 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState over Tokens: Characterizing the Role of Reasoning Tokens
Dec 14, 2025Large Language Models (LLMs) can generate reasoning tokens before their final answer to boost performance on complex tasks. While these sequences seem like human thought processes, empirical evidence reveals that they are not a faithful explanation of the model's actual reasoning process. To address this gap between appearance and function, we introduce the State over Tokens (SoT) conceptual framework. SoT reframes reasoning tokens not as a linguistic narrative, but as an externalized computational state -- the sole persistent information carrier across the model's stateless generation cycles. This explains how the tokens can drive correct reasoning without being a faithful explanation when read as text and surfaces previously overlooked research questions on these tokens. We argue that to truly understand the process that LLMs do, research must move beyond reading the reasoning tokens as text and focus on decoding them as state.
AstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite
Oct 24, 2025AI agents hold the potential to revolutionize scientific productivity by automating literature reviews, replicating experiments, analyzing data, and even proposing new directions of inquiry; indeed, there are now many such agents, ranging from general-purpose "deep research" systems to specialized science-specific agents, such as AI Scientist and AIGS. Rigorous evaluation of these agents is critical for progress. Yet existing benchmarks fall short on several fronts: they (1) fail to provide holistic, product-informed measures of real-world use cases such as science research; (2) lack reproducible agent tools necessary for a controlled comparison of core agentic capabilities; (3) do not account for confounding variables such as model cost and tool access; (4) do not provide standardized interfaces for quick agent prototyping and evaluation; and (5) lack comprehensive baseline agents necessary to identify true advances. In response, we define principles and tooling for more rigorously benchmarking agents. Using these, we present AstaBench, a suite that provides the first holistic measure of agentic ability to perform scientific research, comprising 2400+ problems spanning the entire scientific discovery process and multiple scientific domains, and including many problems inspired by actual user requests to deployed Asta agents. Our suite comes with the first scientific research environment with production-grade search tools that enable controlled, reproducible evaluation, better accounting for confounders. Alongside, we provide a comprehensive suite of nine science-optimized classes of Asta agents and numerous baselines. Our extensive evaluation of 57 agents across 22 agent classes reveals several interesting findings, most importantly that despite meaningful progress on certain individual aspects, AI remains far from solving the challenge of science research assistance.
Efficient Decoding Methods for Language Models on Encrypted Data
Sep 10, 2025Large language models (LLMs) power modern AI applications, but processing sensitive data on untrusted servers raises privacy concerns. Homomorphic encryption (HE) enables computation on encrypted data for secure inference. However, neural text generation requires decoding methods like argmax and sampling, which are non-polynomial and thus computationally expensive under encryption, creating a significant performance bottleneck. We introduce cutmax, an HE-friendly argmax algorithm that reduces ciphertext operations compared to prior methods, enabling practical greedy decoding under encryption. We also propose the first HE-compatible nucleus (top-p) sampling method, leveraging cutmax for efficient stochastic decoding with provable privacy guarantees. Both techniques are polynomial, supporting efficient inference in privacy-preserving settings. Moreover, their differentiability facilitates gradient-based sequence-level optimization as a polynomial alternative to straight-through estimators. We further provide strong theoretical guarantees for cutmax, proving it converges globally to a unique two-level fixed point, independent of the input values beyond the identity of the maximizer, which explains its rapid convergence in just a few iterations. Evaluations on realistic LLM outputs show latency reductions of 24x-35x over baselines, advancing secure text generation.
NER Retriever: Zero-Shot Named Entity Retrieval with Type-Aware Embeddings
Sep 04, 2025We present NER Retriever, a zero-shot retrieval framework for ad-hoc Named Entity Retrieval, a variant of Named Entity Recognition (NER), where the types of interest are not provided in advance, and a user-defined type description is used to retrieve documents mentioning entities of that type. Instead of relying on fixed schemas or fine-tuned models, our method builds on internal representations of large language models (LLMs) to embed both entity mentions and user-provided open-ended type descriptions into a shared semantic space. We show that internal representations, specifically the value vectors from mid-layer transformer blocks, encode fine-grained type information more effectively than commonly used top-layer embeddings. To refine these representations, we train a lightweight contrastive projection network that aligns type-compatible entities while separating unrelated types. The resulting entity embeddings are compact, type-aware, and well-suited for nearest-neighbor search. Evaluated on three benchmarks, NER Retriever significantly outperforms both lexical and dense sentence-level retrieval baselines. Our findings provide empirical support for representation selection within LLMs and demonstrate a practical solution for scalable, schema-free entity retrieval. The NER Retriever Codebase is publicly available at https://github.com/ShacharOr100/ner_retriever
Diversity Over Quantity: A Lesson From Few Shot Relation Classification
Dec 06, 2024In few-shot relation classification (FSRC), models must generalize to novel relations with only a few labeled examples. While much of the recent progress in NLP has focused on scaling data size, we argue that diversity in relation types is more crucial for FSRC performance. In this work, we demonstrate that training on a diverse set of relations significantly enhances a model's ability to generalize to unseen relations, even when the overall dataset size remains fixed. We introduce REBEL-FS, a new FSRC benchmark that incorporates an order of magnitude more relation types than existing datasets. Through systematic experiments, we show that increasing the diversity of relation types in the training data leads to consistent gains in performance across various few-shot learning scenarios, including high-negative settings. Our findings challenge the common assumption that more data alone leads to better performance and suggest that targeted data curation focused on diversity can substantially reduce the need for large-scale datasets in FSRC.
GRADE: Quantifying Sample Diversity in Text-to-Image Models
Oct 29, 2024



Text-to-image (T2I) models are remarkable at generating realistic images based on textual descriptions. However, textual prompts are inherently underspecified: they do not specify all possible attributes of the required image. This raises two key questions: Do T2I models generate diverse outputs on underspecified prompts? How can we automatically measure diversity? We propose GRADE: Granular Attribute Diversity Evaluation, an automatic method for quantifying sample diversity. GRADE leverages the world knowledge embedded in large language models and visual question-answering systems to identify relevant concept-specific axes of diversity (e.g., ``shape'' and ``color'' for the concept ``cookie''). It then estimates frequency distributions of concepts and their attributes and quantifies diversity using (normalized) entropy. GRADE achieves over 90% human agreement while exhibiting weak correlation to commonly used diversity metrics. We use GRADE to measure the overall diversity of 12 T2I models using 400 concept-attribute pairs, revealing that all models display limited variation. Further, we find that these models often exhibit default behaviors, a phenomenon where the model consistently generates concepts with the same attributes (e.g., 98% of the cookies are round). Finally, we demonstrate that a key reason for low diversity is due to underspecified captions in training data. Our work proposes a modern, semantically-driven approach to measure sample diversity and highlights the stunning homogeneity in outputs by T2I models.
Data-driven Coreference-based Ontology Building
Oct 22, 2024While coreference resolution is traditionally used as a component in individual document understanding, in this work we take a more global view and explore what can we learn about a domain from the set of all document-level coreference relations that are present in a large corpus. We derive coreference chains from a corpus of 30 million biomedical abstracts and construct a graph based on the string phrases within these chains, establishing connections between phrases if they co-occur within the same coreference chain. We then use the graph structure and the betweeness centrality measure to distinguish between edges denoting hierarchy, identity and noise, assign directionality to edges denoting hierarchy, and split nodes (strings) that correspond to multiple distinct concepts. The result is a rich, data-driven ontology over concepts in the biomedical domain, parts of which overlaps significantly with human-authored ontologies. We release the coreference chains and resulting ontology under a creative-commons license, along with the code.
Knowledge Navigator: LLM-guided Browsing Framework for Exploratory Search in Scientific Literature
Aug 28, 2024



The exponential growth of scientific literature necessitates advanced tools for effective knowledge exploration. We present Knowledge Navigator, a system designed to enhance exploratory search abilities by organizing and structuring the retrieved documents from broad topical queries into a navigable, two-level hierarchy of named and descriptive scientific topics and subtopics. This structured organization provides an overall view of the research themes in a domain, while also enabling iterative search and deeper knowledge discovery within specific subtopics by allowing users to refine their focus and retrieve additional relevant documents. Knowledge Navigator combines LLM capabilities with cluster-based methods to enable an effective browsing method. We demonstrate our approach's effectiveness through automatic and manual evaluations on two novel benchmarks, CLUSTREC-COVID and SCITOC. Our code, prompts, and benchmarks are made publicly available.
Data Contamination Report from the 2024 CONDA Shared Task
Jul 31, 2024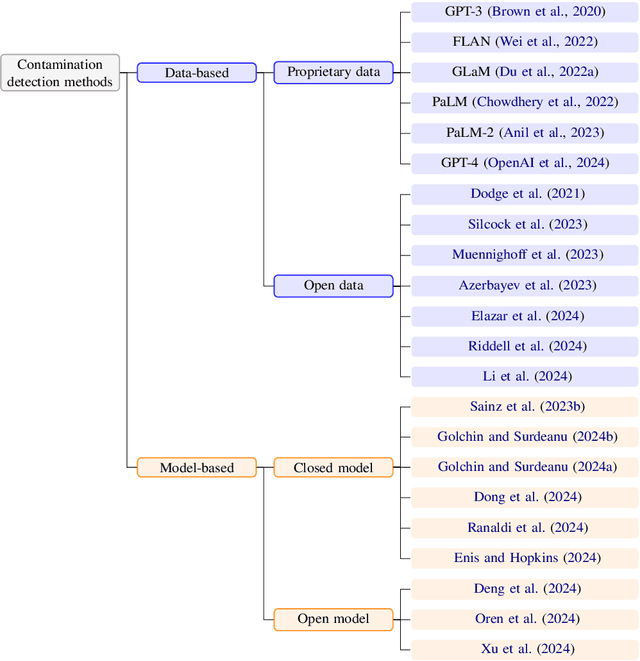
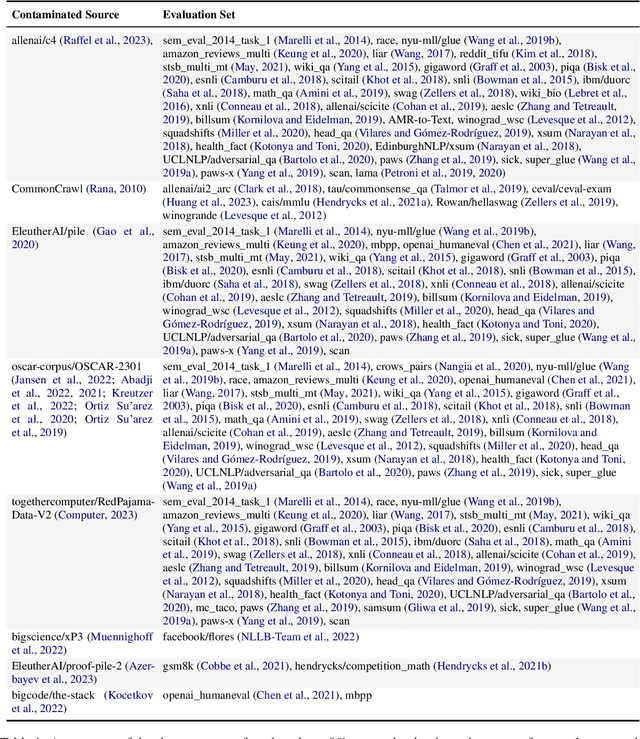
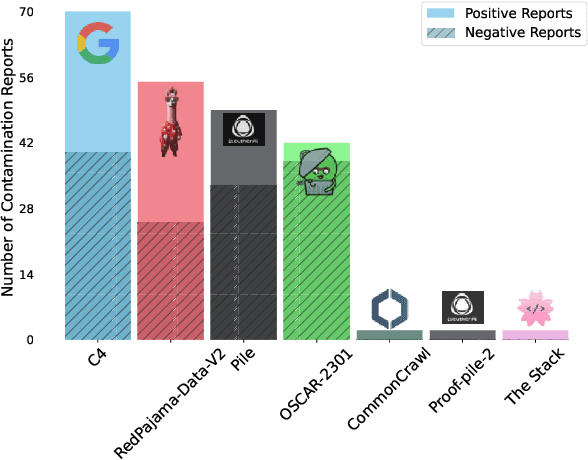
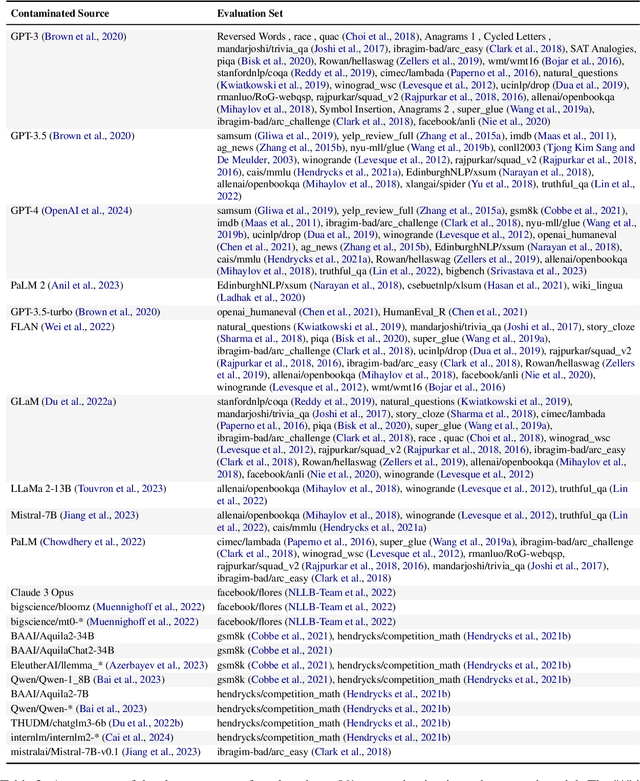
The 1st Workshop on Data Contamination (CONDA 2024) focuses on all relevant aspects of data contamination in natural language processing, where data contamination is understood as situations where evaluation data is included in pre-training corpora used to train large scale models, compromising evaluation results. The workshop fostered a shared task to collect evidence on data contamination in current available datasets and models. The goal of the shared task and associated database is to assist the community in understanding the extent of the problem and to assist researchers in avoiding reporting evaluation results on known contaminated resources. The shared task provides a structured, centralized public database for the collection of contamination evidence, open to contributions from the community via GitHub pool requests. This first compilation paper is based on 566 reported entries over 91 contaminated sources from a total of 23 contributors. The details of the individual contamination events are available in the platform. The platform continues to be online, open to contributions from the community.
NoviCode: Generating Programs from Natural Language Utterances by Novices
Jul 16, 2024Current Text-to-Code models demonstrate impressive capabilities in generating executable code from natural language snippets. However, current studies focus on technical instructions and programmer-oriented language, and it is an open question whether these models can effectively translate natural language descriptions given by non-technical users and express complex goals, to an executable program that contains an intricate flow - composed of API access and control structures as loops, conditions, and sequences. To unlock the challenge of generating a complete program from a plain non-technical description we present NoviCode, a novel NL Programming task, which takes as input an API and a natural language description by a novice non-programmer and provides an executable program as output. To assess the efficacy of models on this task, we provide a novel benchmark accompanied by test suites wherein the generated program code is assessed not according to their form, but according to their functional execution. Our experiments show that, first, NoviCode is indeed a challenging task in the code synthesis domain, and that generating complex code from non-technical instructions goes beyond the current Text-to-Code paradigm. Second, we show that a novel approach wherein we align the NL utterances with the compositional hierarchical structure of the code, greatly enhances the performance of LLMs on this task, compared with the end-to-end Text-to-Code counterparts.