training size, not all the languages scale in the same way in the cross-lingual setting. To perform the experiments we introduce EusIE, an event extraction dataset for Basque, which follows the Multilingual Event Extraction dataset (MEE). The dataset and code are publicly available.
Latxa: An Open Language Model and Evaluation Suite for Basque
Mar 29, 2024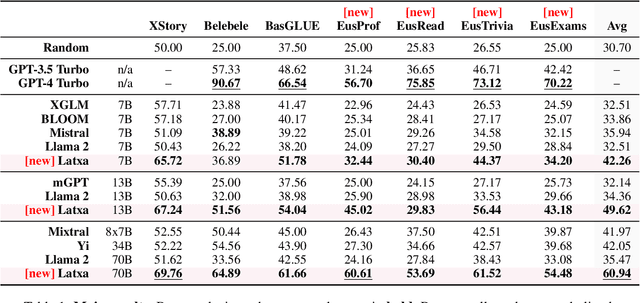
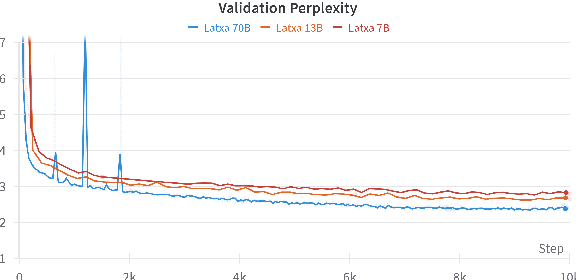
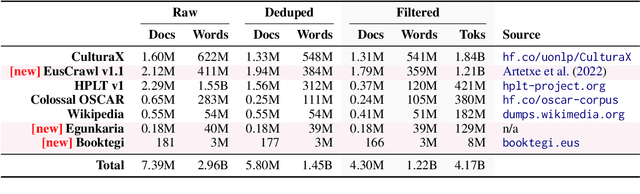
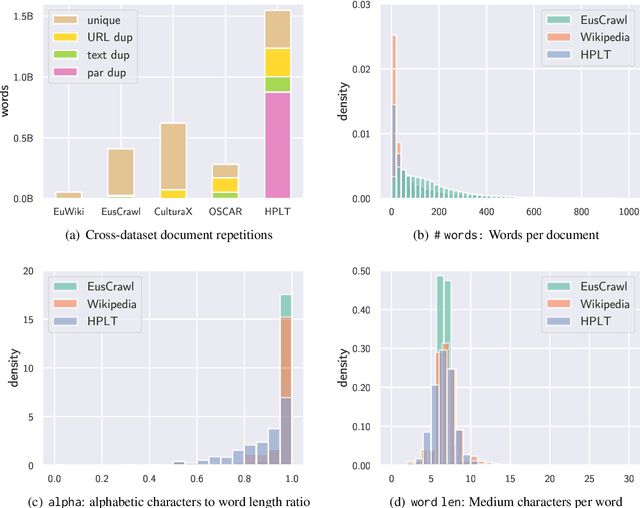
We introduce Latxa, a family of large language models for Basque ranging from 7 to 70 billion parameters. Latxa is based on Llama 2, which we continue pretraining on a new Basque corpus comprising 4.3M documents and 4.2B tokens. Addressing the scarcity of high-quality benchmarks for Basque, we further introduce 4 multiple choice evaluation datasets: EusProficiency, comprising 5,169 questions from official language proficiency exams; EusReading, comprising 352 reading comprehension questions; EusTrivia, comprising 1,715 trivia questions from 5 knowledge areas; and EusExams, comprising 16,774 questions from public examinations. In our extensive evaluation, Latxa outperforms all previous open models we compare to by a large margin. In addition, it is competitive with GPT-4 Turbo in language proficiency and understanding, despite lagging behind in reading comprehension and knowledge-intensive tasks. Both the Latxa family of models, as well as our new pretraining corpora and evaluation datasets, are publicly available under open licenses at https://github.com/hitz-zentroa/latxa. Our suite enables reproducible research on methods to build LLMs for low-resource languages.
Grounding Spatial Relations in Text-Only Language Models
Mar 20, 2024



This paper shows that text-only Language Models (LM) can learn to ground spatial relations like "left of" or "below" if they are provided with explicit location information of objects and they are properly trained to leverage those locations. We perform experiments on a verbalized version of the Visual Spatial Reasoning (VSR) dataset, where images are coupled with textual statements which contain real or fake spatial relations between two objects of the image. We verbalize the images using an off-the-shelf object detector, adding location tokens to every object label to represent their bounding boxes in textual form. Given the small size of VSR, we do not observe any improvement when using locations, but pretraining the LM over a synthetic dataset automatically derived by us improves results significantly when using location tokens. We thus show that locations allow LMs to ground spatial relations, with our text-only LMs outperforming Vision-and-Language Models and setting the new state-of-the-art for the VSR dataset. Our analysis show that our text-only LMs can generalize beyond the relations seen in the synthetic dataset to some extent, learning also more useful information than that encoded in the spatial rules we used to create the synthetic dataset itself.